Um dos problemas que vem à tona com o uso crescente do ChatGPT é a inclusão ocasional de informações obviamente incorretas nas respostas, que foram descritas com precisão como alucinações. Por que isso ocorre e pode ser controlado?
Quando estávamos analisando uma consulta simples da API OpenAI, nos deparamos com a variável temperatura. Além de poder estar entre 0 e 1, apenas observamos que controlava “a criatividade da resposta”. Aqui está uma visão um pouco técnica do que isso significa.
Antes de prosseguirmos, é melhor lembrarmos brevemente que quando uma mente de engenharia pensa em “temperatura”, ela não está pensando “está esquentando aqui”, mas sim “aumento de entropia”. Considere o movimento extra das moléculas excitadas como uma gama maior de possibilidades (aleatórias).
A temperatura é não específico para OpenAI; pertence mais às ideias de processamento de linguagem natural (PNL). Embora os grandes modelos de linguagem (LLMs) representem o pico atual na geração de texto para um determinado contexto, essa capacidade básica de descobrir a próxima palavra está disponível com a previsão de texto no seu telefone há décadas.
Para entender de onde vêm as variações, vamos considerar como um modelo simplista aprende com exemplos.
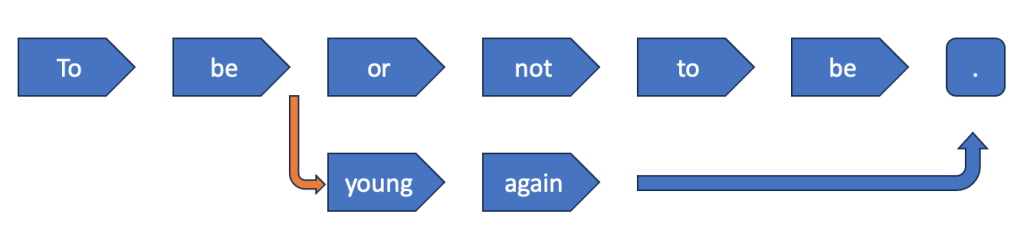
Considere um modelo ingerindo sua primeira frase:
Ser ou não ser.
Ele entende a frase como uma sequência de palavras ordenadas, com ponto final indicando o final. Se esta for a única frase que conhece, não estará fazendo nenhuma previsão decente. E se você digitar “To be…”, isso apenas sugerirá a famosa frase de Hamlet.
Então adicionaremos mais uma linha ao modelo:
Para ser jovem novamente.
Combinando os dois, temos a possibilidade de produzir qualquer linha após o primeiro “To be”. Reconhecemos o ponto final como final da frase, podendo ser compartilhado por qualquer uma das opções, assim como as duas primeiras palavras.
As opções que podem ser produzidas a partir de um modelo baseado nas duas entradas anteriores.
Portanto, a linha laranja representa uma variação. Nosso modelo agora entende duas linhas.
Devemos notar que tratei cada palavra como um símbolo ou unidade a ser consumida, incluindo o ponto final. Mas as palavras não são entidades realmente distintas; sabemos que as palavras “fazer” e “feito” são a mesma palavra em tempos diferentes, ou que “navios” é o plural de “navio”. Também sabemos que a palavra “desengatar” é a palavra “engajar” com um prefixo no início.
Em suma, as próprias palavras parecem ser feitas de símbolos. Dentro dos modelos baseados no idioma inglês, existem cerca de 1,3 tokens por palavra. E isso será diferente para diferentes idiomas. A outra razão pela qual precisamos conhecer os tokens é que é assim que os modelos GPT cobram de você. Portanto, o preço por token é algo que você precisa ter em mente.
Quais são as hipóteses?
O treinamento é o processo onde os tokens e o contexto são aprendidos, até que haja múltiplas opções com probabilidade variável de ocorrer. Se assumirmos que o nosso modelo simples acima inclui centenas de exemplos de texto, saberemos que “Para ser franco” e “Continuar” são muito mais prováveis de ocorrer do que o solilóquio de 400 anos de Shakespeare.
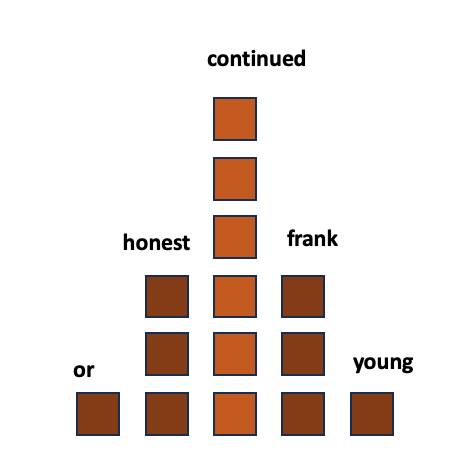
Se fizéssemos uma espécie de curva em forma de sino em torno da palavra seguinte depois de “To be…”, naturalmente esperaríamos que algumas fossem muito prováveis e outras muito menos prováveis. No diagrama abaixo, um bloco representa um grande número de exemplos. Portanto, possíveis palavras que não aparecem como opções têm poucas referências de exemplo.
