
JavaScript sob demanda: como o Qwik difere do React Hydration
17 de fevereiro de 2024
Como documentar objetos de banco de dados com anotações
19 de fevereiro de 2024
Na semana passada postei sobre como sair da nuvem e, esta semana, pretendo executar um LLM de código aberto localmente no meu Mac. Se isso parece parte de algum projeto de “repatriação na nuvem”, não é: estou apenas interessado em ferramentas que posso controlar para adicionar a qualquer cadeia de fluxo de trabalho em potencial.
Supondo que sua máquina possa economizar tamanho e memória, quais são os argumentos para fazer isso? Além de não ter que pagar os custos de funcionamento do servidor de outra pessoa, você pode realizar consultas em seus dados privados sem quaisquer preocupações de segurança.
Para isso, estou usando o Ollama. Esta é “uma ferramenta que permite executar modelos de linguagem grande (LLMs) de código aberto localmente em sua máquina”. Eles têm acesso a uma lista completa de modelos de código aberto, que possuem diferentes especializações — como modelos bilíngues, modelos de tamanho compacto ou modelos de geração de código. Começou como uma ferramenta baseada em Mac, mas o Windows agora está disponível como visualização. Também pode ser usado via Docker.
Se você estava procurando um LLM como parte de um fluxo de trabalho de teste, é aqui que Ollama se encaixa:
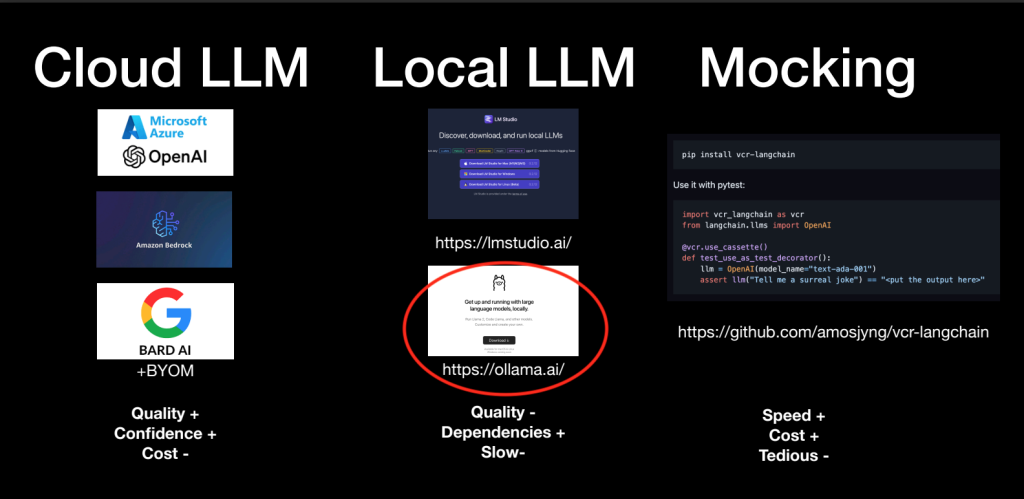
Uma apresentação de teste GenAI de @patrickdubois
Para testes, os LLMs locais controlados pela Ollama são bem independentes, mas sua qualidade e velocidade são prejudicadas em comparação com as opções que você tem na nuvem. Construir uma estrutura simulada resultará em testes muito mais rápidos, mas configurá-los – como o slide indica – pode ser entediante.
