A recente introdução do recurso de recuperação OpenAI Assistants gerou discussões significativas na comunidade de IA. Esse recurso integrado incorpora os recursos de geração aumentada de recuperação (RAG) para resposta a perguntas, permitindo que os modelos de linguagem GPT aproveitem conhecimento adicional para gerar respostas mais precisas e relevantes. Esta postagem do Zilliz explora as restrições da recuperação RAG integrada do OpenAI e discute situações em que a criação de uma solução de recuperação personalizada pode ser benéfica.
Vamos comparar o desempenho do RAG da OpenAI com um RAG personalizado construído em um banco de dados vetorial como o Milvus. Avaliaremos os pontos fortes, fracos e nuances de cada abordagem e responderemos à pergunta crucial: Qual é a melhor?
O que é geração aumentada de recuperação?
Antes de avaliarmos o RAG integrado do OpenAI versus os sistemas RAG personalizados, vamos começar entendendo o que é RAG.
RAG é uma estrutura de IA que recupera fatos de uma base de conhecimento externa para garantir que grandes modelos de linguagem (LLMs) sejam baseados em informações mais precisas e atualizadas. Um sistema RAG típico compreende um LLM, um banco de dados vetorial como Milvus e alguns prompts como código.
Ferramenta de avaliação RAG: Ragas
Avaliar o desempenho do RAG é complexo. Precisamos de uma ferramenta de avaliação RAG justa e objetiva para avaliar múltiplas métricas num conjunto de dados adequado, garantindo resultados reproduzíveis.
Ragas é uma estrutura de código aberto dedicada a avaliar o desempenho de sistemas RAG. Ele fornece uma série de métricas de pontuação que medem diferentes aspectos de um sistema RAG para oferecer uma avaliação abrangente e multiângulo da qualidade das aplicações RAG.
Usaremos fidelidade, relevância da resposta, precisão do contexto, similaridade e correção da resposta como métricas primárias para avaliar o OpenAI RAG e nossos sistemas RAG personalizados.
Fidelidade: Avaliar a precisão factual da resposta gerada no contexto determinado.
Relevância da resposta: Avaliar a relevância da resposta gerada para a pergunta.
Precisão do contexto: Analisar a relação sinal-ruído do contexto recuperado e classificar itens relevantes para a verdade básica dentro dos contextos.
Correção da resposta: Avaliar a precisão da resposta gerada em comparação com a verdade básica.
Semelhança de resposta: Avaliando a semelhança semântica entre a resposta gerada e a verdade básica.
Revise a documentação do Ragas para obter informações mais detalhadas sobre Ragas e todas as métricas.
Conjunto de dados de avaliação RAG: FiQA
Selecionamos o conjunto de dados de Mineração de Opinião Financeira e Resposta a Perguntas (FiQA) para nossa avaliação. Este conjunto de dados possui diversas características que o tornam ideal para nossa avaliação, incluindo:
Ele contém conhecimento financeiro altamente especializado que provavelmente não estará presente nos dados de treinamento dos modelos GPT.
Ele foi inicialmente projetado para avaliar as capacidades de recuperação de informações e, portanto, fornece fragmentos de conhecimento bem anotados que servem como respostas padrão (verdade básica).
Ragas e sua comunidade reconheceram amplamente o FiQA como um conjunto de dados de teste introdutório padrão.
Configurando os sistemas RAG
Agora, vamos construir os dois sistemas RAG para comparação: um RAG OpenAI e um RAG personalizado construído no banco de dados vetorial Milvus.
Configurando OpenAI RAG
Construiremos um sistema RAG usando OpenAI Assistants seguindo a documentação oficial da OpenAI, incluindo a construção dos Assistants, upload do conhecimento externo, recuperação de informações contextuais e geração de respostas. Todas as outras configurações permanecerão no padrão.
Configurando um RAG personalizado usando Milvus
Devemos configurar manualmente o sistema RAG customizado usando o banco de dados vetorial Milvus para armazenar o conhecimento externo. Nós usaremos BAAI/bge-base-en do HuggingFace como modelo de incorporação, com vários componentes LangChain para importação de documentos e construção de agentes.
Para obter informações detalhadas, consulte este guia passo a passo.
Comparação de configuração
Resumimos os detalhes de configuração dos dois sistemas RAG na tabela abaixo. Para obter mais informações, consulte nosso código de implementação.
