
A versão 22 do Node.js melhora a experiência do desenvolvedor
30 de abril de 2024
Não é possível conectar-se ao host da migração de armazenamento VMware
6 de maio de 2024
Todas as empresas de TI hoje devem tentar incorporar IA generativa em seus próprios aplicativos, esperançosamente de tal forma que agregue valor ao usuário e lealdade ao fornecedor.
O serviço de rede social LinkedIn incorporou recentemente o GenAI em dois de seus serviços e compartilhou seus aprendizados na semana passada em um blog.
A postagem baseia-se na experiência da empresa na construção de dois serviços “premium” do LinkedIn, um para resumir o texto de uma postagem e outro para recomendar postagens de emprego.
“O bom da IA generativa é que ela é realmente democratizada e reduziu o nível de desenvolvimento da IA. Você pode criar um protótipo inicial muito, muito rápido”, disse Karthik Ramgopal, engenheiro ilustre do LinkedIn. “Mas levar a qualidade a um nível aceitável, com uma grande escala de entradas e saídas, leva muito, muito tempo.
Isso nos leva à nossa primeira lição sobre design GenAI…
Nº 1: Não traçar o progresso futuro no momento inicial (regra 80/20)
Depois de traçar um roteiro, a equipe de desenvolvimento do LinkedIn ficou satisfeita ao descobrir que havia concluído 80% do design básico no primeiro mês. Certamente, o aplicativo estaria pronto imediatamente.
Isso acabou não sendo o caso. Na verdade, foram necessários mais quatro meses para atingir uma taxa de conclusão de 95%.
Por um lado, as alucinações continuaram a atormentar o sistema, apesar dos esforços consideráveis para as reduzir. Outros problemas de qualidade também persistiram.
O progresso inicial “cria expectativas inatingíveis”, escreveram os pesquisadores no post. “O ritmo inicial criou uma falsa sensação de ‘quase lá’, que se tornou desanimadora à medida que a taxa de melhoria desacelerou significativamente para cada ganho subsequente de 1%.”
Em outras palavras, para as equipes de projeto, um projeto de IA pode ter um Vale da Morte extremamente traiçoeiro para atravessar.
“Você pode ser enganado pelo progresso inicial enganosamente rápido”, disse Ramgopal. “Mas testá-lo em batalha com uma grande variedade de entradas, controlando as alucinações, certificando-se de que (a saída) é factual, certificando-se de que a voz e o tom estão alinhados com o que você quer que seja, garantindo que as respostas não leva uma eternidade e a latência é aceitável – todas essas coisas levam muito tempo para acertar.”
Esses modelos têm “vontade própria”, disse Ramgopal. A correção de um problema pode desencadear outros problemas em outras partes do aplicativo.
Nº 2 RAG faz os LLMs funcionarem
A controladora do LinkedIn é a Microsoft, que também possui uma participação significativa na OpenAI. Portanto, tem acesso a um dos melhores LLMs disponíveis. No entanto, um LLM por si só não pode responder a todas as perguntas, nem tem, por si só, acesso aos ricos tesouros de dados de utilizadores do LinkedIn. E treinar novamente o LLM ou construir um novo seria proibitivamente caro, mesmo para o LinkedIn.
Assim, a empresa utilizou o pipeline Retrieval Augmented Generation (RAG), que no processo de resposta a uma pergunta, pode chamar APIs internas e até fontes externas como o Bing, e então injetar as respostas de volta no LLM. Nesta abordagem, o LLM pode explorar o recurso externo em uma chamada de função. Para que um artigo seja resumido, é necessário que o LLM leia primeiro o artigo e depois aplique sua própria base de conhecimento para interpretar os resultados.
No entanto, há trabalho adicional a ser feito até mesmo para preparar dados externos para as RAG. Todos os LLMs têm um limite para a quantidade de informações contextuais que podem ingerir, portanto, a filtragem e até mesmo o ajuste fino de dados adicionais ainda precisam ser feitos.