Instalei o Ollama, abri meu terminal Warp e fui solicitado a experimentar o modelo Llama 2 (por enquanto vou ignorar o argumento de que este não é realmente um código aberto). Presumi que teria que instalar o modelo primeiro, mas o correr comando cuidou disso:
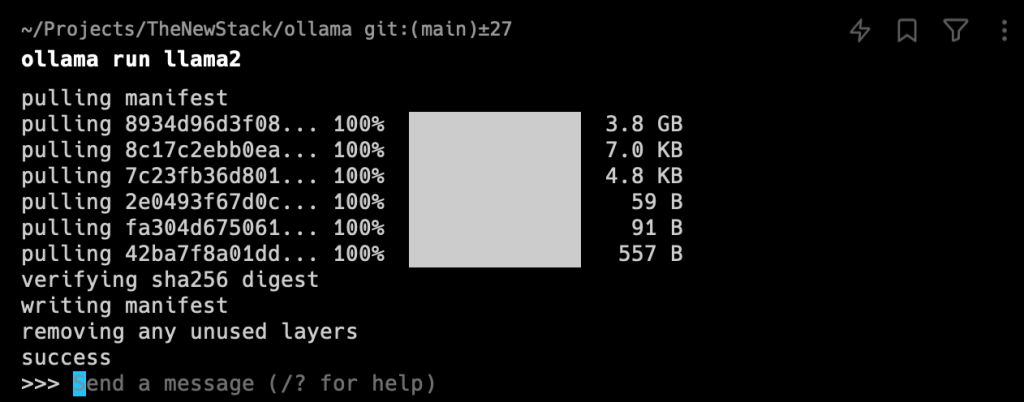
Olhando para as especificações do modelo llama2 7b, eu não tinha certeza de que meu antigo Macbook pré-M1 com apenas 8 GB de memória iria executá-lo. Mas aconteceu, muito lentamente.
Como você pode ver, já existe um terminal integrado, então fiz uma consulta de teste rápida:
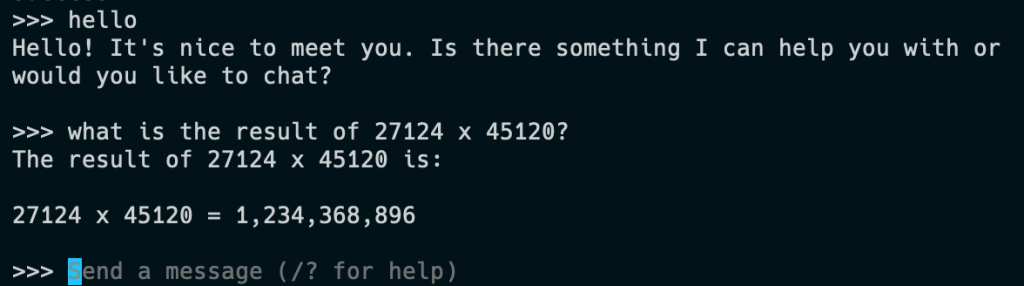
Isto não foi rápido, mas o modelo está claramente vivo. Bem, quando digo “vivo” não quero dizer isso, pois o modelo está preso temporalmente no ponto em que foi construído:

Se você estava se perguntando, a resposta correta para o problema aritmético é na verdade 1.223.834.880. Mesmo uma rápida olhada mostraria que não poderia terminar em seis – e sem dúvida seria diferente se eu fizesse isso de novo. Lembre-se, LLMs são não inteligentes, eles são extremamente bons em extrair significado linguístico de seus modelos. Mas você sabe disso, é claro.
O console conveniente é bom, mas eu queria usar a API disponível. Ollama se configura como servidor local na porta 11434. Podemos fazer uma rápida ondulação comando para verificar se a API está respondendo. Aqui está uma chamada REST sem streaming (ou seja, não interativa) via Warp com uma carga útil no estilo JSON:
> curl http://localhost:11434/api/generate -d '
{
"model": "llama2",
"prompt": "Why is the sky blue?",
"stream": false
}'
A resposta foi:
{
"model":"llama2",
"created_at":"2024-02-14T13:48:17.751003Z",
"response": "nThe sky appears blue because of a phenomenon called Rayleigh.."
"done":true,
"context":(518,25580,29962,..),
"total_duration":347735712609,
"load_duration":6372308,
"prompt_eval_duration":6193512000,
"eval_count":368,
"eval_duration":341521220000
}
A linha de resposta completa – que cobria o espalhamento de Rayleigh, o comprimento de onda da luz e o ângulo do sol – parecia correta para mim.
