SAN FRANCISCO – Na semana passada, a Snowflake anunciou que adotou as tabelas Apache Iceberg como formato nativo. Agora os clientes podem colocar seus data lakes Snowflake no Iceberg e até mesmo criar tabelas externas em um provedor de nuvem de sua escolha e fazer com que o Snowflake os gerencie.
Além disso, a Snowflake lançou o Polaris, um catálogo de tabelas Iceberg que poderia ser chamado por qualquer mecanismo de processamento de dados que pudesse ler o formato (Spark, Dremio, Snowflake).
Com o catálogo, usando o mecanismo de sua escolha, você poderá fazer junções entre tabelas coletando informações que até então eram muito mais difíceis de obter. As permissões, para quem pode ver o quê, são gerenciadas pelo próprio catálogo. E em breve você poderá obter metadados de outros catálogos.
A empresa discutiu essas iniciativas de interoperabilidade durante sua própria conferência de usuários, a Snowflake Data Cloud Summit, realizada na semana passada em São Francisco,
Mas a empresa não estava sozinha na adoção ávida do Iceberg.
Além disso, na semana passada, o principal rival do Snowflake, Databricks, anunciou que havia comprado o provedor de distribuição Iceberg Tabular, uma empresa que oferece uma distribuição Iceberg fundada pelas três pessoas que criaram a tecnologia, Ryan Blue, Daniel Weeks e Jason Reid.
Como o Apache Iceberg se tornou a Bela do Baile? Claramente, os data lakes e data lakes estão prestes a passar por uma mudança fundamental para o código aberto.
Apache Iceberg veio da Netflix
“Acho que neste espaço temos um cliente clássico que deseja o controle de sua solução. “–Ron Ortloff do Floco de Neve.
O Iceberg surgiu de uma série de frustrações por parte dos engenheiros da Netflix para dimensionar suas operações de dados, com os formatos de arquivo existentes não confiáveis em cenários distribuídos.
A Netflix abriu o código-fonte do projeto em 2018 e doou-o à Apache Software Foundation. Desde então, AirBnB, Amazon Web Services, Alibaba, Expedia e outros contribuíram.
A vantagem que o Iceberg traz é que ele permite que os dados sejam armazenados uma vez – eliminando toda uma confusão de problemas de conformidade e segurança relacionados à cópia de dados em vários locais – e consultados por qualquer um dos vários mecanismos compatíveis com o Iceberg.
Um grande número de distribuições Iceberg estão disponíveis atualmente, como Celerdata, Clickhouse, Cloudera, Dremio, Starburst e, claro, Tabular. No início deste mês, a Microsoft anunciou que ofereceria suporte às tabelas Iceberg do Snowflake em seu próprio Microsoft Fabric, um serviço de análise no Azure.
Os clientes são muito muito sensível ao aprisionamento atualmente, disse Ron Ortloff, gerente sênior de produtos da Snowflake. “Acho que neste espaço temos um cliente clássico que deseja o controle de sua solução”, disse ele em entrevista ao The New Stack. “Portanto, queremos dar a esses clientes uma escolha.”
A Snowflake tem sido tradicionalmente uma empresa que gerencia os dados de um cliente na nuvem, aliviando o cliente do fardo considerável de gerenciá-los por conta própria. Então, por que arriscar a base de clientes com uma oferta que permite aos clientes gerenciar seus próprios dados?
“Acreditamos que há 100 a 200 vezes mais dados fora do Snowflake em data lakes que podemos explorar com o Iceberg”, disse Ortloff. Em vez disso, a empresa vê-se a competir numa “excelente experiência de plataforma”, especialmente à medida que as apostas aumentam à medida que mais empresas adoptam a IA em grande escala.
“Se construirmos ótimas experiências de plataforma, a gravidade dos dados fluirá direto para lá”, disse ele.
