A gigante de eletrônicos de consumo Apple lançou em código aberto um plug-in que ajudaria o Apache Spark a executar pesquisas vetoriais com mais eficiência, tornando a plataforma de processamento de dados de código aberto mais atraente para processamento de dados de aprendizado de máquina em grande escala.
logotipo
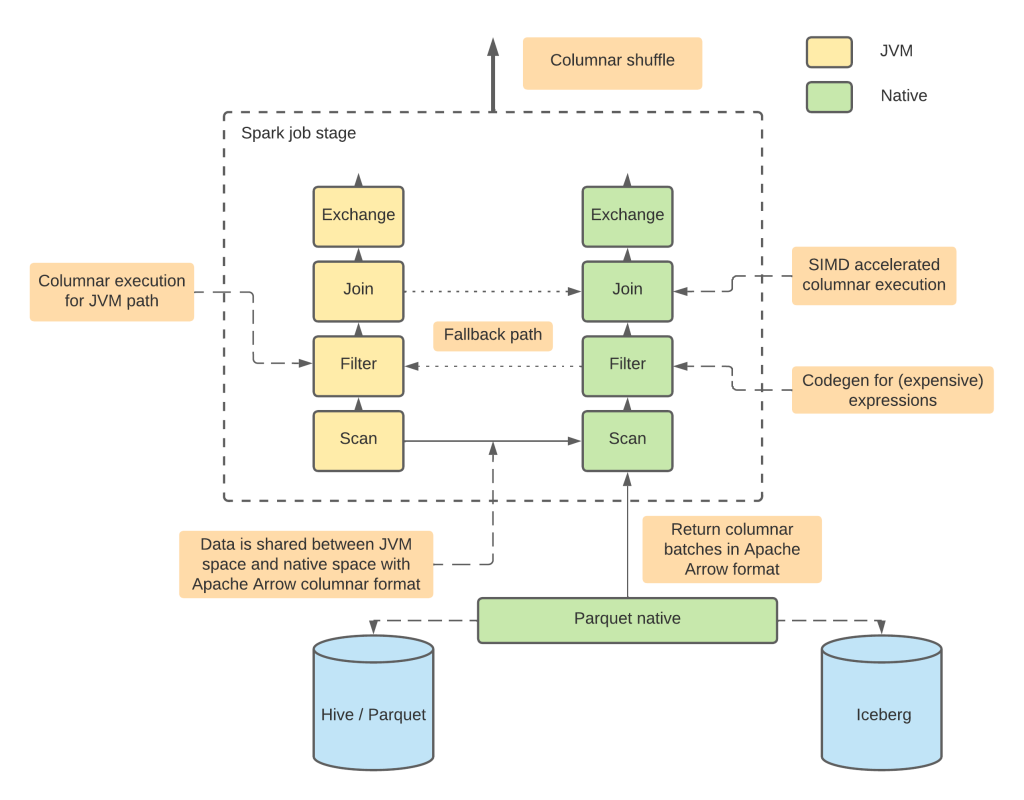
Os engenheiros da Apple por trás do plug-in baseado em Rust, chamado Apache Spark DataFusion Comet, o submeteram para se tornar um projeto da Apache Software Foundation, sob a égide do Apache Arrow. Ele é construído no mecanismo de consulta extensível Apache DataFusion (também escrito em Rust) e no formato de dados colunares Arrow.
“Nosso objetivo é acelerar a execução de consultas do Spark delegando a execução do plano físico do Spark à estrutura de execução altamente modular do DataFusion, mantendo a mesma semântica para os usuários do Spark”, explicou o engenheiro de software da Apple. Chao Solem uma lista de discussão do Apache.
Sun observou que o projeto ainda não está completo, mas partes dele já são usadas na produção.
“Este é um ótimo exemplo do conceito de sistema de dados combinável do qual todo mundo parece estar falando ultimamente”, observou Andy Grove, presidente do Comitê de Gerenciamento de Projetos da Apache Arrow. em X. “Neste caso, usando o planejamento e agendamento muito maduro do Spark e delegando ao DataFusion para execução nativa.”
O que é o cometa Apache Arrow DataFusion?
Usando o tempo de execução Apache Arrow DataFusion, o Comet pode consultar dados no formato colunar Apache Arrow, uma abordagem projetada para melhorar a eficiência da consulta e o tempo de execução da consulta por meio da execução vetorizada nativa.
O Apache Spark foi criado em 2010 para processar grandes quantidades de dados distribuídos em uma variedade de estruturas formatadas e não formatadas (“Big Data”).
O processamento vetorial se tornou uma técnica favorita na comunidade de aprendizado de máquina graças à forma como pode reduzir o tempo de análise de grandes quantidades de dados.
“A consulta vetorizada melhora o desempenho, a eficiência, a escalabilidade e o consumo de memória das consultas analíticas, operando em lotes de dados e processando vários elementos de dados em paralelo. Ele está inextricavelmente ligado à arquitetura de banco de dados colunar, pois permite que colunas inteiras sejam carregadas em um registro de CPU e processadas”, escreveu Charles Wang, evangelista sênior de produto da Fivetran, em um artigo de análise no mês passado.
O Comet foi projetado para manter a paridade de recursos com o próprio Spark (atualmente, ele suporta as versões 3.2 – 3.4 do Spark). Isso significa que os usuários podem executar as mesmas consultas, independentemente de a extensão Comet estar sendo usada.
Expressões e operadores integrados do Spark (Filtro/Projeto/Agregação/Junção/Exchange) podem funcionar com Comet, assim como o formato de armazenamento colunar Apache Parquet, no modo de leitura e gravação.
Comet também requer JDK 8 e superior e GLIBC 2.17 e pode ser executado em Linux ou Mac OS.
Outros plug-ins Spark que aceleram o processamento de vetores
A Apple não é o único membro do clube FAANG interessado em processamento vetorial: no ano passado, a Meta também lançou em código aberto seu próprio projeto para processamento vetorial Spark: Velox, observado engenheiro de software Chris Riccomini.
Projetos semelhantes incluem Gluten da Intel (recentemente aceito na incubação ASF), acelerador RAPIDS Spark da Nvidia para GPUs, Blaze (que também funciona com Apache Arrow DataFusion) e o mecanismo de consulta SQL distribuído Ballista.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Joab Jackson é editor sênior do The New Stack, cobrindo computação nativa em nuvem e operações de sistema. Ele faz reportagens sobre infraestrutura e desenvolvimento de TI há mais de 25 anos, incluindo passagens pela IDG e pela Government Computer News. Antes disso, ele…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.







{kind=link}
{kind=link}
{kind=link}