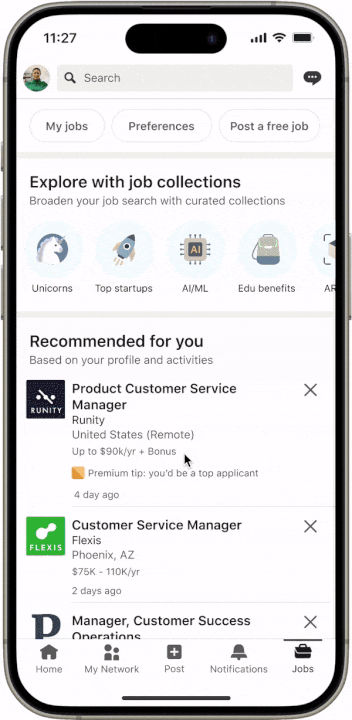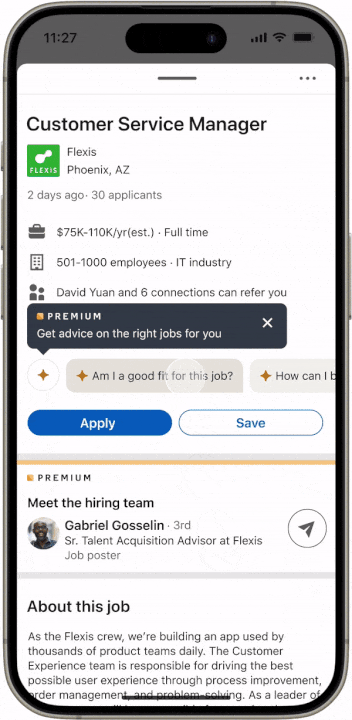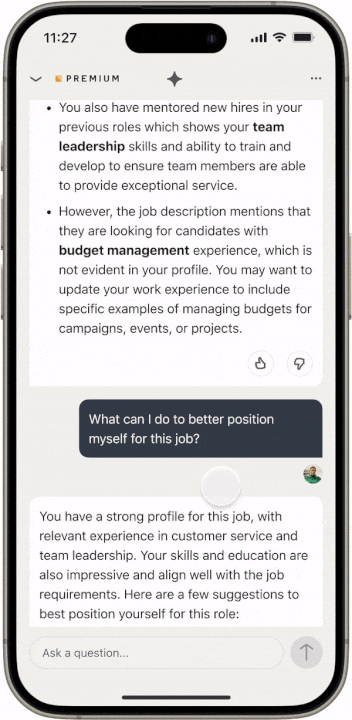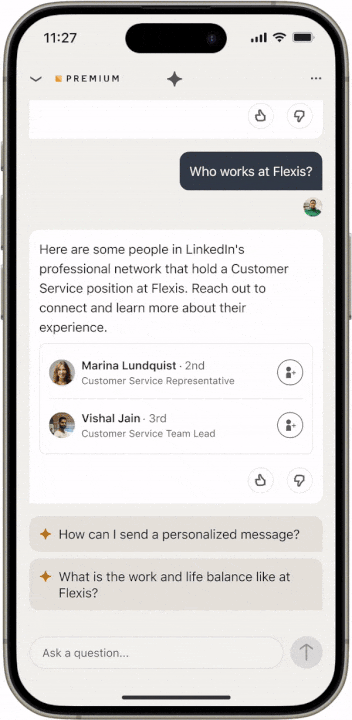
Nº 3: Descreva suas APIs
Fora de sua dieta típica de json, os grandes modelos de linguagem (LLMs) são criaturas bastante estúpidas, incapazes de circunavegar o mundo ao seu redor.
O LinkedIn possui uma riqueza de informações exclusivas sobre seus usuários e suas habilidades, os materiais de treinamento disponíveis e assim por diante. Embora muitos dos dados possam ser acessados programaticamente com bastante facilidade por meio de APIs RPC, eles não são fáceis de usar pelos LLMs.
