
Por que o GraphQL precisa de uma abordagem de federação aberta
24 de janeiro de 2024
Código aberto na AWS: histórias da zona em re:Invent
24 de janeiro de 2024
Os espaços da Internet das Coisas (IoT) e da tecnologia de operações (OT) estão inundados de dados de séries temporais. Os sensores produzem dados com registro de data e hora em um ritmo constante e volumoso, e organizar todos esses dados pode ser um desafio. Mas você não quer coletar um monte de dados e deixá-los parados, ocupando espaço de armazenamento sem fornecer nenhum valor.
Portanto, no espírito de obter valor dos dados para IoT/OT, vamos ver como configurar um sensor usando InfluxDB e Amazon Web Services (AWS) para coletar o tipo de dados com carimbo de data/hora gerados por equipamentos industriais. Você pode adaptar, expandir e dimensionar os conceitos aqui para atender às necessidades de produção industrial completa. Aqui está o que usaremos no exemplo e por quê.
- InfluxoDB: Este banco de dados de série temporal acaba de lançar uma versão atualizada que supera as versões anteriores em diversas áreas importantes, como desempenho de consulta em dados de alta cardinalidade, compactação e ingestão de dados. Para este exemplo, o que é fundamental é que os produtos em nuvem do InfluxDB estão disponíveis na AWS. Ter tudo no mesmo lugar reduz o número de transferências de dados e problemas de latência de dados em muitos casos.
- Telégrafo: Telegraf é um agente de coleta de dados de código aberto baseado em plugin. Leve e escrito em Go, você pode implantar instâncias do Telegraf em qualquer lugar. Com mais de 300 plugins disponíveis, o Telegraf pode coletar dados de qualquer fonte. Você também pode escrever plug-ins personalizados para coletar dados de qualquer fonte que ainda não tenha um plug-in.
- AWS: Amazon Web Services possui toda uma gama de ferramentas e serviços voltados para IoT. Podemos aproveitar alguns desses serviços para agilizar o processamento e análise de dados.
- M5stickC+: Este é um dispositivo IoT simples que pode detectar uma série de medições, incluindo posição, métricas de aceleração, métricas de giroscópio, umidade, temperatura e pressão. Este dispositivo fornece múltiplos fluxos de dados, semelhantes aos que os operadores industriais enfrentam com equipamentos de fabricação.
![]()
InfluxData é o criador do InfluxDB, a plataforma líder de série temporal usada para coletar, armazenar e analisar todos os dados de série temporal em qualquer escala. Os desenvolvedores podem consultar e analisar seus dados com registro de data e hora em tempo real para descobrir, interpretar e compartilhar novos insights para obter vantagem competitiva.
Saber mais
As últimas novidades da InfluxData
$(document).ready(function() { $.ajax({ método: ‘POST’, url: ‘/no-cache/sponsors-rss-block/’, headers: { ‘Cache-Control’: ‘no- cache, no-store, must-revalidate’, ‘Pragma’: ‘no-cache’, ‘Expires’: ‘0’ }, dados: { patrocinadorSlug: ‘influxdata’, numItems: 3 }, sucesso: função (dados) { if (data.startsWith(‘ERROR’)) { console.log(data); $(‘.sponsor-note-rss’).hide(); } else { $(‘.sponsor-note-rss-items -influxdata’).html(dados); } } }); });
InfluxDB e AWS IoT em ação
O exemplo a seguir ilustra um dos muitos pipelines de dados possíveis que você pode dimensionar para atender às necessidades de uma variedade de equipamentos industriais. Isso pode incluir máquinas no chão de fábrica ou dispositivos distribuídos em campo. Vamos começar com uma visão geral rápida; então mergulharemos nos detalhes.
