A geração aumentada de recuperação (RAG) foi um grande avanço no domínio do processamento de linguagem natural (PNL). Ele otimizou muitas tarefas de PNL devido à sua simplicidade e eficiência. Ao combinar os pontos fortes dos sistemas de recuperação (bancos de dados vetoriais) e modelos generativos (LLMs), o RAG melhora significativamente o desempenho dos sistemas de inteligência artificial em áreas como geração de texto, tradução e resposta a perguntas.
A integração de bancos de dados vetoriais tem sido um componente chave na revolução do desempenho dos sistemas RAG. Vamos explorar a relação entre o RAG e os bancos de dados vetoriais e como eles trabalharam juntos para alcançar resultados tão notáveis.
Uma breve visão geral do modelo RAG
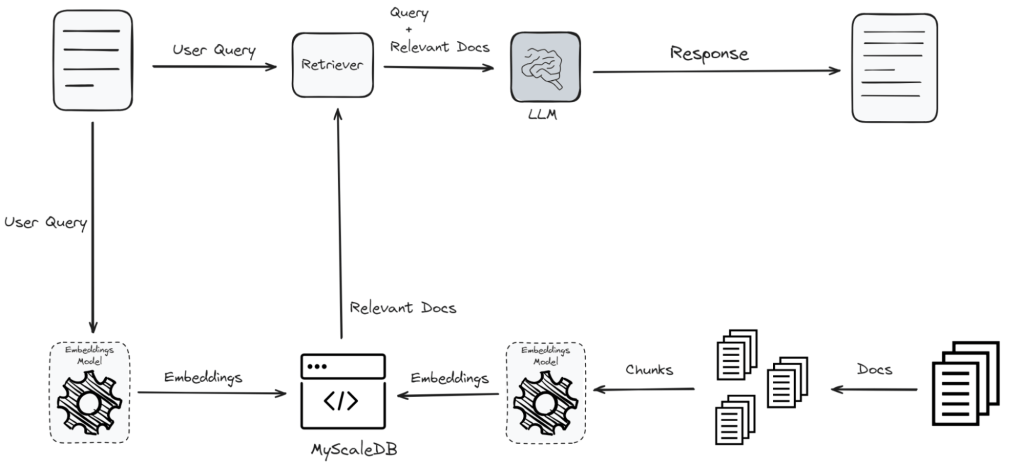
RAG é uma técnica projetada especificamente para melhorar o desempenho de grandes modelos de linguagem (LLMs). Ele recupera informações relacionadas à consulta de um usuário de bancos de dados vetoriais e fornece as informações ao LLM como referência. Este processo melhora significativamente a qualidade das respostas do LLM, tornando-as mais precisas e relevantes. A imagem a seguir mostra brevemente como funciona um modelo RAG.
Estágio de recuperação: O RAG primeiro identifica as informações mais relevantes do banco de dados vetorial usando o poder da pesquisa por similaridade. Esta etapa é a parte mais crítica de qualquer sistema RAG, pois estabelece a base para a qualidade do resultado final.
Estágio de geração: Uma vez recuperadas as informações relevantes, a consulta do usuário e os documentos recuperados são passados para o modelo LLM para produzir novo conteúdo que seja coerente, relevante e informativo.
A implementação do RAG melhora significativamente o desempenho dos LLMs, abordando limitações importantes, como imprecisões factuais, conhecimentos desatualizados e alucinações. A recuperação de informações relevantes e atualizadas de bancos de dados de vetores aumenta muito a precisão e a confiabilidade das respostas do LLM, especialmente para tarefas que exigem muito conhecimento.
Além disso, introduz um nível de transparência e rastreabilidade, permitindo aos utilizadores verificar a origem das informações fornecidas. Esta abordagem híbrida de combinar as capacidades generativas dos LLMs com o poder informativo dos sistemas de recuperação leva a aplicações de IA mais robustas e confiáveis que podem se adaptar dinamicamente a uma ampla gama de consultas e tarefas complexas.
O papel dos bancos de dados vetoriais
Um banco de dados vetorial é um tipo especializado de banco de dados projetado para armazenar e gerenciar dados na forma de vetores numéricos, conhecidos como “incorporações”. Essas incorporações codificam os significados semânticos e as informações contextuais de qualquer tipo de dados. Os dados podem ser texto, imagens ou até áudio. Os bancos de dados vetoriais armazenam esses embeddings com eficiência e fornecem recuperação rápida de embeddings por meio de uma pesquisa por similaridade. Esses recursos desempenham um papel importante em tarefas como recuperação de informações, sistemas de recomendação e busca semântica. Esses bancos de dados são particularmente úteis em aplicativos de aprendizado de máquina e IA, onde os dados são frequentemente transformados em espaços vetoriais para capturar padrões e relacionamentos complexos.
Os principais recursos dos bancos de dados vetoriais incluem:
Suporte de dados de alta dimensão: Esses bancos de dados são projetados para lidar com dados vetoriais de alta dimensão, comumente usados em modelos de aprendizado de máquina.
Pesquisa eficiente: Esses bancos de dados fornecem algoritmos de pesquisa otimizados para encontrar rapidamente os vetores mais semelhantes em um vasto conjunto de dados. A principal funcionalidade de pesquisa é a pesquisa do vizinho mais próximo, e todos os algoritmos são projetados para otimizar essa abordagem.