Comparação de configuração de OpenAI RAG e RAG personalizado
Conforme mostrado na tabela acima, ambos os sistemas RAG usam gpt-4-1106-preview como o modelo LLM. O RAG customizado usa Milvus como banco de dados vetorial. No entanto, o OpenAI RAG não divulga seu banco de dados vetorial integrado ou outros parâmetros de configuração.
Resultados e análises da avaliação
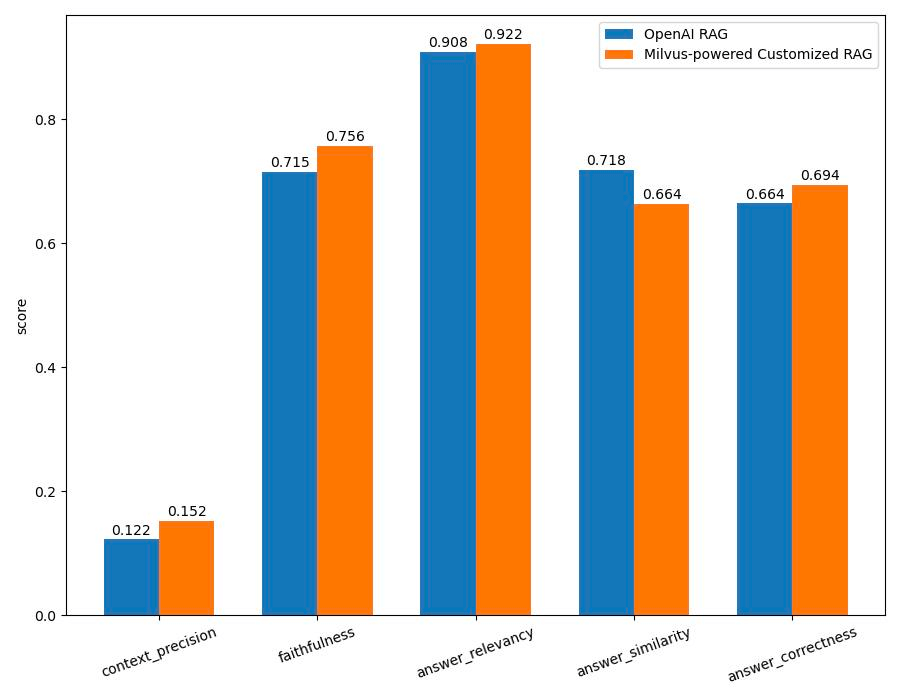
Usando Ragas, pontuamos ambos os sistemas RAG em múltiplas métricas, incluindo precisão de contexto, fidelidade, relevância de resposta, similaridade e correção. O gráfico abaixo mostra as pontuações experimentais que obtivemos de Ragas.
OpenAI RAG vs. RAG personalizado em métricas Ragas
Embora o sistema OpenAI RAG tenha superado ligeiramente o sistema RAG personalizado baseado em Milvus em termos de similaridade de respostas, ele ficou para trás em outras métricas cruciais, incluindo precisão de contexto, fidelidade, relevância e correção de respostas.
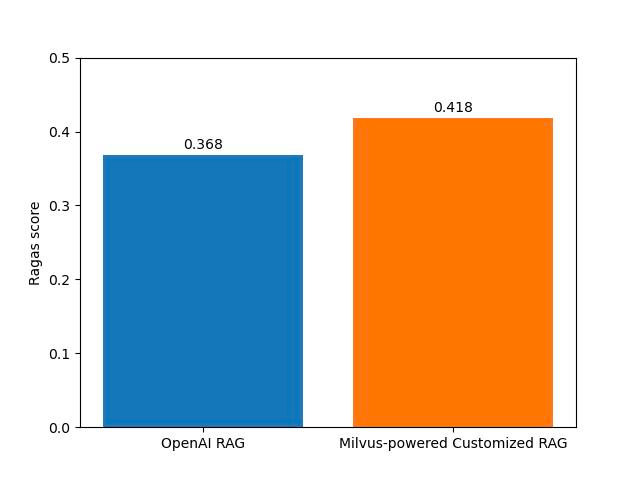
Ragas também nos permite comparar dois sistemas RAG usando Ragas Scores, um valor médio gerado pelo cálculo da média harmônica de várias métricas. A média harmônica é usada para penalizar itens com pontuação baixa. Quanto mais altas forem as pontuações Ragas, melhor será o desempenho geral de um sistema RAG. O gráfico abaixo mostra as pontuações Ragas de dois sistemas RAG.
