
Lançamentos do SolidStart; Next.js 15 lançamentos, com perguntas DX
1 de junho de 2024
Pesquisa vs. desenvolvimento: Onde está o fosso na IA?
2 de junho de 2024
Embora nenhum grande modelo de linguagem (LLM) tenha alguma vez andado de bicicleta, eles compreendem claramente o papel da bicicleta no domínio do transporte humano. O que eles parecem oferecer aos desenvolvedores de software é um conhecimento semântico do mundo real, combinado com uma compreensão do mundo técnico. Vimos isso claramente em uma postagem recente, quando conseguimos produzir um esquema SQL simples para publicação de livros apenas descrevendo-o em inglês.
Embora eu estivesse satisfeito com o desempenho do Llama 3 na criação de esquemas, um colega da minha época de Oracle apontou que o esquema de publicação de livros é um exemplo bastante conhecido. Para uma explicação legível, isso é uma coisa boa, mas para ampliar um pouco mais as habilidades dos LLMs, neste post verei quão bem um LLM pode alterar seu próprio esquema com base em questões descritas em inglês. Desta vez usarei OpenAI’s GPT-4ojá que isso fez uma boa revisão de código para mim recentemente.
Como ponto de partida, começaremos com a mesma pergunta que fizemos no primeiro artigo e resumiremos a resposta, que é semelhante à da última vez. Desta vez, obtivemos um diagrama ERD do GPT-4o, bem como uma boa explicação dos relacionamentos:

E semelhante à tentativa anterior, sugeriu este esquema:
CREATE TABLE Author ( author_id INT AUTO_INCREMENT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), birth_date DATE, nationality VARCHAR(50) ); CREATE TABLE Publisher ( publisher_id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100), address VARCHAR(255), contact_number VARCHAR(20), email VARCHAR(100) ); CREATE TABLE Book ( book_id INT AUTO_INCREMENT PRIMARY KEY, title VARCHAR(100), genre VARCHAR(50), publication_date DATE, isbn VARCHAR(20) UNIQUE, author_id INT, publisher_id INT, FOREIGN KEY (author_id) REFERENCES Author(author_id), FOREIGN KEY (publisher_id) REFERENCES Publisher(publisher_id) );
Pequeno problema: prefiro que as tabelas usem o plural para os objetos que contêm. E acho que esse é o padrão aceito.
O LLM descreveu estas limitações de relacionamento:

