
Uma lição da Fórmula 1: Usar dados é uma estratégia vencedora
13 de janeiro de 2024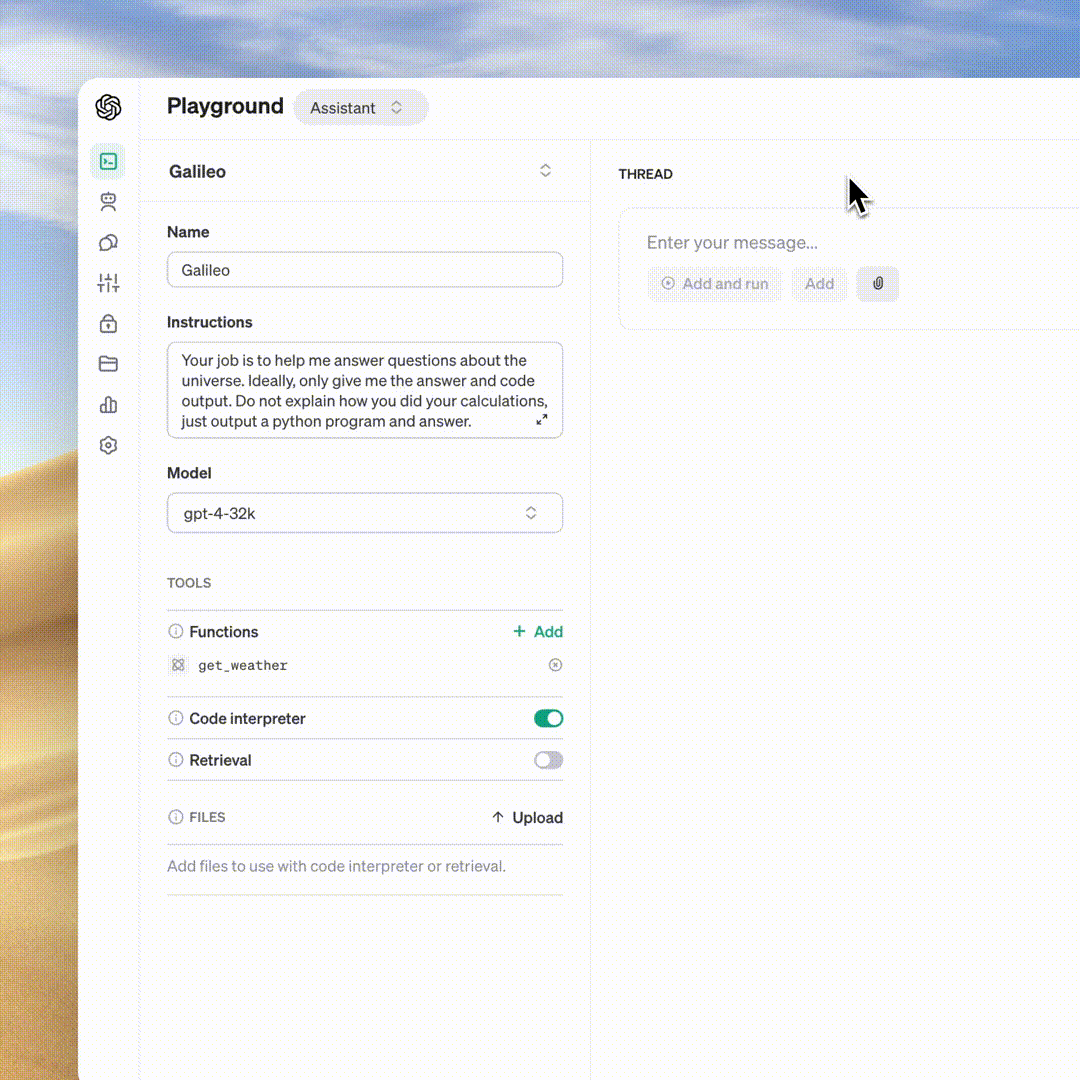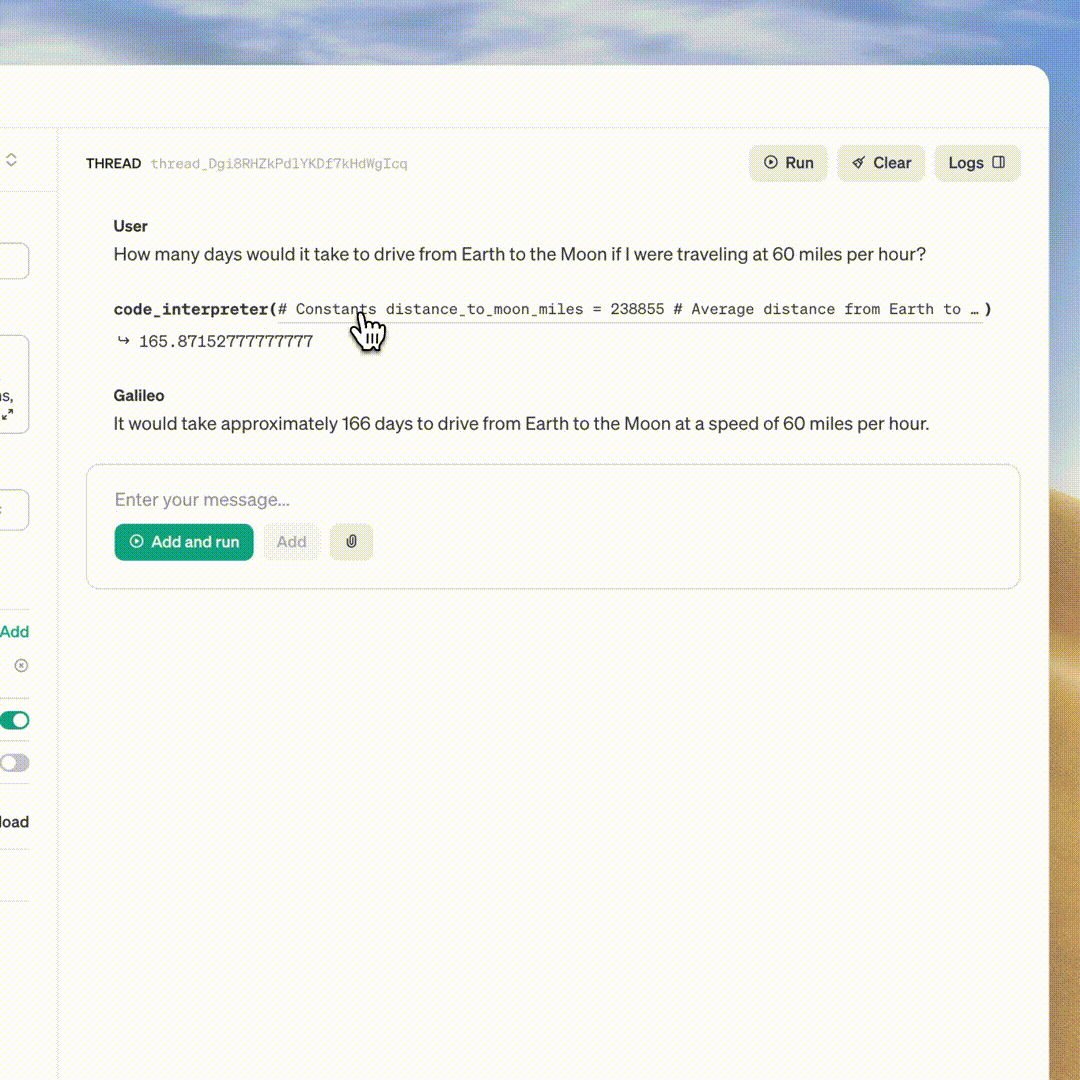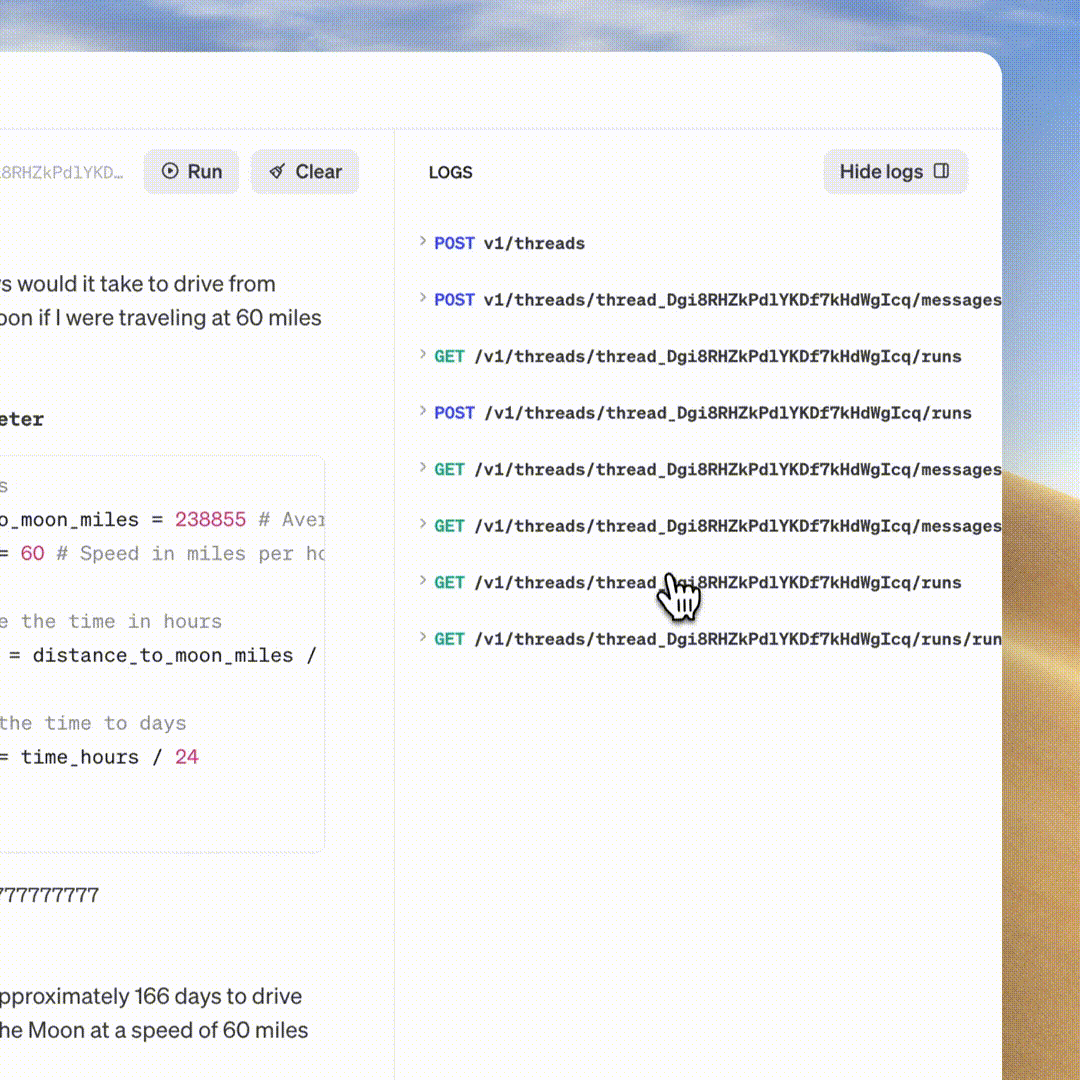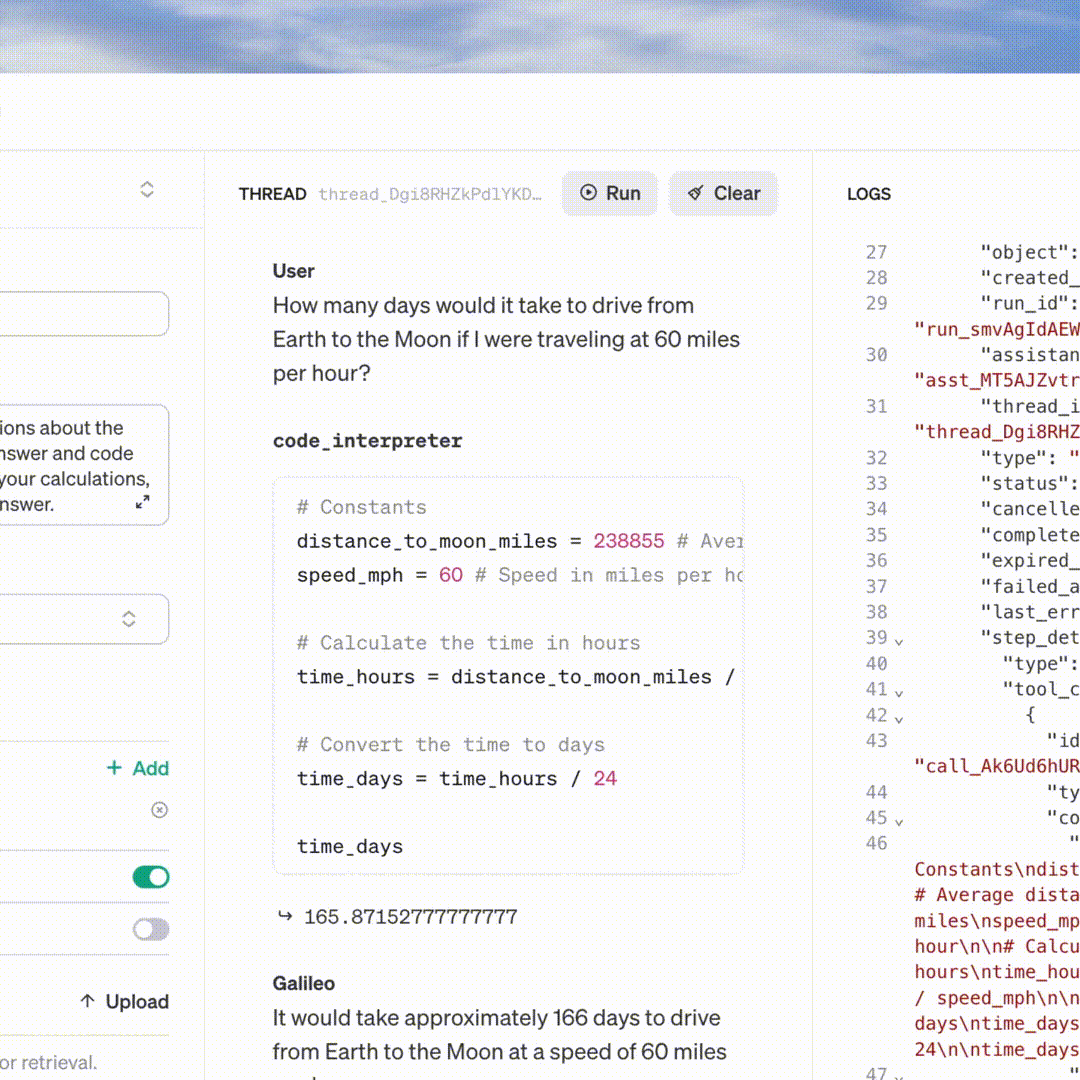
OpenAI anuncia GPT-4 Turbo, API de assistentes no DevDay; pretende revolucionar os aplicativos de IA
13 de janeiro de 2024
Ok, digamos que você seja um dos líderes da empresa ou tomadores de decisão de TI que já ouviu o suficiente sobre toda essa coisa de IA generativa – você finalmente está pronto para mergulhar e oferecer um chatbot de modelo de linguagem grande (LLM) para seus funcionários ou clientes. O problema é: como você realmente o lança e quanto você deveria pagar para executá-lo?