“Muitas das APIs projetadas atualmente, internas ou externas, não são muito compatíveis com LLM, elas são projetadas para que engenheiros humanos as chamem via código”, disse Ramgopal. É aqui que surgem muitas das alucinações, um subproduto de não entender como a API funciona para obter informações precisas.
Portanto, o LinkedIn embarcou em um projeto para agrupar um esquema que descreve as “habilidades” disponíveis em torno dessas APIs para ajudar os LLMs a usá-las. O padrão OpenAPI, por exemplo, oferece uma maneira para as APIs se descreverem.
Cada habilidade possui uma descrição legível sobre o que a API faz, juntamente com a configuração necessária para chamá-la.
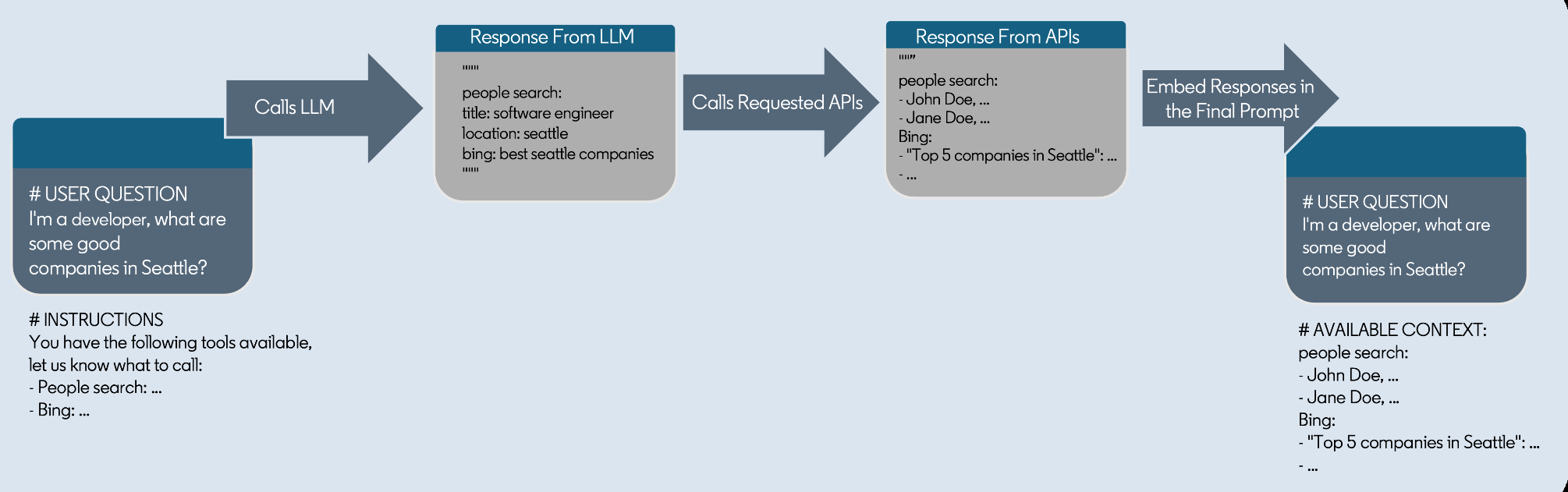
Chamando APIs usando Skills (LinkedIn)
#4 Não divida o elefante em muitos pedaços
Trabalhar em paralelo é bom – dentro dos limites.
Construindo um dos primeiros projetos GenAI no LinkedIn, a equipe não tinha muitos recursos pré-existentes aos quais recorrer. Quase tudo, exceto o próprio LLM, teve que ser construído do zero.
Dentro do LinkedIn, diferentes agentes foram construídos por equipes diferentes, cada um com sua área de especialização. Isso acelerou o processo de desenvolvimento, embora acarretasse o custo da fragmentação.