Vamos considerar um possível top cinco:
Um bloco de opções possíveis com base na entrada “To be…”
Se somarmos todos os blocos, podemos expressar de forma bastante simples a chance de qualquer palavra ser selecionada aleatoriamente. Portanto, “continuação” seria seis chances em 14, ou 42% de probabilidade de aparecer a seguir, enquanto “ou” seria apenas cerca de uma em 14, ou 7%. Mas já é evidente que algumas palavras têm muito menos probabilidade de aparecer.
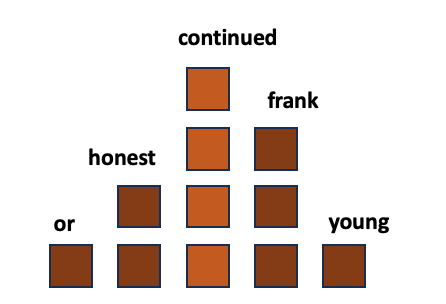
E se achatássemos a curva? Isto claramente ainda expressaria as respostas prováveis como maior probabilidade, mas permite que as opções menos comuns tenham uma melhor chance de serem selecionadas:
Uma curva mais plana mostra as opções possíveis para seguir a entrada “To be…”
Isso alterou a probabilidade de “continuação” para 36% e passou de “ou” para 9%. Portanto, as chances diminuíram em torno da escolha de uma variedade maior de palavras.
Isto é efetivamente o que o aumento da temperatura faz. Ele achata a curva, dando um impulso às respostas menos prováveis. Se a temperatura for zero, o modelo poderá escolher apenas o token de maior probabilidade. Apenas como um lembrete, ao chamar a API OpenAI diretamente, você pode inserir a faixa de temperatura diretamente:
“mensagens”: ({“role”: “usuário”, “content”: “O que é TheNewStack?”}),
“temperatura”: 0,7
}’
Como podemos estar procurando uma resposta interessante e original, um valor de temperatura próximo de 1 faz sentido.
Agora você pode muito bem dizer: “Mas certamente isso aumenta as chances de o modelo responder com coisas que não são verdadeiras?” Deparamo-nos então com a questão de adequar a tarefa à temperatura apropriada. Isto é feito diferenciando entre resultados “criativos” e resultados “factuais”. Se utilizarmos uma temperatura demasiado elevada com material factual, é provável que produzamos as temidas alucinações.
A temperatura oculta a origem das respostas do chatbot
A grande missão do ChatGPT é fazer você pensar que a IA “pensou” em uma resposta. Não aconteceu. Ele está fazendo uma versão muito mais sofisticada do que foi dito acima, com milhões de tokens ingeridos, mas ainda é inteiramente guiado por LLMs pré-construídos. É por isso que pode parecer autoritário, mas ser um absurdo absoluto.
Porém, como vemos no uso diário, o ChatGPT funciona muito bem na maioria dos casos. Isso ocorre porque para cada pergunta que você possa ter, alguém a respondeu, direta ou inadvertidamente, em algum lugar da internet. A verdadeira tarefa do ChatGPT é compreender o contexto da pergunta e refletir isso na resposta.
Quando leio um boletim meteorológico no jornal local, não estou “roubando-o” se mais tarde usar essa informação para responder a um amigo que se pergunta se amanhã fará sol. Os jornais são (ou foram) concebidos como fontes válidas de informação. Mas é evidente que se eu retirar grandes partes do texto de um relatório de peritos e reivindicá-lo como meu, isso poderá ser uma fraude.
Haverá uma pressão legal crescente para que os modelos não deixem escapar respostas que tornem absolutamente óbvio de onde o material de origem foi retirado. E é por isso que é provável que as alucinações permaneçam, já que a temperatura é usada para variar as respostas e ocultar a sua origem. Estranhamente, o mesmo princípio foi usado inicialmente para derrotar a detecção de spam – ao adicionar erros ao e-mail de spam, inicialmente foi difícil colocá-lo na lista negra. O Gmail supera isso pelo seu tamanho e capacidade de compreender padrões de distribuição.
No geral, reconhecemos os LLMs como socialmente positivos. Eventualmente, a lei será formalizada em torno do que fazer e do que não fazer no processo de treinamento. Mas até lá, haverá muitas oportunidades para a temperatura subir devido à apropriação indevida de conteúdo de outros criadores por LLMs.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
David é desenvolvedor de software profissional baseado em Londres na Oracle Corp. e British Telecom, além de um consultor que auxilia as equipes a trabalhar de forma mais ágil. Ele escreveu um livro sobre UI design e tem escrito artigos técnicos desde então….
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.








{kind=link}
{kind=link}
{kind=link}