Então, usando os mesmos dados da última vez, vamos verificar se obtemos o mesmo resultado em nosso playground SQL, dbfiddle.
Se propagarmos os dados e adicionarmos a visualização da última vez…
INSERT INTO Author (first_name, last_name, birth_date)
VALUES ('Iain', 'Banks', '1954-02-16');
INSERT INTO Author (first_name, last_name, birth_date)
VALUES ('Iain', 'M Banks', '1954-02-16');
INSERT INTO Publisher (name, address)
VALUES ('Abacus', 'London');
INSERT INTO Publisher (name, address)
VALUES ('Orbit', 'New York');
INSERT INTO Book (title, author_id, publisher_id, publication_date)
VALUES ('Consider Phlebas', 2, 2, '1988-04-14');
INSERT INTO Book (title, author_id, publisher_id, publication_date)
VALUES ('The Wasp Factory', 1, 1, '1984-02-15');
CREATE VIEW ViewableBooks AS
SELECT Book.title 'Book', Author.first_name 'Author firstname', Author.last_name 'Author surname', Publisher.name 'Publisher', Book.publication_date
FROM Book, Publisher, Author
WHERE Book.author_id = Author.author_id
AND Book.publisher_id = Publisher.publisher_id;
…obtemos a visualização do resultado que queríamos do dbfiddle na tabela abaixo:
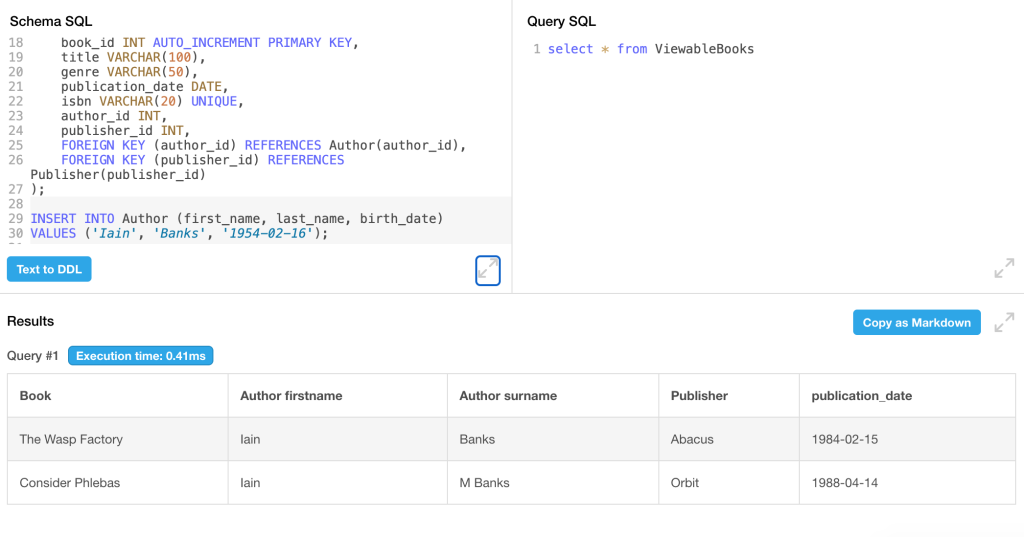
Você mesmo pode executá-lo a partir do link até que ele expire. O segundo sobrenome, que inclui a letra do meio “M”, parece estranho. E veremos uma questão relacionada a isso a seguir.
A primeira alteração
Como mencionei no artigo anterior sobre geração de SQL, “Ian Banks” e “Ian M Banks” são na verdade o mesmo autor. Da última vez, deixamos essa questão do pseudônimo sem solução. Então, vamos pedir ao LLM para corrigir esse problema:

Então isso é bom. Desta vez, teve de mapear o conceito literário de “pseudónimo” num desenho de esquema existente que já tinha produzido. Portanto, foi necessário fazer mais do que apenas descobrir uma solução existente. Em primeiro lugar, e os novos relacionamentos:

