
O software de código aberto apoiado pela comunidade vale o risco?
17 de maio de 2024
Meta lança compilador React de código aberto
17 de maio de 2024
Uma das técnicas comprovadas para reduzir alucinações em grandes modelos de linguagem é a geração aumentada por recuperação, ou RAG. O RAG usa um recuperador que pesquisa dados externos para aumentar um prompt com contexto antes de enviá-lo ao gerador, que é o LLM.
Embora o RAG seja a abordagem mais popular, ele é mais adequado para construir contexto a partir de dados não estruturados que foram indexados e armazenados em um banco de dados vetorial. Antes que o RAG possa recuperar o contexto, um processo em lote converte os dados não estruturados em incorporações de texto e os armazena no banco de dados vetorial. Isso torna o RAG ideal para lidar com dados que não mudam com frequência.
Quando os aplicativos exigem contexto de dados em tempo real — como cotações de ações, rastreamento de pedidos, status de voos ou gerenciamento de estoque — eles contam com a capacidade de chamada de função dos LLMs. O objetivo do RAG e da chamada de função é complementar o prompt com contexto — seja de fontes de dados existentes ou APIs em tempo real — para que o LLM tenha acesso a informações precisas.
LLMs com recursos de chamada de função são fundamentais para o desenvolvimento de agentes de IA que executam tarefas específicas de forma autônoma. Por exemplo, estas capacidades permitem a integração de LLMs com outras APIs e sistemas, permitindo a automação de fluxos de trabalho complexos que envolvem recuperação, processamento e análise de dados.
Uma análise mais detalhada da chamada de função
A chamada de função, também conhecida como uso de ferramenta ou chamada de API, é uma técnica que permite que LLMs façam interface com sistemas externos, APIs e ferramentas. Ao fornecer ao LLM um conjunto de funções ou ferramentas, juntamente com suas descrições e instruções de uso, o modelo pode selecionar e invocar de forma inteligente as funções apropriadas para realizar uma determinada tarefa.
Esse recurso é revolucionário, pois permite que os LLMs se libertem de suas limitações baseadas em texto e interajam com o mundo real. Em vez de apenas gerar texto, os LLMs podem agora executar ações, controlar dispositivos, recuperar informações de bancos de dados e executar uma ampla gama de tarefas, aproveitando ferramentas e serviços externos.
Nem todo LLM é capaz de utilizar recursos de chamada de função. Os LLMs exclusivamente treinados ou ajustados possuem a capacidade de determinar se o prompt exige chamada de função. O Berkeley Function-Calling Leaderboard fornece informações sobre o desempenho dos LLMs em várias linguagens de programação e cenários de API, mostrando a versatilidade e robustez dos modelos de chamada de função no tratamento de execuções de funções múltiplas, paralelas e complexas. Esta versatilidade é crucial para o desenvolvimento de agentes de IA que possam operar em diferentes ecossistemas de software e lidar com tarefas que requerem ações simultâneas.
Os aplicativos normalmente invocam o LLM com recursos de chamada de função duas vezes: uma vez para mapear o prompt no nome da função de destino e seus argumentos de entrada e novamente para enviar a saída da função invocada para gerar a resposta final.
O fluxo de trabalho abaixo mostra como o aplicativo, a função e o LLM trocam mensagens para completar todo o ciclo.
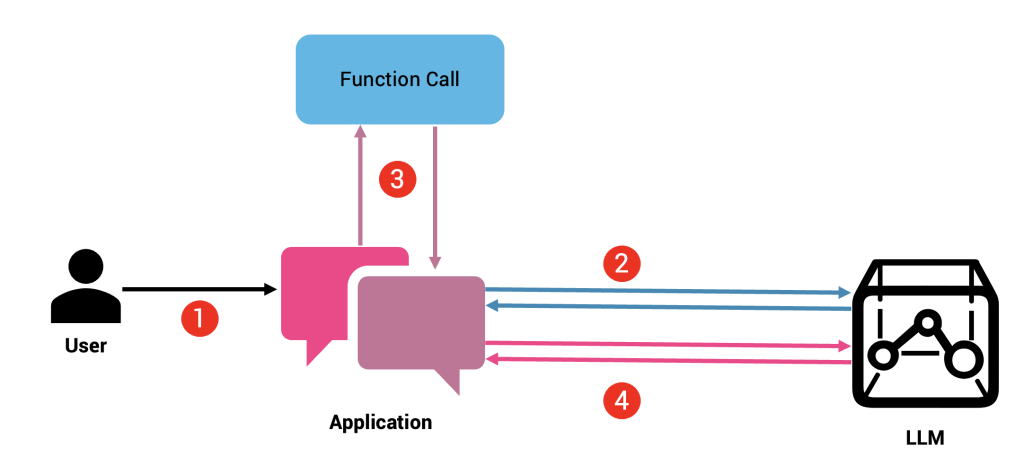
Passo 1: o usuário envia um prompt que pode exigir acesso à função — por exemplo, “Qual é a previsão do tempo em Nova Delhi?”