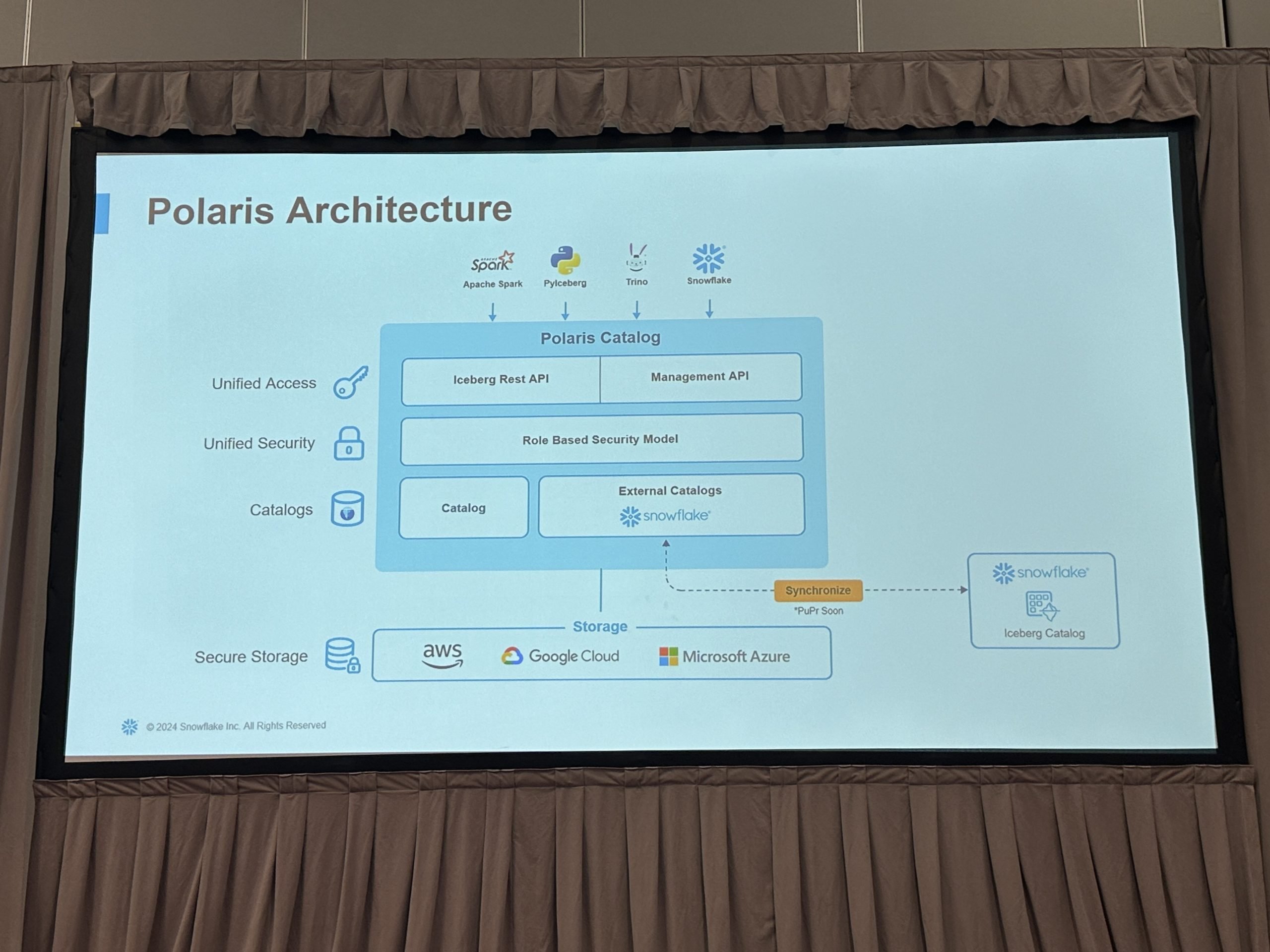
Um diagrama que mostra como o Polaris se integra ao restante da infraestrutura do Snowflake. Da apresentação de Ron Ortloff.
Databricks solidifica sua experiência em icebergs
A aquisição da Tabular pela Databricks foi de fato estimulada pela demanda dos clientes por melhor interoperabilidade para formatos de data lakes.
“Esta é uma longa jornada, que provavelmente levará vários anos para ser alcançada nessas comunidades”, admite a empresa em um blog. Para esse fim, a Databricks lançou o Delta Lake UniForm, que é um conjunto de tabelas que funcionam no formato Delta Lake do próprio Iceberg e Databricks e no formato de data lake transacional Apache Hudi.
Outros avaliaram a importância da compra da Databricks à luz da atividade da Snowflake.
“Depois que o armazenamento e a computação foram dissociados, todas as camadas, desde o armazenamento até a análise, começaram a ser desagregadas de forma semelhante, um processo que ocorre atualmente com as tabelas”, escreveu Siva Padisetty, CTO da New Relic, em um comunicado. “Databricks busca igualar a paridade de código aberto com Iceberg e Tabular é como eles esperam alcançá-lo.”
A competição mudará para qual empresa pode, no formato de código aberto, processar dados de forma mais rápida e econômica, com todas as salvaguardas de governança e segurança em vigor, resumiu Padisetty.
Na semana passada, cobrimos as notícias do evento Snowflake e, esta semana, o TNS continuará sua cobertura das guerras dos icebergs com o correspondente de dados do TNS, Andrew Brust, cobrindo o Data + AI Summit do Databricks, que acontecerá esta semana em São Francisco. Lá ouviremos mais sobre os planos da Databricks para o futuro do Iceberg.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Joab Jackson é editor sênior do The New Stack, cobrindo computação nativa em nuvem e operações de sistema. Ele faz reportagens sobre infraestrutura e desenvolvimento de TI há mais de 25 anos, incluindo passagens pela IDG e pela Government Computer News. Antes disso, ele…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.







{kind=link}
{kind=link}
{kind=link}