
Por que o WASI Preview 2 prepara a produção do WebAssembly
6 de abril de 2024
Use Podman para criar e trabalhar com máquinas virtuais
6 de abril de 2024
No início deste ano, escrevi sobre como configurar e executar um LLM local com Ollama e Llama 2. Neste artigo, examinarei uma opção alternativa para executar localmente grandes modelos de linguagem. Embora a Ollama seja uma empresa privada, a LocalAI é um projeto de código aberto mantido pela comunidade.
Aparentemente, cada um deles oferece ao usuário algo ligeiramente diferente. De Ollama, consigo efetivamente uma plataforma com um LLM para brincar. No entanto, LocalAI oferece um substituto imediato para a API do OpenAI. Na prática, isso significa que posso usar URIs OpenAI, mas apenas apontar para o contêiner.
Outra diferença está na forma como os dois produtos lidam com os contêineres. LocalAI aproveita o Docker – e esse é seu método principal – mas também permite construir o contêiner ou o binário manualmente. Ollama recomenda usar o Docker para obter aceleração de GPU, mas funciona sem ele.
Vamos começar. Observe que tenho o Docker Desktop instalado no meu Mac.
LocalAI oferece uma configuração multifuncional (AIO) próxima à oferta de Ollama. Isso é inteligente, pois posso me especializar onde for necessário mais tarde, ao mesmo tempo em que começo com uma configuração completa.
eu abri o meu Urdidura linha de comando e execute o prompt do docker abaixo nos documentos. Irei acompanhar este passo a passo em velocidade moderada, mas presumo que o leitor esteja confortável com o Docker. Deixei puxar e como vocês podem ver demorou cerca de uma hora:

Ao concluir, você pode ver os serviços modelo que oferece com o pacote AIO:
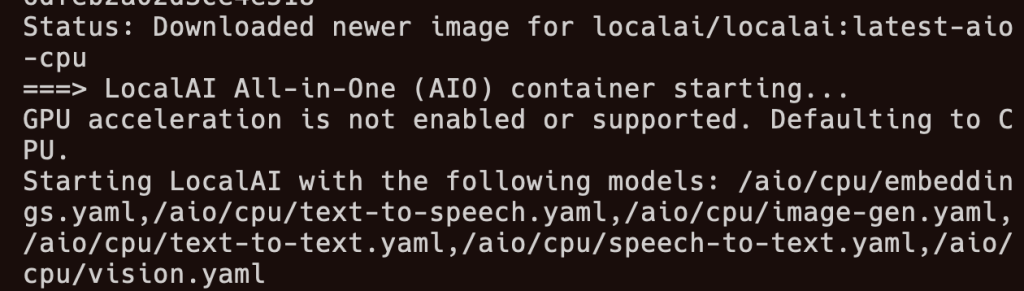
Mais explicitamente, a resposta ao curl http://localhost:8080/v1/models deu:
{"object":"list","data":(
{"id":"text-embedding-ada-002","object":"model"},
{"id":"whisper-1","object":"model"},
{"id":"stablediffusion","object":"model"},
{"id":"gpt-4-vision-preview","object":"model"},
{"id":"tts-1","object":"model"},{"id":"gpt-4","object":"model"},
{"id":"MODEL_CARD","object":"model"},
{"id":"bakllava-mmproj.gguf","object":"model"},
{"id":"voice-en-us-amy-low.tar.gz","object":"model"})}
Um cartão modelo é um contêiner de metadados.