Isso parece kosher. Estas são as tabelas recentemente alteradas:
CREATE TABLE Pseudonym ( pseudonym_id INT AUTO_INCREMENT PRIMARY KEY, pseudonym VARCHAR(100), author_id INT, FOREIGN KEY (author_id) REFERENCES Author(author_id) ); CREATE TABLE Book ( book_id INT AUTO_INCREMENT PRIMARY KEY, title VARCHAR(100), genre VARCHAR(50), publication_date DATE, isbn VARCHAR(20) UNIQUE, pseudonym_id INT, publisher_id INT, FOREIGN KEY (pseudonym_id) REFERENCES Pseudonym(pseudonym_id), FOREIGN KEY (publisher_id) REFERENCES Publisher(publisher_id) );
Isso também parece certo. O esquema vincula o livro a um pseudônimo em vez do autor. Vamos fazer um novo dbfiddle com o novo esquema, alimentar os dados alterados para trabalhar com ele e ver se conseguimos recuperar nosso bom resultado:
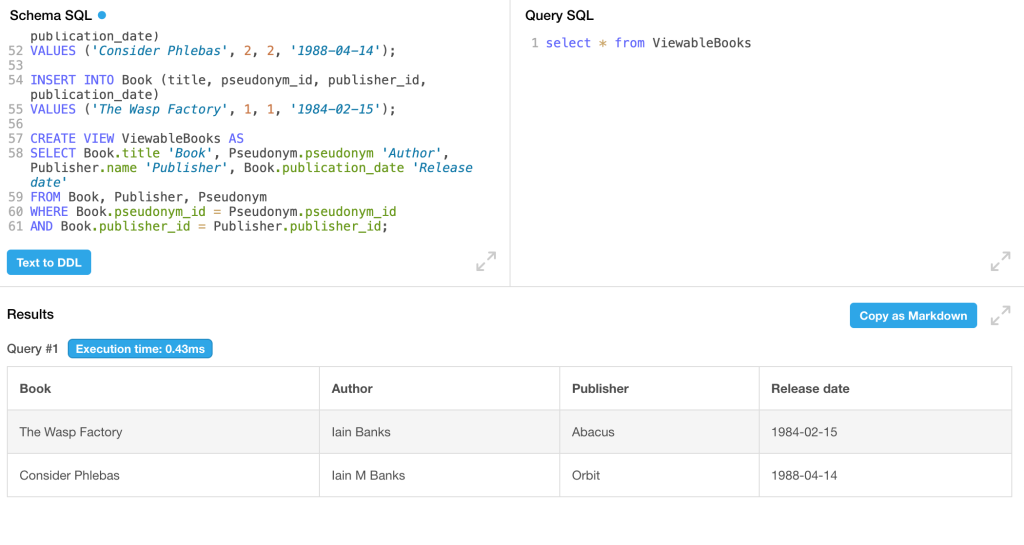
Na verdade, é uma tabela melhor, agora que a coluna do pseudônimo é apenas um campo.
Outro pedido de alteração
Agora vou pedir mais uma alteração de esquema. Sabemos que os livros podem ter vários autores (você deve se lembrar que da última vez, o Llama 3 sugeriu isso sem avisar), então queremos que o GPT-4o altere seu esquema novamente.

A única tabela adicional é apenas esta:
CREATE TABLE BookAuthor ( book_id INT, pseudonym_id INT, PRIMARY KEY (book_id, pseudonym_id), FOREIGN KEY (book_id) REFERENCES Book(book_id), FOREIGN KEY (pseudonym_id) REFERENCES Pseudonym(pseudonym_id) );
Então o relacionamento muda:
(Observe o estranho erro de colchete após descrever os primeiros relacionamentos. Isso foi repetido para todas as descrições de relacionamentos. Parece estar impedindo a impressão do texto “1:M” ou “M:M” – talvez um emoji confusão?)
Além disso, é claro, o GPT-4o está acompanhando a conversa como um único tópico – está levando o trabalho anterior para seu contexto. Essa habilidade tão alardeada realmente torna o trabalho com ela muito mais natural. No geral, ele teve um bom desempenho (e muito rapidamente) ao analisar nossas descrições em inglês para alterar seu próprio esquema sugerido.
Antes de ficarmos muito entusiasmados
Os esquemas tratam do relacionamento entre as coisas – eles não exigem uma compreensão íntima das próprias coisas. No entanto, isso não significa que o caminho esteja livre para que os LLMs assumam o design do banco de dados ainda.
Otimizar para consultas e esquemas SQL sempre foi uma forma de arte. É necessário entender quais consultas comuns serão melhor atendidas por um design, quantas tabelas serão tocadas, interdependências de consultas, definição de índices, particionamento, etc. E isso antes de lidar com os dilemas do teorema CAP – consistência vs. disponibilidade. Por trás dessas abstrações técnicas estão as expectativas humanas de recuperação de dados que estão longe de ser simples.
Não tenho dúvidas de que alguma mistura de LLM e especialização lidará com essas questões de engenharia ao longo do tempo, mas por enquanto devemos ganhar com o quão bem o GPT-4o foi capaz de produzir e alterar um esquema saudável.
A postagem GPT-4o e SQL: até que ponto um LLM pode alterar seu próprio esquema? apareceu primeiro em The New Stack.



{kind=link}
{kind=link}
{kind=link}