Passo 2: O aplicativo envia o prompt junto com todas as funções disponíveis. No nosso exemplo, este pode ser o prompt junto com o esquema de entrada da função get_current_weather(city). O LLM determina se o prompt requer chamada de função. Se sim, ele consulta a lista de funções fornecida — e seus respectivos esquemas — e responde com um dicionário JSON preenchido com o conjunto de funções e seus argumentos de entrada.
etapa 3: o aplicativo analisa a resposta do LLM. Se contiver as funções, irá invocá-las sequencialmente ou em paralelo.
Passo 4: a saída de cada função é então incluída no prompt final e enviada ao LLM. Como o modelo agora tem acesso aos dados, ele responde com uma resposta baseada nos dados factuais fornecidos pelas funções.
Integrando RAG e chamada de função
A integração do RAG com a chamada de função pode aprimorar significativamente os recursos dos aplicativos baseados em LLM. Os agentes RAG baseados em chamadas de função utilizam os pontos fortes de ambas as abordagens – aproveitando bases de conhecimento externas para recuperação precisa de dados enquanto executam funções específicas para conclusão eficiente de tarefas.
O uso de chamadas de função em uma estrutura RAG permite processos de recuperação mais estruturados. Por exemplo, uma função pode ser predefinida para extrair informações específicas com base nas consultas do usuário, que o sistema RAG recupera de uma base de conhecimento abrangente. Este método garante que as respostas não sejam apenas relevantes, mas também adaptadas com precisão às necessidades da aplicação.
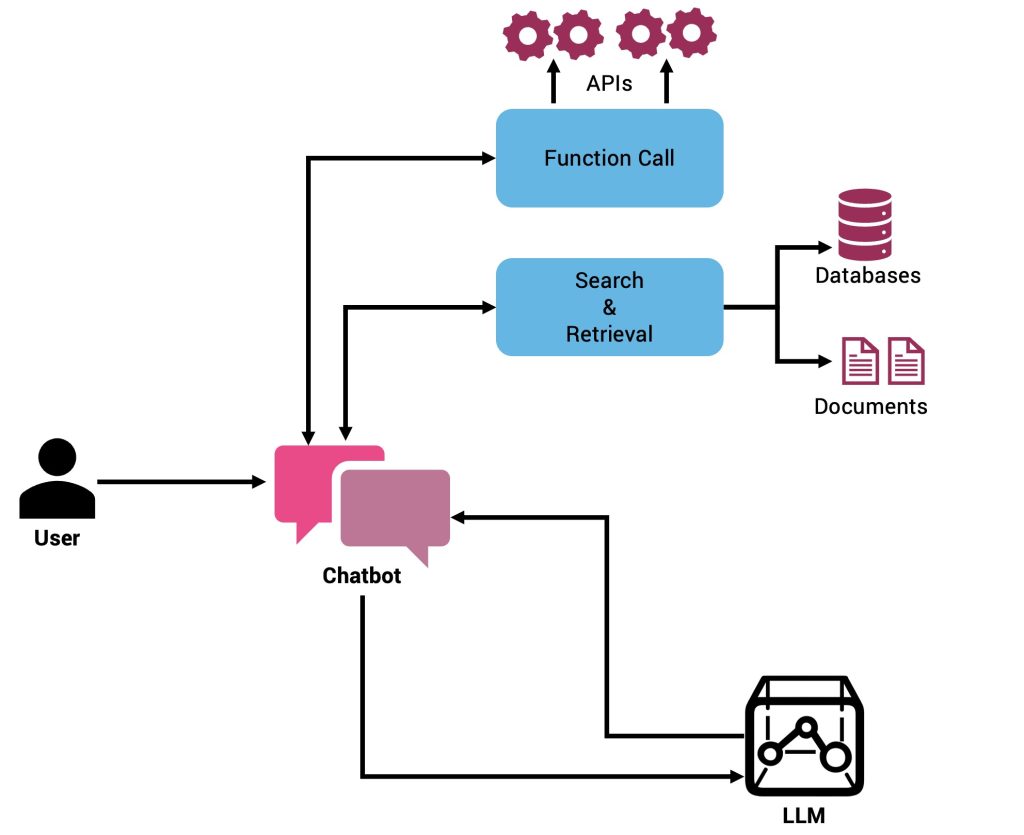
Por exemplo, num cenário de suporte ao cliente, o sistema poderia recuperar especificações de produto de um banco de dados e, em seguida, usar uma chamada de função para formatar essas informações para consultas do usuário, garantindo respostas consistentes e precisas.