O fluxo de dados básico é:
Dispositivo → AWS IoT Core → MQTT (regras/roteamento) → Kinesis → Telegraf → InfluxDB → Visualização
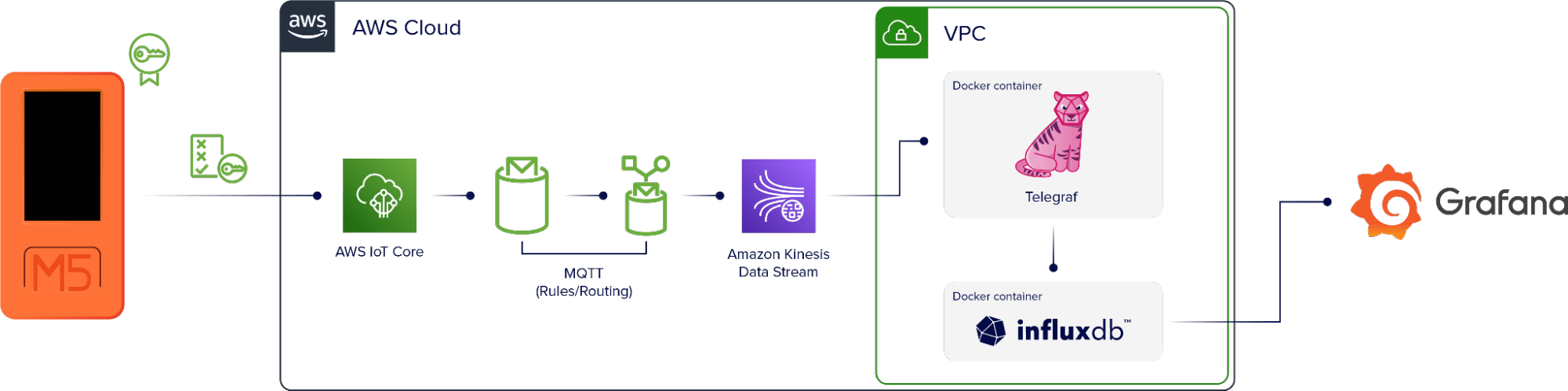
O dispositivo M5stickC+ está configurado para autenticar diretamente com AWS. Os dados chegam ao AWS IoT Core, que é um serviço da AWS que usa MQTT para adicionar os dados a um tópico específico do dispositivo. Depois, há uma regra que seleciona todos os dados que passam pelo tópico e os redireciona para a ferramenta de monitoramento, Amazon Kinesis.
Uma máquina virtual executada na AWS também executa dois contêineres Docker. Um contém uma instância do Telegraf e o outro uma instância do InfluxDB. O Telegraf coleta o fluxo de dados do Kinesis e grava-o no InfluxDB. O Telegraf também usa uma tabela DynamoDB como ponto de verificação nesta configuração, portanto, se o contêiner ou a instância ficar inativo, ele será reiniciado no ponto correto do fluxo de dados quando o aplicativo estiver ativo novamente.
Assim que os dados estiverem no InfluxDB, podemos usá-los para criar visualizações.
OK, esse é o pipeline de dados básico. Agora, como fazemos isso funcionar?
Firmware do dispositivo
A primeira etapa é criar uma conexão de dados do dispositivo M5 com a AWS. Para fazer isso, usamos o UI Flow, um editor de arrastar e soltar que faz parte da pilha M5. Confira os blocos na imagem abaixo para ter uma ideia do que o dispositivo está coletando e como essas coisas são mapeadas para nossa saída final.
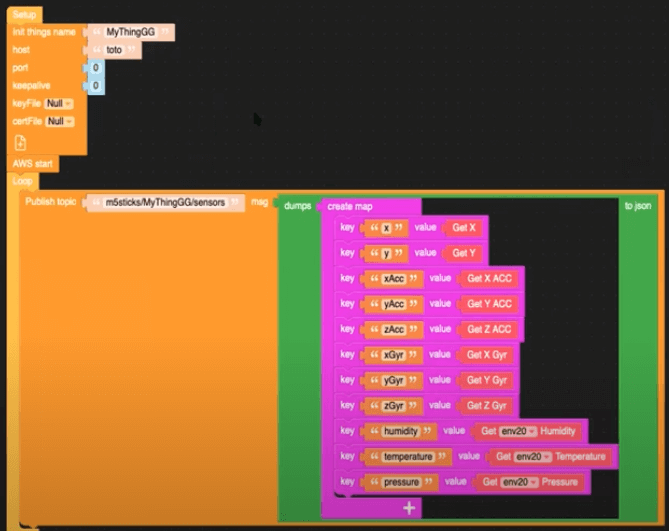
Podemos ver aqui que esses dados são publicados no tópico MQTT m5sticks/MyThingGG/sensors.
