A ascensão de poderosos modelos de grandes linguagens (LLMs), como GPT-4, Gemini 1.5 e Claude 3, mudou o jogo em IA e tecnologia. Com alguns modelos capazes de processar mais de 1 milhão de tokens, sua capacidade de lidar com contextos longos é realmente impressionante. No entanto:
Muitas estruturas de dados são muito complexas e em constante evolução para que os LLMs possam lidar com eficácia por conta própria.
Gerenciar dados corporativos massivos e heterogêneos dentro de uma janela de contexto é simplesmente impraticável.
A geração aumentada de recuperação (RAG) ajuda a resolver esses problemas, mas a precisão da recuperação é um grande gargalo para o desempenho de ponta a ponta. Uma solução é integrar LLMs com big data por meio de bancos de dados vetoriais SQL avançados. Este tipo de sinergia entre LLMs e big data não só torna os LLMs mais eficazes, mas também permite que as pessoas obtenham melhor inteligência a partir de big data. Além disso, reduz ainda mais a alucinação do modelo, ao mesmo tempo que fornece transparência e confiabilidade aos dados.
Estado Atual dos Bancos de Dados de Vetores
Sendo a pedra angular dos sistemas RAG, as bases de dados vetoriais desenvolveram-se rapidamente no ano passado. Eles geralmente podem ser categorizados em três tipos: bancos de dados de vetores dedicados, sistemas de recuperação de palavras-chave e vetores e bancos de dados de vetores SQL. Cada um tem vantagens e limitações.
Bancos de dados de vetores especializados
Alguns bancos de dados de vetores (como Pinecone, Weaviate e Milvus) são projetados especificamente para pesquisa de vetores desde o início. Eles apresentam bom desempenho nesta área, mas têm capacidades gerais de gerenciamento de dados um tanto limitadas.
Sistemas de recuperação de palavras-chave e vetores
Representados pelo Elasticsearch e OpenSearch, esses sistemas são amplamente utilizados na produção devido aos seus abrangentes recursos de recuperação baseados em palavras-chave. No entanto, eles consomem recursos substanciais do sistema, e a precisão e o desempenho das consultas híbridas de palavras-chave e vetores costumam ser insatisfatórios.
Bancos de dados de vetores SQL
Um banco de dados vetorial SQL é um tipo especializado de banco de dados que combina os recursos dos bancos de dados SQL tradicionais com os recursos de um banco de dados vetorial. Ele fornece a capacidade de armazenar e consultar com eficiência vetores de alta dimensão com a ajuda de SQL.
Dois principais bancos de dados vetoriais SQL são ilustrados na figura acima: pgvector e MyScaleDB. Pgvector é um plugin de pesquisa vetorial para PostgreSQL. É fácil de começar e útil para gerenciar pequenos conjuntos de dados. No entanto, devido às desvantagens de armazenamento de linha do Postgres e às limitações do algoritmo vetorial, o pgvector tende a ter menor precisão e desempenho para consultas vetoriais complexas e em grande escala.
