
Snowflake, DataBricks e a luta pelas tabelas Apache Iceberg
11 de junho de 2024
Nove principais vulnerabilidades de segurança de API: como se defender delas
11 de junho de 2024
Esta proposta visa introduzir os mecanismos de conversão, validação e fallback do plano físico do projeto Gluten no Apache Spark. Isso permitirá que o Spark tenha maior flexibilidade e robustez na execução de planos físicos, ao mesmo tempo que aproveita as otimizações de desempenho proporcionadas pelo Gluten.
Motivação
Atualmente, o Apache Spark não possui um mecanismo oficial para oferecer suporte à execução de planos físicos em várias plataformas. O projeto Gluten oferece um mecanismo que utiliza o padrão Substrait para converter e otimizar os planos físicos do Spark. Ao introduzir os mecanismos de conversão, validação e fallback do plano Gluten no Spark, podemos melhorar significativamente a portabilidade e a interoperabilidade dos planos físicos do Spark, permitindo-lhes operar em um espectro mais amplo de ambientes de execução sem exigir a migração dos usuários, ao mesmo tempo que melhora a eficiência de execução do Spark. através da utilização de técnicas avançadas de otimização do Gluten.
Proposta de projeto
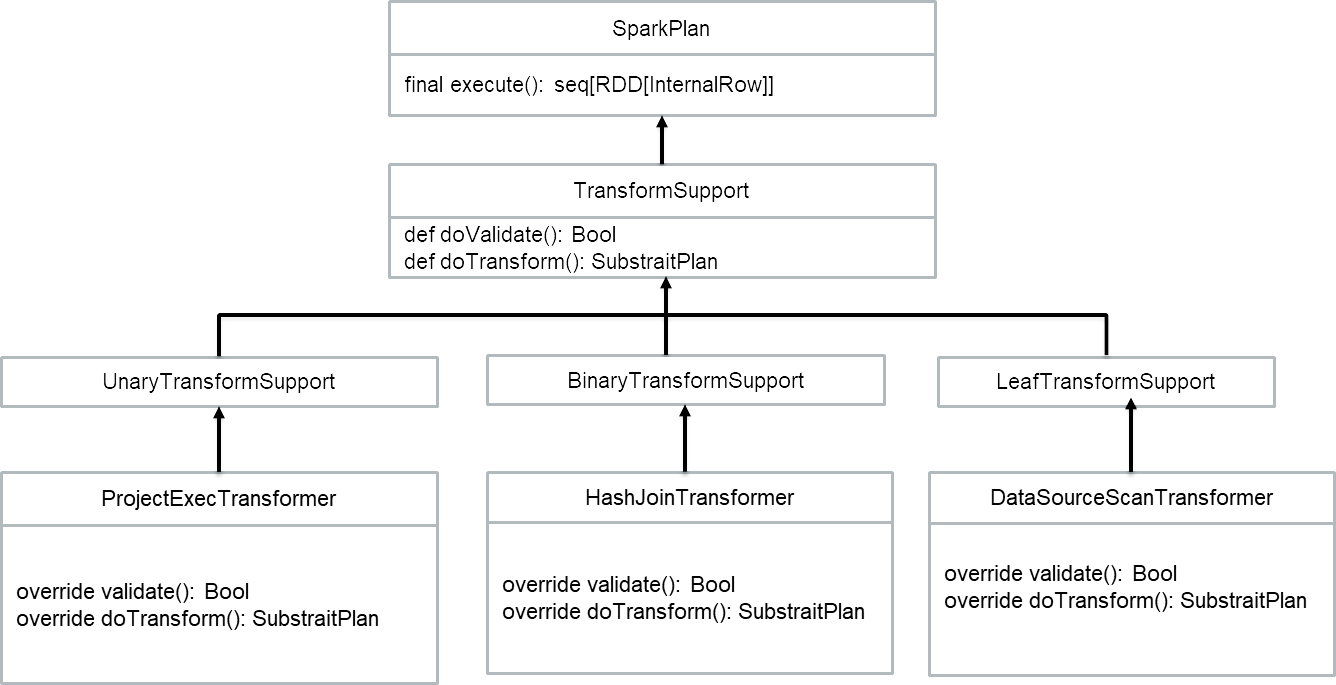
- Para integrar o mecanismo de conversão do plano Gluten no Spark, primeiro definimos uma interface chamada Suporte para Transformaçãoque herda de SparkPlan. O Suporte para Transformação interface inclui dois métodos: def validar(): Booleano para validar se este operador/expressão é compatível com código nativo e def doTransform(): SubstratePlan para realizar a conversão do plano. A seguir, definimos três interfaces – Suporte LeafTransform, UnaryTransformSupporte Suporte para transformação binária — adaptar-se a diferentes tipos de operadores. Por exemplo, ProjectExecTransformer herdará de UnaryTransformSupport, HashJoinTransformador herdará de Suporte para transformação bináriae Fonte de dadosScanTransformer herdará de Suporte LeafTransform. Dessa forma, podemos estender SparkPlan para apoiar a conversão do plano.