Regras principais do AWS IoT
Com a publicação dos dados do dispositivo em um corretor MQTT, em seguida, precisamos assinar esse tópico no AWS IoT Core. No campo de filtro de tópico, insira m5sticks/+/sensors para garantir que todos os dados do dispositivo acabem no tópico MQTT.
Em seguida, precisamos criar outra regra para garantir que os dados no tópico MQTT vão para o Kinesis. No IoT Core, você pode usar uma consulta SQL para fazer isso:
SELECT *, topic(2) as thing, 'sensors' as measurement, timestamp() as timestamp FROM 'm5sticks/+/sensors'
Num ambiente industrial, cada dispositivo deve ter um nome exclusivo. Então, para dimensionar esse pipeline de dados para acomodar vários dispositivos, usamos o +` curinga no tópico MQTT para garantir que todos os dados de todos os dispositivos acabem no local correto.
Esta consulta adiciona um carimbo de data/hora aos dados para que eles sigam o protocolo de linha, o modelo de dados do InfluxDB.
Política Telegráfica
Agora que os dados estão fluindo do dispositivo para o Kinesis, precisamos colocá-los no InfluxDB. Para fazer isso, usamos o Telegraf. O código abaixo é a política que determina como o Telegraf interage com o Kinesis. Ele permite que o Telegraf leia o fluxo do Kinesis e permite acesso de leitura e gravação ao DynamoDB para pontos de verificação.
{
"Version": "2012-10-17"
"Statement": (
{
"Sid": "AllowReadFromKinesis",
"Effect": "Allow",
"Action": (
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:DescribeStream"
),
"Resource": (
"arn:aws:kinesis:eu-west-3:xxxxxxxxx:stream/InfluxDBStream"
)
},
{
"Sid": "AllowReadAndWriteDynamoDB",
"Effect": "Allow",
"Action": (
"dynamodb:PutItem",
"dynamodb:GetItem"
),
"Resource": (
"arn:aws:kinesis:eu-west-3:xxxxxxxxx:table/influx-db-telegraf"
)
}
)
}
Configuração do Telegraf
A configuração do Telegraf a seguir usa rede de contêiner Docker, o plug-in Telegraf Kinesis Consumer para ler os dados do Kinesis e o plug-in de saída InfluxDB v2 para gravar esses dados no InfluxDB. Observe que os campos de string correspondem aos valores da IU do firmware do dispositivo.
(agent)
debug = true
((outputs.influxdb_v2))
## The URLs of the InfluxDB Cluster nodes.
##
## Multiple URLs can be specified for a single cluster, only ONE of the
## urls will be written to each interval.
## urls exp: http://127.0.0.1:8086
urls = ("http://influxdb:8086")
## Token for authentication.
token = "toto-token"
## Organization is the name of the organization you wish to write to; must exist.
organization = "aws"
## Destination bucket to write into.
bucket = "toto-bucket"
((inputs.kinesis_consumer))
## Amazon REGION of kinesis endpoint.
region = "eu-west-3"