Além disso, os agentes RAG podem lidar com consultas complexas interagindo dinamicamente com bancos de dados externos e APIs por meio de funções predefinidas, agilizando assim os fluxos de trabalho dos aplicativos e reduzindo a necessidade de intervenção manual. Esta abordagem é particularmente benéfica em ambientes onde a tomada rápida de decisões é crucial — como em serviços financeiros ou diagnósticos médicos, onde o sistema pode extrair as pesquisas ou dados de mercado mais recentes e aplicar imediatamente funções para analisar essas informações.
Escolhendo LLMs com suporte para chamadas de função
É importante escolher o LLM certo que ofereça suporte a chamadas de função para criar fluxos de trabalho de agente e agentes RAG. Abaixo está uma lista de LLMs comerciais e abertos que são ideais para chamadas de funções.
OpenAI GPT-4 e GPT-3.5 Turbo
Os modelos GPT-4 e GPT-3.5 Turbo da OpenAI são os LLMs comerciais mais conhecidos que suportam chamadas de funções. Isso permite que os desenvolvedores definam funções personalizadas que o LLM pode chamar durante a inferência, para recuperar dados externos ou realizar cálculos. O LLM gera um objeto JSON contendo o nome da função e os argumentos. O código do desenvolvedor pode então executar isso e retornar a saída da função para o LLM.
Google Gêmeos
O Gemini LLM do Google também oferece suporte a chamadas de funções por meio do Vertex AI e do Google AI Studio. Os desenvolvedores podem definir funções e descrições, que o modelo Gemini pode invocar durante a inferência, retornando dados JSON estruturados.
Claude antrópico
A família de LLMs Claude 3 da Anthropic possui uma API que permite recursos de chamada de função semelhantes aos modelos da OpenAI.
Comando Coerente
Os LLMs Command R e Command R+ da Cohere também fornecem uma API para chamada de função, permitindo a integração com ferramentas externas e fontes de dados.
Mistral
O Mistral 7B LLM de código aberto demonstrou recursos de chamada de função, permitindo que os desenvolvedores definam funções personalizadas que o modelo pode invocar durante a inferência.
NexusRaven
NexusRaven é um LLM 13B de código aberto que foi projetado especificamente para chamadas de funções avançadas, superando até mesmo o GPT-4 em alguns benchmarks para invocar ferramentas e APIs de segurança cibernética.
Gorila OpenFunctions
O modelo Gorilla OpenFunctions é um LLM 7B ajustado na documentação da API. Ele pode gerar chamadas de função e solicitações de API precisas a partir de prompts em linguagem natural.
Fogos de artifício FireFunction
FireFunction V1 é um modelo de chamada de função de código aberto baseado no modelo Mixtral 8x7B. Ele atinge qualidade próxima ao nível GPT-4 para casos de uso do mundo real de geração estruturada de informações e tomada de decisões de roteamento.
Nós Hermes 2 Pró
Hermes 2 Pro é um modelo de parâmetros 7B que se destaca em chamadas de funções, saídas estruturadas em JSON e tarefas gerais. Ele atinge 90% de precisão na avaliação de chamada de função e 81% na avaliação de saída JSON estruturada criada com Fireworks.ai. O Hermes 2 Pro foi ajustado nos modelos Mistral 7B e Llama 3 8B, oferecendo aos desenvolvedores uma escolha.
Nos próximos artigos sobre chamada de função, explorarei como implementar esse recurso com LLMs comerciais e abertos, a fim de construir um chatbot que tenha acesso a dados em tempo real.
A postagem Um guia abrangente para chamadas de funções em LLMs apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}
{kind=link}