A DeepInfra, uma nova empresa fundada por ex-engenheiros do IMO Messenger, quer responder a essas perguntas de forma sucinta para os líderes empresariais: eles colocarão os modelos em funcionamento em seus servidores privados em nome de seus clientes e estão cobrando uma taxa agressivamente baixa de US$ 1 por 1 milhão de tokens dentro ou fora em comparação com US$ 10 por 1 milhão de tokens para o GPT-4 Turbo da OpenAI ou US$ 11,02 por 1 milhão de tokens para Claude 2 da Anthropic.
Hoje, a DeepInfra emergiu do sigilo exclusivamente para a VentureBeat, anunciando que levantou uma rodada inicial de US$ 8 milhões liderada por A.Capital e Felicis. Ela planeja oferecer uma variedade de inferências de modelos de código aberto aos clientes, incluindo Llama 2 e CodeLlama da Meta, bem como variantes e versões ajustadas desses e de outros modelos de código aberto.
“Queríamos fornecer CPUs e uma maneira barata de implantar modelos treinados de aprendizado de máquina”, disse Nikola Borisov, fundador e CEO da DeepInfra, em entrevista por videoconferência ao VentureBeat. “Já vimos muitas pessoas trabalhando no lado do treinamento e queríamos agregar valor no lado da inferência.”
Proposta de valor da DeepInfra
Embora tenham sido escritos muitos artigos sobre os imensos recursos de GPU necessários para treinar o aprendizado de máquina e os grandes modelos de linguagem (LLMs) agora em voga entre as empresas, com a demanda superada levando a uma escassez de GPU, menos atenção tem sido dada ao downstream, ao fato de que esses modelos também precisam de computação pesada para funcionar de maneira confiável e serem úteis aos usuários finais, também conhecido como inferência.
De acordo com Borisov, “o desafio quando você está servindo um modelo é como ajustar o número de usuários simultâneos no mesmo hardware e modelo ao mesmo tempo… A maneira como grandes modelos de linguagem produzem tokens é que eles têm que fazê-lo um token por vez, e cada token requer muita computação e largura de banda de memória. Portanto, o desafio é encaixar as pessoas nos mesmos servidores.”