## Amazon Credentials
## Credentials are loaded in the following order
## 1) Web identity provider credentials via STS if role_arn and web_identity_token_file are specified
## 2) Assumed credentials via STS if role_arn is specified
## 3) explicit credentials from 'access_key' and 'secret_key'
## 4) shared profile from 'profile'
## 5) environment variables
## 6) shared credentials file
## 7) EC2 Instance Profile
## Endpoint to make request against, the correct endpoint is automatically
## determined and this option should only be set if you wish to override the
## default.
## ex: endpoint_url = "http://localhost:8000"
# endpoint_url = ""
## Kinesis StreamName must exist prior to starting telegraf.
streamname = "InfluxDBStream"
## Shard iterator type (only 'TRIM_HORIZON' and 'LATEST' currently supported)
# shard_iterator_type = "TRIM_HORIZON"
## Max undelivered messages
## This plugin uses tracking metrics, which ensure messages are read to
## outputs before acknowledging them to the original broker to ensure data
## is not lost. This option sets the maximum messages to read from the
## broker that have not been written by an output.
##
## This value needs to be picked with awareness of the agent's
## metric_batch_size value as well. Setting max undelivered messages too high
## can result in a constant stream of data batches to the output. While
## setting it too low may never flush the broker's messages.
# max_undelivered_messages = 1000
## Data format to consume.
## Each data format has its own unique set of configuration options, read
## more about them here:
## https://github.com/influxdata/telegraf/blob/master/docs/DATA_FORMATS_INPUT.md
data_format = "json"
## Tag keys is an array of keys that should be added as tags.
tag_keys = (
"thing"
)
## String fields is an array of keys that should be added as string fields.
json_string_fields = (
"pressure",
"xGyr",
"yAcc",
"batteryPower",
"xAcc",
"temperature",
"zAcc",
"zGyr",
"y",
"x",
"yGry",
"humidity"
)
## Name key is the key used as the measurement name.
json_name_key = "measurement"
## Time key is the key containing the time that should be used to create the
## metric.
json_time_key "timestamp"
## Time format is the time layout that should be used to interpret the
## json_time_key. The time must be 'unix', 'unix_ms' or a time in the
## "reference_time".
## ex: json_time_format = "Mon Jan 2 15:04:05 -0700 MST 2006"
## json_time_format = "2006-01-02T15:04:05Z07:00"
## json_time_format = "unix"
## json_time_format = "unix_ms"
json_time_format = "unix_ms"
## Optional
## Configuration for a dynamodb checkpoint
(inputs.kinesis_consumer.checkpoint_dynamodb)
## unique name for this consumer
app_name = "default"
table_name = "influx-db-telegraf"
Composição do Docker
Este arquivo composto do Docker é carregado em uma instância EC2 usando SSH.
version: '3'
services:
influxdb:
image: influxdb:2.0.6
volumes:
# Mount for influxdb data directory and configuration
- influxdbv2:/root/.influxdbv2
ports:
- "8086:8086"
# Use the influx cli to set up an influxdb instance
influxdb_cli:
links:
- influxdb
image: influxdb:2.0.6
# Use these same configurations parameters in you telegraf configuration, mytelegraf.conf
# Wait for the influxd service in the influxdb has been fully bootstrapped before trying to set up an influxdb
restart: on-failure:10
depends_on:
- influxdb
telegraf:
image: telegraf:1.25-alpine
links:
- influxdb
volumes:
# Mount for telegraf config
- ./telegraf.conf:/etc/telegraf/telegraf.conf
depends_on:
- influxdb_cli
volumes:
influxdbv2:
Visualização
Depois que seus dados estiverem no InfluxDB, os usuários que executam o InfluxDB podem criar visualizações e painéis usando a ferramenta de sua preferência. InfluxDB oferece integração nativa com Grafana e suporta consultas SQL usando ferramentas compatíveis com Flight SQL.
Conclusão
Construir pipelines de dados confiáveis é um aspecto crítico das operações industriais. Esses dados fornecem informações importantes sobre o estado atual de máquinas e equipamentos e podem treinar modelos preditivos usados para melhorar as operações e a eficácia das máquinas. A combinação de tecnologias líderes como InfluxDB e AWS fornece as ferramentas necessárias para capturar, armazenar, analisar e visualizar esses dados críticos do processo.
O caso de uso descrito aqui é apenas uma maneira de construir um pipeline de dados. Você pode atualizá-lo, dimensioná-lo e alterá-lo para acomodar uma ampla variedade de operações industriais de IoT/OT ou criar algo totalmente personalizado usando a variedade de soluções de IoT disponíveis para InfluxDB e AWS.
A postagem Criando um pipeline de dados IoT usando InfluxDB e AWS apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}