Acionar a alça na área de trabalho do Docker nos fez executar:

A documentação deixa você um pouco sozinho aqui, mas felizmente os primeiros passos são dados pelo test curl na mensagem final conforme a imagem é verificada:
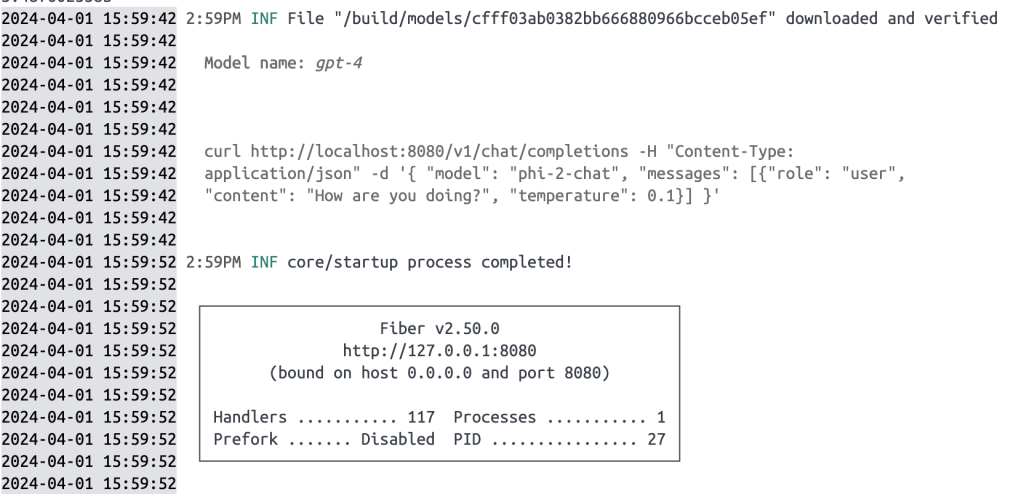
Vale ressaltar que parei e iniciei a instalação algumas vezes, e a mensagem acima foi capturada quando reiniciei o container no Docker desktop. Tanto o Docker Desktop quanto o Warp possuem um tratamento de log suficientemente bom para permitir que você leia essas mensagens mais tarde. Existem testes semelhantes na documentação.
Este é o teste que eu teria tentado, visto que LocalAI é um substituto imediato para OpenAI, como mencionei. Sabemos o que significa temperatura, e fiz uma curva semelhante com uma carga JSON ao observar pela primeira vez os wrappers de IA. Observe que o nome do modelo não é igual ao modelo da interface de chat.
Não consegui fazer o cliente de bate-papo funcionar devido a erros (falaremos mais sobre isso depois), mas testei o serviço de reconhecimento de imagem usando um exemplo de curl semelhante que me foi fornecido na mensagem do Docker:
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json"
-d '{
"model": "gpt-4-vision-preview",
"messages": (
{"role":"user",
"content": (
{ "type":"text",
"text": "What is in the image?"
},
{ "type": "image_url",
"image_url": {"url":"https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"}
}
),
"temperature": 0.9
}
)
}'
>>response
{
"created":1711995490,
"object":"chat.completion",
"id":"f78380ca-fbcd-455f-9834-ddffcefd6b03",
"model":"gpt-4-vision-preview",
"choices":
(
{"index":0,
"finish_reason":"stop",
"message":
{"role":"assistant",
"content":"The image features a wooden walkway or boardwalk that is surrounded by lush grass and green foliage, creating a serene and picturesque scene."
}
}
),
"usage":{"prompt_tokens":0,"completion_tokens":0,"total_tokens":0}}%
O log do contêiner confirmou que tudo estava funcionando:
2024-04-02 14:16:53 1:16PM INF Loading model 'bakllava.gguf' with backend llama-cpp
No meu MacBook Pro pré-Apple Silicon 2015, isso levou 12 minutos.
“A imagem apresenta uma passarela de madeira ou calçadão cercada por grama exuberante e folhagem verde, criando um cenário sereno e pitoresco.” Aqui está a imagem de teste que está sendo descrita:

O texto de resposta precisava de uma temperatura bastante alta (0,9) para produzir a qualidade narrativa (ou seja, uso de “exuberante”, “sereno”, “pitoresco”). A força dos LLMs é sua aparente capacidade de abordar um tema de maneira “inteligente”, usando outras fontes. Mas o resultado é bom.
Para testar o modelo e a teoria, vamos alterar essa temperatura (para 0,1) para confirmar que obtemos uma descrição mais simples. E nós fazemos: “A imagem apresenta um caminho de madeira ou calçadão cercado por grama alta, flores e ervas daninhas. O calçadão parece estar no meio de um grande campo ou pradaria.”
Perfeito, apenas os fatos. Isso levou 26 minutos!