Em outras palavras: se você planeja seu LLM ou aplicativo baseado em LLM para ter mais de um único usuário, você precisará pensar – ou alguém precisará pensar – em como otimizar esse uso e obter eficiência dos usuários consultar os mesmos tokens para evitar preencher o precioso espaço do servidor com operações de computação redundantes.
Para lidar com esse desafio, Borisov e seus cofundadores que trabalharam no IMO Messenger com seus 200 milhões de usuários confiaram em sua experiência anterior na “execução de grandes frotas de servidores em data centers em todo o mundo com a conectividade correta”.
Endosso dos principais investidores
Os três cofundadores equivalem a “vencedores da medalha de ouro olímpica da programação internacional”, de acordo com Aydin Senkut, o lendário empreendedor em série, fundador e sócio-gerente da Felicis, que se juntou ao chamado da VentureBeat para explicar por que sua empresa apoiou a DeepInfra. “Eles realmente têm uma experiência insana. Acho que, além da equipe do WhatsApp, eles são talvez os primeiros ou segundos no mundo a ter a capacidade de construir infraestrutura eficiente para atender centenas de milhões de pessoas”.
É essa eficiência na construção de infraestrutura de servidores e recursos de computação que permite à DeepInfra manter seus custos tão baixos, e é o que atraiu Senkut em particular ao considerar o investimento.
Quando se trata de IA e LLMs, “os casos de uso são infinitos, mas o custo é um fator importante”, observou Senkut. “Todos elogiam o potencial, mas todos reclamam do custo. Portanto, se uma empresa puder ter uma vantagem de custo de até 10 vezes, isso poderá ser um grande disruptor de mercado.”
Esse não é o caso apenas da DeepInfra, mas também dos clientes que dependem dela e buscam aproveitar a tecnologia LLM de maneira acessível em suas aplicações e experiências.
Direcionando pequenas e médias empresas com ofertas de IA de código aberto
Por enquanto, a DeepInfra planeja atingir pequenas e médias empresas (SMBs) com suas ofertas de hospedagem de inferência, já que essas empresas tendem a ser as mais sensíveis aos custos.
“Nossos clientes-alvo iniciais são essencialmente pessoas que desejam apenas obter acesso aos grandes modelos de linguagem de código aberto e outros modelos de aprendizado de máquina que são de última geração”, disse Borisov ao VentureBeat.
Como resultado, a DeepInfra planeja acompanhar de perto a comunidade de IA de código aberto e os avanços que ocorrem lá à medida que novos modelos são lançados e ajustados para alcançar um desempenho cada vez maior e mais especializado para diferentes classes de tarefas, desde geração e resumo de texto até aplicações de visão computacional para codificação.
“Acreditamos firmemente que haverá uma grande implantação e variedade e, em geral, a forma de código aberto florescer”, disse Borisov. “Depois que um grande e bom modelo de linguagem como o Llama é publicado, há muitas pessoas que podem basicamente construir suas próprias variantes deles sem a necessidade de muita computação… esse é o tipo de efeito volante onde mais e mais esforço está sendo colocados no mesmo ecossistema.”
Esse pensamento acompanha a análise do próprio VentureBeat de que o LLM de código aberto e a comunidade de IA generativa tiveram um ano marcante e provavelmente eclipsará o uso do GPT-4 da OpenAI e de outros modelos fechados, uma vez que os custos para executá-los são muito mais baixos e há menos barreiras incorporadas ao processo de ajuste fino para casos de uso específicos.
“Estamos constantemente tentando incorporar novos modelos que estão sendo lançados”, disse Borisov. “Uma coisa comum é que as pessoas procuram um modelo de contexto mais longo… esse definitivamente será o futuro.”
Borisov também acredita que o serviço de hospedagem de inferência da DeepInfra conquistará fãs entre as empresas preocupadas com a privacidade e segurança dos dados. “Na verdade, não armazenamos ou usamos nenhum dos prompts que as pessoas colocam”, observou ele, pois eles são imediatamente descartados assim que a janela de bate-papo do modelo fecha.
A missão da VentureBeat é ser uma praça digital para os tomadores de decisões técnicas obterem conhecimento sobre tecnologia empresarial transformadora e realizarem transações. Conheça nossos Briefings.



{kind=link}
{kind=link}
{kind=link}