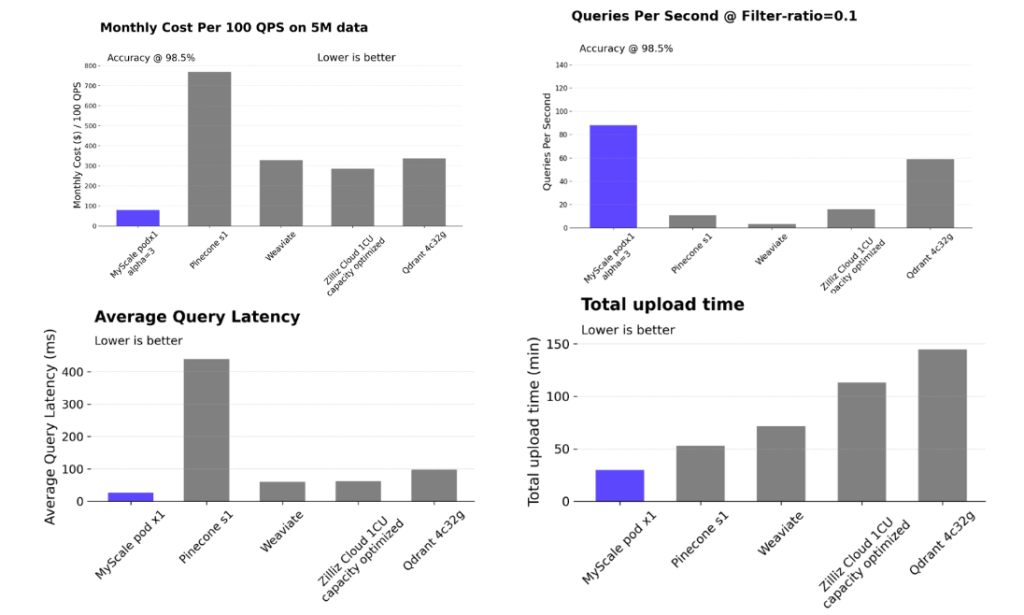
MyScaleDB é um banco de dados vetorial SQL de código aberto construído no ClickHouse (um banco de dados SQL de armazenamento colunar). Ele foi projetado para fornecer uma base de dados econômica e de alto desempenho para aplicativos GenAI. MyScaleDB também é o primeiro banco de dados vetorial SQL a superar bancos de dados vetoriais especializados em desempenho geral e economia.
Fonte: MyScale GitHub
O poder da modelagem de dados conjuntos SQL e vetoriais
Apesar do surgimento do NoSQL e das tecnologias de big data, os bancos de dados SQL continuam a dominar o mercado de gerenciamento de dados meio século após o início do SQL. Até sistemas como Elasticsearch e Spark adicionaram interfaces SQL. Com suporte SQL, MyScaleDB permite alto desempenho em pesquisa e análise de vetores.
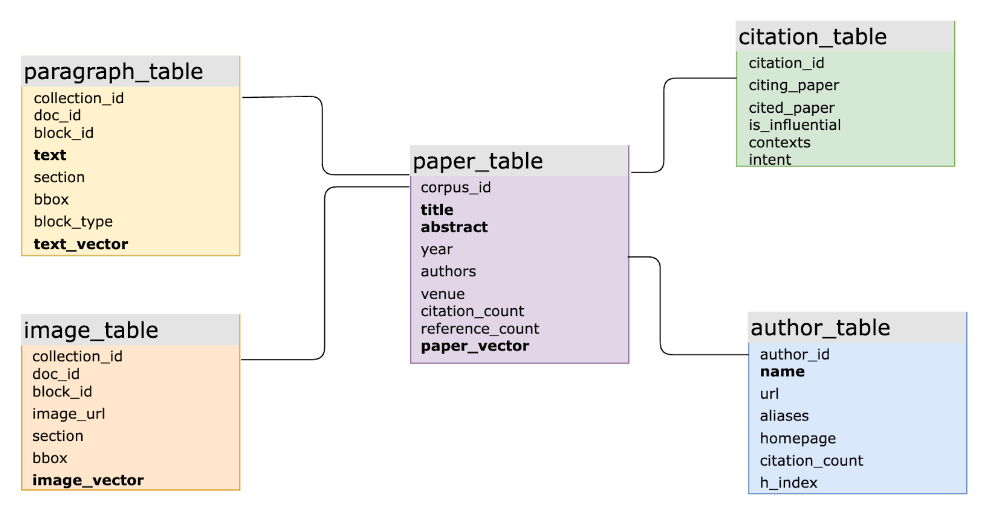
Em aplicações de IA do mundo real, a integração de SQL e vetores aumenta a flexibilidade da modelagem de dados e simplifica o desenvolvimento. Por exemplo, um produto acadêmico em grande escala usa MyScaleDB para perguntas e respostas inteligentes sobre dados massivos de literatura científica. O esquema SQL principal inclui mais de 10 tabelas, várias com estruturas de índice invertido baseadas em vetores e palavras-chave, conectadas por meio de chaves primárias e estrangeiras. O sistema lida com consultas complexas envolvendo dados estruturados, vetoriais e de palavras-chave e consultas unidas em várias tabelas. Esta é uma tarefa desafiadora para bancos de dados vetoriais especializados, que muitas vezes leva a iterações lentas, consultas ineficientes e altos custos de manutenção.