O caminho comum para obter controle programático seria usar Python e talvez um Jupyter Notebook. Essas não são minhas ferramentas preferidas, então tentarei usar algumas ligações C#. Encontrei alguns aqui. Felizmente, o OllamaSharp também está disponível como pacote via NuGet.
Não gosto muito do Visual Studio Code, mas depois que você configura um projeto de console C# com suporte para NuGet, ele começa rapidamente. Aqui está o código para entrar em contato com Ollama com uma dúvida:
using OllamaSharp;
var uri = new Uri("http://localhost:11434");
var ollama = new OllamaApiClient(uri);
// select a model which should be used for further operations ollama.
SelectedModel = "llama2";
ConversationContext context = null;
context = await ollama.StreamCompletion(
"How are you today?",
context, stream => Console.Write(stream.Response)
);
Eventualmente obtemos a resposta diretamente no console de depuração (o bit azul):
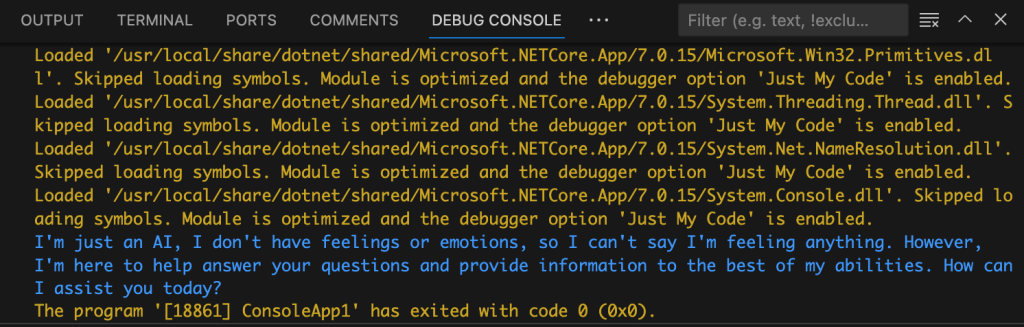
Muito legal.
OK, agora estamos prontos para perguntar algo um pouco mais específico. Já vi pessoas pedindo resumos categorizados de suas contas bancárias, mas antes de confiar isso, deixe-me tentar algo mais mundano. Vou pedir uma receita baseada na comida da minha geladeira:
.. string question = "I have the following ingredients in my fridge: aubergine, milk, cheese, peppers. What food could I cook with this and other basic ingredients?"; context = await ollama.StreamCompletion( question, context, stream => Console.Write(stream.Response) );
Demorou muito para fazer isso (muitas horas na verdade; tive tempo de fazer compras!) E o Time To First Token (TTFT) demorou alguns minutos. O resultado está aqui:

Dado que não treinamos o LLM e não adicionamos nenhum texto de receita por meio da geração aumentada de recuperação (RAG) para melhorar a qualidade complementando a representação interna do LLM, acho que esta resposta é muito impressionante. Ele entendeu o que significava “ingredientes básicos” e cada receita abrange um estilo diferente. Também intuiu que eu não precisava cada um dos meus ingredientes a ser usado e calculei corretamente que o ingrediente distinto era a berinjela.
Eu certamente teria confiança para deixar isso resumir uma conta bancária com categorias definidas, se essa fosse uma tarefa que eu valorizasse. A natureza controlável do Ollama foi impressionante, mesmo no meu Macbook. Como uma perspectiva adicional, conversei com o historiador/engenheiro Ian Miell sobre seu uso do modelo Llama2 70b maior em uma caixa um pouco mais pesada de 128 GB para escrever um texto histórico a partir de fontes extraídas. Ele também achou aquilo impressionante, mesmo com uma estranha alucinação a-histórica.
Embora as coisas ainda estejam mudando com os LLMs de código aberto, especialmente em torno das questões de dados de treinamento e preconceitos, a maturidade das soluções está claramente melhorando, dando esperança razoável para capacidade futura sob condições consideradas.
A postagem Como configurar e executar um LLM local com Ollama e Llama 2 apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}
{kind=link}