2. Durante o processo de validação do plano físico, passaremos o plano Substrait convertido no formato Protobuf para diferentes backends nativos para validação. Este processo inclui a verificação de assinaturas de funções e tipos de dados suportados. Se a validação for bem sucedida, retorna verdadeiro; caso contrário, retornará falso.
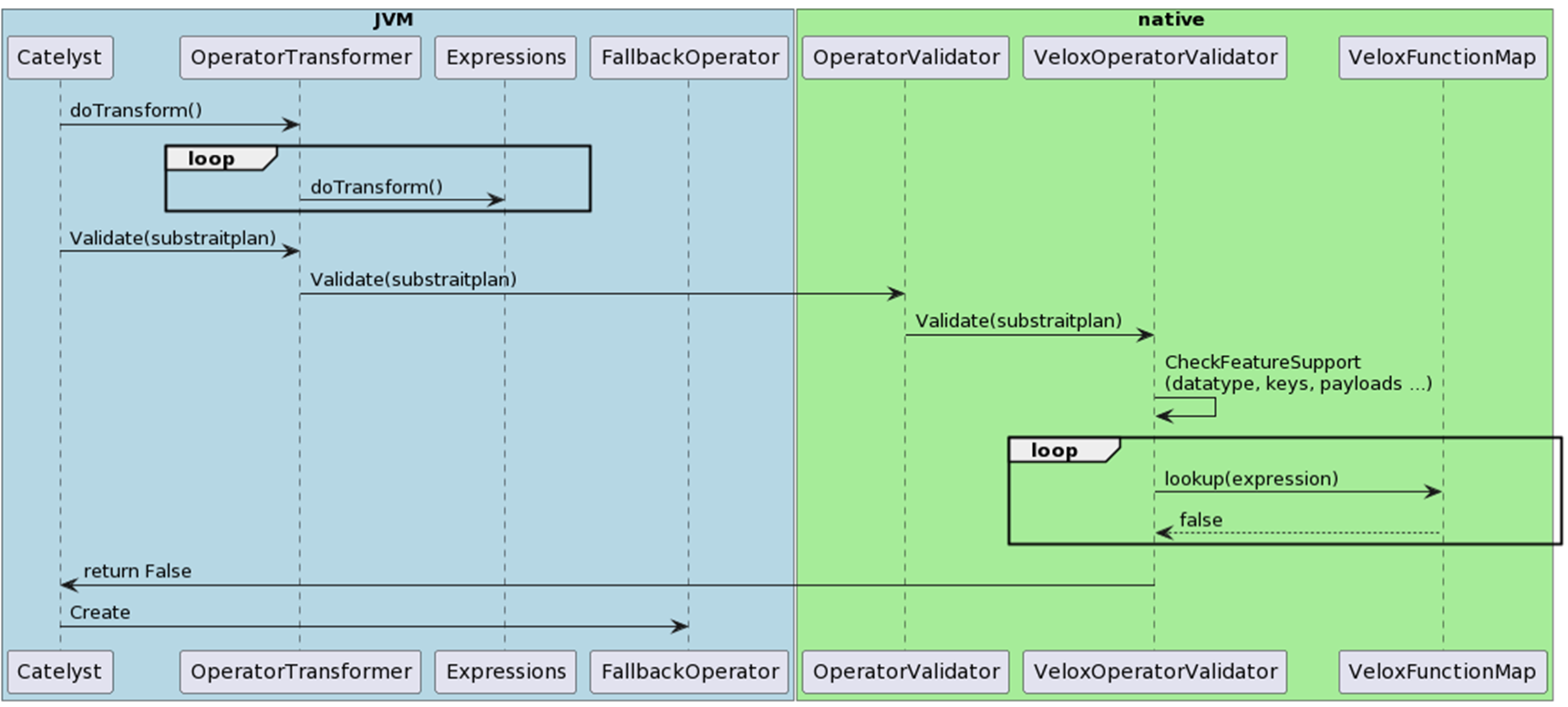
3. Se a validação falhar, continuaremos a usar os próprios operadores do Spark para executar o plano, mas neste ponto, o suporte para transformações de dados coluna para linha (C2R) e linha para coluna (R2C) é necessário. Tomando o backend Velox como exemplo, precisamos converter o formato de dados colunares do Velox para o formato UnsafeRow do Spark na transformação C2R; inversamente, na transformação R2C, convertemos o formato UnsafeRow do Spark para o formato de dados colunares do Velox.