Embora não seja uma boa cópia, também experimentei a interface do serviço de transcrição e funcionou rapidamente. Baixei um conhecido discurso sombrio:

Em seguida, enviei a solicitação para a modelo e recebi uma longa resposta:
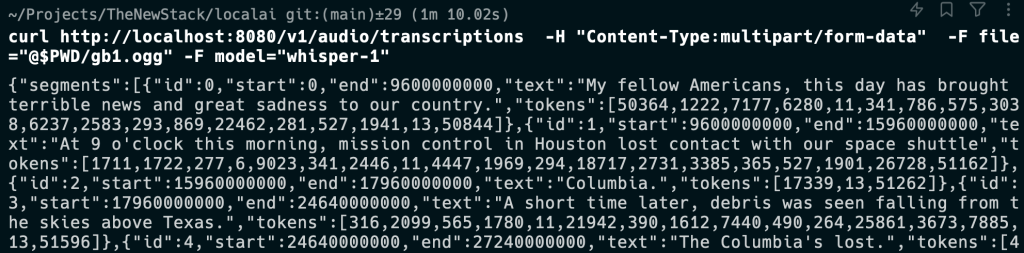
Dentro do Docker, podemos ver o que entrou em ação:
2024-04-02 15:39:51 2:39PM INF Loading model 'ggml-whisper-base.bin' with backend whisper
O texto completo é costurado a partir dos segmentos no final:
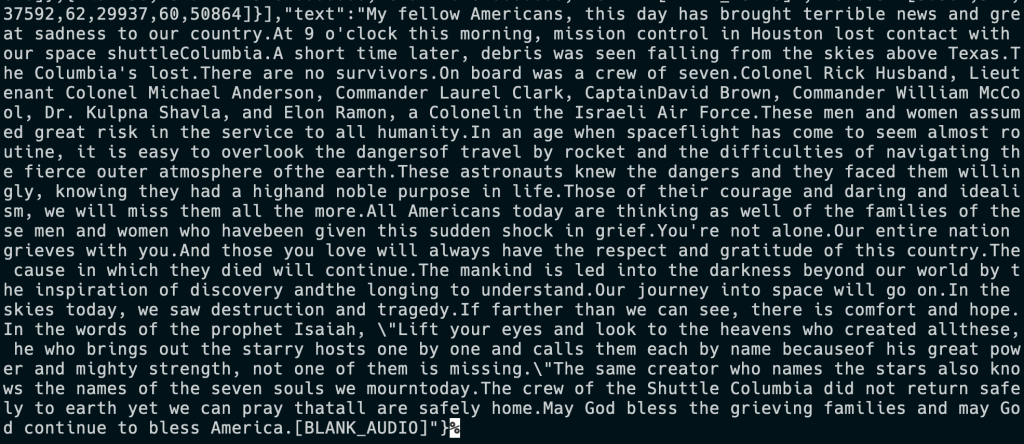
Não sei o suficiente sobre o algoritmo para comentar um punhado de palavras não separadas, mas estou impressionado com o uso de marcas de fala para marcar uma citação no texto. No entanto, não estamos aqui para considerar detalhadamente os modelos em si.
LocalAI não está oferecendo ao usuário uma plataforma como tal, e isso fica evidente no surgimento de um erro que exige total retidão do desenvolvedor para ser seguido. Como há mais opções (tudo em um, manipulação de GPU, etc.) e pessoas como eu usando máquinas com especificações antigas, os mantenedores estão muito ocupados mantendo alta a qualidade da experiência. Havia instruções sobre como construir o modelo manualmente caso ocorressem erros – e esse é um caminho razoável a seguir se você espera trabalhar com o projeto ao longo do tempo.
Tentei manter parte desta postagem como uma comparação ombro a ombro entre Ollama e LocalAI com meu MacBook de baixa especificação, mas à medida que esse campo se expande, o usuário pode esperar uma variedade mais rica de opções. Embora um pouco difícil no momento, LocalAI oferece um caminho mais direto para o modelo e aproxima você um pouco mais do sistema. Para quem precisa de uma experiência única e mais simples, Ollama provavelmente é a opção certa para você. À medida que você se aprofunda na colocação de modelos em seu fluxo de trabalho, LocalAI fornecerá a opção mais transparente de trabalhar – desde que o tratamento de erros seja mais eficaz.
A postagem Como executar um LLM local via LocalAI, um projeto de código aberto apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}
{kind=link}