O principal esquema de banco de dados vetorial SQL de um produto acadêmico de grande escala suportado pelo MyScale (as colunas em negrito possuem índices vetoriais associados ou índices invertidos).
Melhorando a precisão e a eficiência de custos do RAG
Em sistemas RAG do mundo real, superar a precisão da recuperação (e os gargalos de desempenho associados) requer uma maneira eficiente de combinar a consulta de dados estruturados, vetoriais e de palavras-chave.
Por exemplo, em uma aplicação financeira, quando os usuários consultam um banco de dados de documentos perguntando: “Qual foi a receita da em 2023 globalmente?” metadados estruturados como “” e “2023” não podem ser capturados por vetores semânticos ou presentes em texto consecutivo. A recuperação de vetores em todo o banco de dados pode gerar resultados ruidosos, reduzindo a precisão final.
No entanto, informações como nomes de empresas e anos podem muitas vezes ser obtidas como metadados de documentos. Usar WHERE year=2023 AND company LIKE "%<company_name>%" já que as condições de filtragem para consultas vetoriais podem identificar com precisão informações relevantes, aumentando significativamente a confiabilidade do sistema. Nas finanças, produção e pesquisa, observamos a modelagem de dados vetoriais SQL e a consulta conjunta para melhorar a precisão de 60% para 90%.
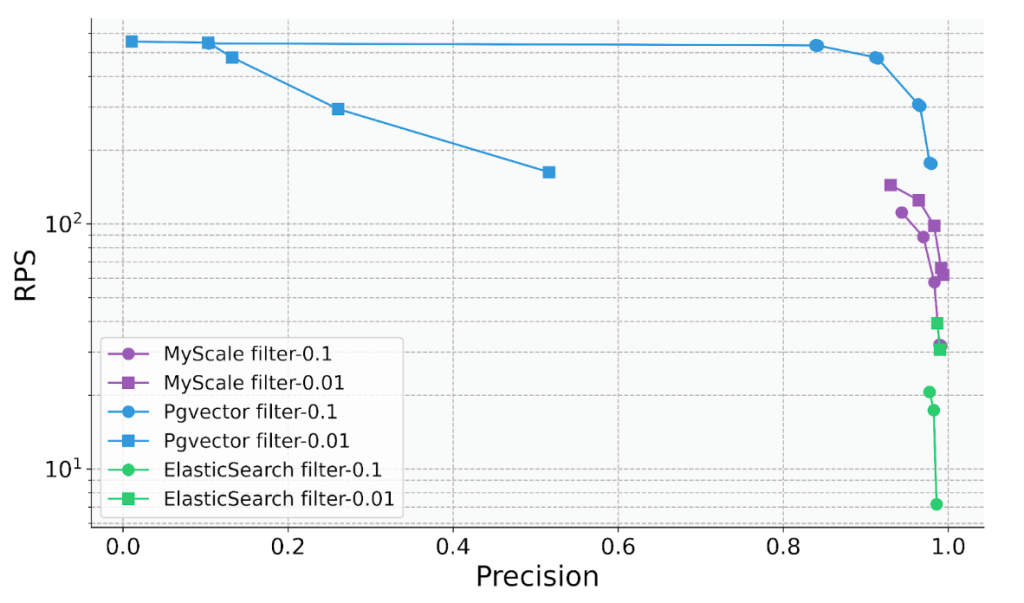
Embora os produtos de banco de dados tradicionais tenham reconhecido a importância das consultas vetoriais na era LLM e começado a adicionar recursos vetoriais, ainda existem problemas significativos com a precisão de suas consultas combinadas. Por exemplo, em cenários de pesquisa de filtro, a taxa de consultas por segundo (QPS) do Elasticsearch cai para cerca de cinco quando a taxa de filtragem é 0,1, e o PostgreSQL com o plug-in pgvector tem uma precisão de apenas cerca de 50% quando a taxa de filtragem é 0,01. Isso demonstra precisão e desempenho de consulta instáveis, o que limita bastante seu uso. Por outro lado, o banco de dados vetorial SQL MyScale atinge mais de 100 QPS e 98% de precisão em vários cenários de taxa de filtragem, a 36% do custo do pgvector e 12% do custo do Elasticsearch.