“Você deve ter muito cuidado com a quantidade de trabalho que pede ao LLM imediatamente”,
–Karthik Ramgopal
“Manter uma experiência de usuário uniforme tornou-se um desafio quando as interações subsequentes com um assistente podem ser gerenciadas por diversos modelos, prompts ou ferramentas”, observou a postagem.
Para facilitar a experiência do usuário, o LinkedIn criou um pequeno pod de engenharia “horizontal” para construir os componentes comuns a todos os recursos que estão sendo construídos, incluindo ferramentas de teste, prompts e componentes UX compartilhados.
Nº 5: A avaliação será um desafio
Os programas GenAI são diferentes dos aplicativos regulares. Avaliar o seu sucesso requer um novo tipo de avaliação, que não pode ser facilmente automatizado.
“Para avaliar, você precisa ter um conjunto objetivo de diretrizes. Caso contrário, você receberá pontuações em todos os lugares”, disse Ramgopal. “Você está essencialmente avaliando um produto subjetivo e não determinístico, por isso é difícil chegar a um conjunto objetivo de diretrizes.”
Por exemplo, apenas retornar uma resposta correta a uma pergunta não é mais suficiente. A voz e o tom de como essa resposta é dada também devem ser considerados. Uma pessoa que perguntasse se está apta para um determinado trabalho consideraria o serviço rude se a resposta fosse “Você é péssimo” (mesmo que fosse precisa).
Felizmente, o LinkedIn tinha uma equipe interna de linguistas, que construiu um conjunto de ferramentas e processos para construir métricas em torno da taxa de alucinação, violações responsáveis de IA, coerência, estilo e outros fatores.
O grupo está atualmente em processo de automatização do pipeline de avaliação.
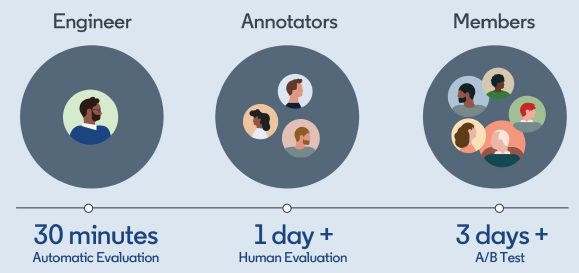
Aprendizado bônus: GenAI tem tudo a ver com latência vs. Precisão
Construir aplicações generativas de IA é tudo sobre a compensação entre latência e precisão.
“É um jogo que você precisa jogar com muito cuidado”, disse Ramgopal. “Você deve ter muito cuidado com a quantidade de trabalho que pede ao LLM imediatamente.”
Por exemplo, uma maneira de fazer com que os LLMs parem de ter alucinações é por meio de sugestões de cadeia de pensamentos, onde você pede ao LLM para revelar as etapas de raciocínio necessárias para chegar à resposta. A desvantagem, porém, é que isso amplia o tempo necessário para entregar a resposta ao usuário.
Existem maneiras de contornar isso, é claro: uma delas é transmitir a resposta ou fornecer aos usuários as partes da resposta conforme elas aparecem, para que eles não tenham que esperar pela resposta inteira. Mas as principais decisões sobre latência vs. a precisão terá que ser feita na fase de desenvolvimento do projeto arquitetônico.
“Você ficará tentado a usar um LLM em qualquer lugar. Mas você deve ter muito cuidado sobre onde usá-lo e quando usá-lo”, disse Ramgopal. “LLM é como uma escavadeira. Você não vai querer usá-lo se quiser simplesmente arrancar um prego. Algo pode ser muito mais barato, muito mais eficaz e muito mais fácil de usar, como um modelo tradicional ou mesmo um mecanismo de regras de lógica de negócios.”
A postagem 5 lições da primeira incursão do LinkedIn no desenvolvimento GenAI apareceu pela primeira vez em The New Stack.

{kind=link}
{kind=link}
{kind=link}