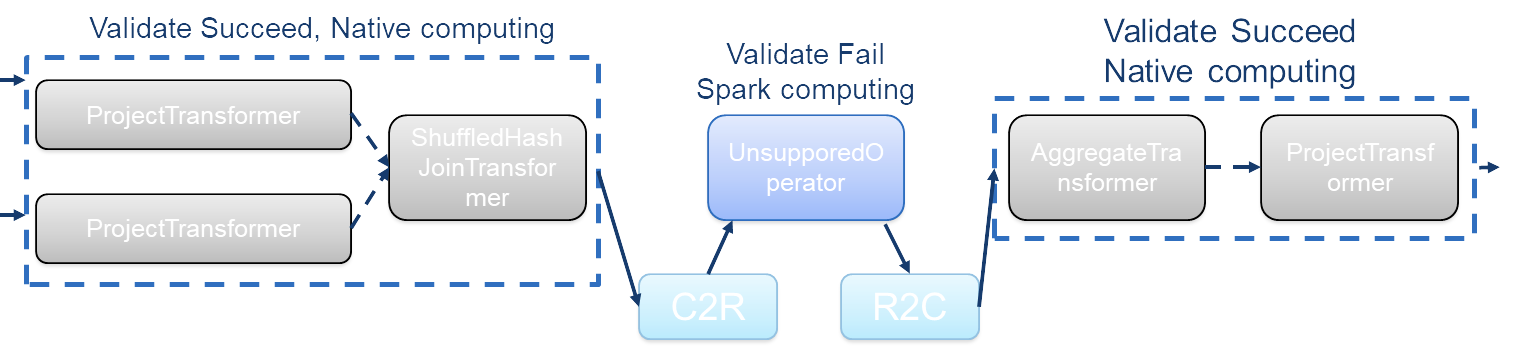
Para implementar a execução dos planos físicos do Spark em um mecanismo nativo, precisamos concluir três etapas principais: transformação do plano, validação e fallback. Dado que estas etapas envolvem modificações substanciais no Spark, decidimos focar primeiro na fase de transformação do plano. Ao utilizar o Substrait, converteremos os planos Spark em um formato comum, alcançando assim compatibilidade com vários back-ends. Após a conclusão da primeira etapa, consideraremos ainda as etapas restantes de validação e fallback.
Conclusões
Incorporamos habilmente essa metodologia de conversão no Apache Gluten, permitindo suporte contínuo para back-ends ClickHouse e Velox. Nossos esforços de integração com ambos os back-ends culminaram em um avanço substancial no desempenho. Para uma análise aprofundada das melhorias, consulte as informações fornecidas neste link. Além disso, é com grande orgulho que reconhecemos a implementação bem sucedida do Glúten por numerosos clientes nos seus ambientes de produção.
A postagem Aprimorando a flexibilidade do plano físico do Spark para permitir a execução em vários mecanismos nativos apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}
{kind=link}