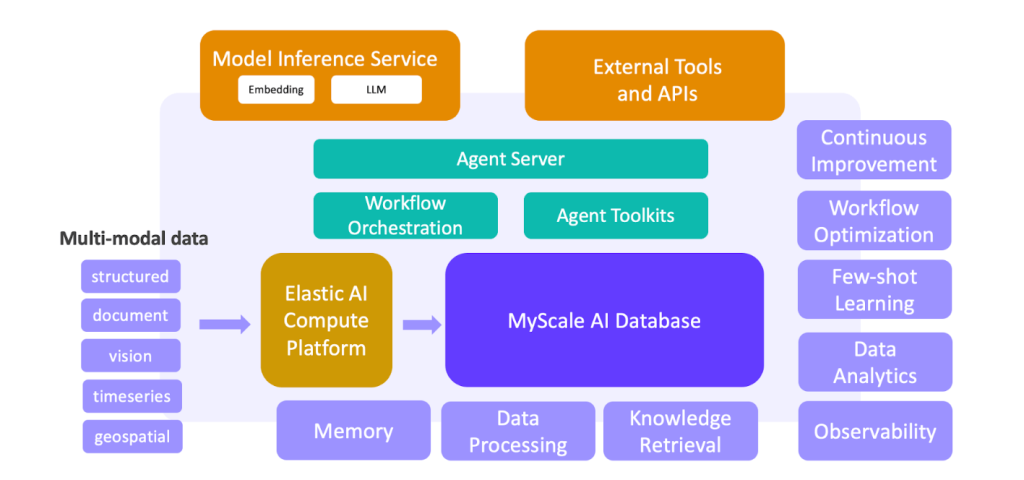
LLM + Big Data: Construindo uma Plataforma de Agente de Próxima Geração
O aprendizado de máquina e o big data impulsionaram o sucesso dos aplicativos web e móveis. Mas com a ascensão dos LLMs, estamos mudando de direção para construir uma nova geração de LLMs com soluções de big data. Essas soluções desbloqueiam recursos essenciais para processamento de dados em larga escala, recuperação de conhecimento, observabilidade, análise de dados, aprendizado rápido e muito mais. Eles criam um ciclo fechado entre dados e IA, formando a base para uma plataforma LLM + agente de big data de última geração. Esta mudança de paradigma já está em curso em setores como a investigação científica, finanças, indústria e saúde.
Com o rápido desenvolvimento da tecnologia, espera-se que alguma forma de inteligência artificial geral (AGI) surja nos próximos cinco a 10 anos. Em relação a esta questão, devemos perguntar: Precisamos de um modelo estático, virtual, ou de outra solução mais abrangente? Os dados são, sem dúvida, o importante elo que conecta os LLMs, os usuários e o mundo. Nossa visão é integrar organicamente LLMs e big data para criar um sistema de IA mais profissional, colaborativo e em tempo real, que também seja cheio de calor humano e valor.
Você está convidado a explorar o repositório MyScaleDB no GitHub e aproveitar SQL e vetores para construir aplicativos de IA inovadores em nível de produção.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Linpeng Tang, cofundador e CTO da MyScale. Atualmente, ele lidera uma equipe talentosa focada no desenvolvimento do principal produto da MyScale, um banco de dados vetorial baseado em SQL, adaptado para capacitar as empresas no gerenciamento de dados não estruturados e na construção de aplicações de IA em escala. Antes de seu papel…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.







{kind=link}
{kind=link}
{kind=link}