OpenAI RAG vs. RAG personalizado com tecnologia Milvus em Ragas Scores
Conforme mostrado no gráfico, o sistema RAG personalizado com tecnologia Milvus tem pontuações Ragas mais altas do que o sistema OpenAI RAG.
O sistema RAG personalizado com tecnologia Milvus superou o sistema OpenAI RAG em relação às pontuações Ragas e outras métricas cruciais, incluindo precisão de contexto, fidelidade, relevância de resposta e correção.
Por que o RAG personalizado supera o RAG integrado do OpenAI?
Depois de muitas comparações, descobrimos que o pipeline RAG personalizado baseado em um banco de dados vetorial tem desempenho melhor do que o sistema RAG baseado em OpenAI Assistants. Por que? Aqui estão algumas das razões mais importantes.
Os assistentes OpenAI confiam no conhecimento interno de pré-treinamento em vez do conhecimento externo
Devido à configuração interna do agente, os assistentes OpenAI dependem mais do pré-treinamento do que do conhecimento carregado. Por exemplo, quando questionado sobre aulas de finanças pessoais no ensino médio, o sistema OpenAI RAG forneceu uma resposta que se baseava em algo diferente da verdade básica.
Pergunta:
As aulas de finanças pessoais/gerenciamento de dinheiro são ministradas no ensino médio, em qualquer lugar?
Embora a resposta do sistema OpenAI RAG não esteja errada, falta-lhe especificidade, e o seu reconhecimento de não aceder aos estudos mais recentes sugere uma utilização incompleta do conhecimento do documento carregado. Em contraste, o sistema RAG personalizado fornece uma resposta mais precisa, integrando perfeitamente informações específicas da verdade básica. Esta comparação demonstra a capacidade superior do RAG personalizado de aproveitar efetivamente dados externos, distinguindo-o como uma solução mais confiável e eficiente.
RAG personalizado é melhor na segmentação de documentos e recuperação de dados do que OpenAI RAG
A estratégia de segmentação e recuperação de conhecimento da OpenAI pode precisar de otimização. Às vezes, o snippet recuperado é inadequado, como fornecer apenas “Prós: CONTRAs” para uma pergunta sobre investimentos IRA. Por outro lado, o pipeline RAG personalizado se destaca na recuperação de trechos relevantes, oferecendo uma resposta mais abrangente.
Pergunta: Prós/contras de estar mais envolvido com investimentos IRA.
Os assistentes OpenAI recuperaram um trecho falso. Em contrapartida, o RAG customizado recuperou trechos mais relevantes, oferecendo uma resposta mais abrangente e alinhada às nuances da pergunta.
Outras razões
Os assistentes OpenAI não permitem que os usuários ajustem parâmetros no pipeline RAG para personalização ou otimização. Porém, com o RAG customizado, os usuários podem ter total flexibilidade para ajuste e otimização.
Os assistentes OpenAI têm limitações de armazenamento de arquivos, enquanto o RAG personalizado com tecnologia Milvus pode ser dimensionado rapidamente sem limite superior, tornando-o uma opção melhor para usuários que exigem maior capacidade de armazenamento.
Conclusão
Nossa comparação e análise abrangentes usando a ferramenta de avaliação Ragas destacam os pontos fortes e fracos do OpenAI RAG e de um RAG personalizado baseado em um banco de dados vetorial como o Milvus. Embora o RAG da OpenAI tenha um bom desempenho na recuperação, o RAG personalizado se destaca na qualidade e relevância das respostas, desempenho de recuperação e muitos outros aspectos. Os desenvolvedores que buscam aplicações RAG poderosas e eficazes acharão preferível a flexibilidade e os recursos de uma solução RAG baseada em banco de dados vetorial para obter melhores resultados.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Cheney Zhang é um talentoso engenheiro de algoritmos na Zilliz. Com uma profunda paixão e experiência em tecnologias de IA de ponta, como LLMs e geração aumentada de recuperação (RAG), Cheney contribuiu ativamente para muitos projetos inovadores de IA, incluindo Towhee, Akcio,…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.







{kind=link}
{kind=link}
{kind=link}