Escalabilidade: os bancos de dados vetoriais são projetados para lidar com grandes volumes de dados e consultas de usuários. Isso os torna adequados para conjuntos de dados crescentes e demandas crescentes.
Indexação: Esses bancos de dados geralmente usam técnicas avançadas de indexação para acelerar o processo de pesquisa e comparação de vetores.
Integração: Eles podem ser facilmente integrados a pipelines de aprendizado de máquina para fornecer recursos de recuperação de dados em tempo real.
Os bancos de dados vetoriais são um componente crucial em sistemas que aproveitam o aprendizado de máquina para tarefas como reconhecimento de imagens, análise de texto e algoritmos de recomendação, onde a capacidade de acessar e comparar rapidamente grandes conjuntos de dados vetorizados é fundamental.
Como os bancos de dados vetoriais melhoram o desempenho do RAG
Os bancos de dados vetoriais melhoram significativamente o desempenho dos sistemas RAG, otimizando vários estágios do fluxo de trabalho. Inicialmente, os dados textuais são convertidos em vetores utilizando um modelo de incorporação. Essa conversão é importante porque transforma dados textuais em um formato que pode ser armazenado e recuperado de forma eficiente com base em significados semânticos.
A força de um banco de dados vetorial está em seus métodos avançados de indexação. Depois que os dados são convertidos em vetores, eles são salvos no banco de dados de vetores usando métodos avançados de indexação, como gráficos Hierarchical Navigable Small World (HNSW) ou índices de arquivos invertidos (IVF). Esses métodos de indexação organizam os vetores de uma forma que permite uma recuperação rápida e eficiente. O processo de indexação garante que, quando uma consulta for feita, o sistema possa localizar rapidamente os vetores relevantes no vasto conjunto de dados.
Quando um usuário envia uma consulta, ela também é convertida em um vetor usando o mesmo modelo de incorporação. O banco de dados vetorial procura o cluster mais próximo com vetores semelhantes. O banco de dados vetorial procura clusters de vetores que estejam semanticamente mais próximos do vetor de consulta. Essa busca por similaridade é a base de qualquer sistema RAG ou banco de dados de vetores por meio da identificação rápida e precisa de vetores semanticamente semelhantes.
Os documentos semelhantes são então repassados ao recuperador, que combina a consulta com os documentos relevantes e os envia ao LLM para geração de resposta. A utilização de bancos de dados vetoriais garante que o recuperador trabalhe com as informações mais relevantes. Isso aumenta a precisão e a relevância da resposta gerada.
Os bancos de dados vetoriais não apenas melhoram a velocidade de recuperação, mas também lidam com grandes volumes de dados com eficiência. Essa escalabilidade é essencial para aplicações que lidam com conjuntos de dados extensos. Ao garantir uma recuperação rápida e precisa, os bancos de dados vetoriais suportam consultas em tempo real, fornecendo aos usuários respostas imediatas e relevantes.
Banco de dados de vetores especializados vs. Banco de dados de vetores SQL
Em sistemas RAG do mundo real, superar problemas de precisão de recuperação (e os gargalos de desempenho associados) requer uma maneira eficiente de combinar consultas de dados estruturados, vetoriais e de palavras-chave.
Alguns bancos de dados de vetores (como Pinecone, Weaviate e Milvus) são projetados especificamente para pesquisa de vetores desde o início. Eles apresentam bom desempenho nesta área, mas têm capacidades gerais de gerenciamento de dados um tanto limitadas.
Capacidades de consulta limitadas: fornecem suporte limitado para consultas complexas, incluindo aquelas com múltiplas condições, junções e agregações, devido ao armazenamento restrito de metadados.
Restrições de tipo de dados: projetados principalmente para armazenamento vetorial e mínimo de metadados, eles não têm flexibilidade para lidar com vários tipos de dados, como números inteiros, strings e datas.
Os bancos de dados vetoriais SQL representam uma fusão avançada das funcionalidades tradicionais dos bancos de dados SQL com os recursos especializados dos bancos de dados vetoriais. Esses sistemas integram algoritmos de busca vetorial diretamente no ambiente de dados estruturados, permitindo o gerenciamento de dados vetoriais e estruturados dentro de uma estrutura de banco de dados unificada.
Essa integração oferece várias vantagens importantes:
Comunicação simplificada entre tipos de dados.
Filtragem flexível baseada em metadados.
Suporte para execução de consultas SQL e vetoriais.
Compatibilidade com ferramentas existentes projetadas para bancos de dados de uso geral.
Entre os bancos de dados vetoriais SQL, MyScaleDB é uma opção de código aberto que amplia os recursos do ClickHouse. Ele combina perfeitamente o gerenciamento estruturado de dados com operações vetoriais, otimizando o desempenho para interações de dados complexas e aumentando a eficiência dos sistemas RAG. Com pesquisas filtradas, o MyScaleDB filtra dados com eficiência em grandes conjuntos de dados com base em atributos específicos antes de realizar pesquisas vetoriais, garantindo uma recuperação rápida e precisa.
Conclusão
Os bancos de dados vetoriais aprimoraram bastante os sistemas RAG, otimizando a recuperação e o processamento de dados. Esses bancos de dados permitem armazenamento eficiente e recuperação rápida com base no significado semântico. Métodos avançados de indexação como HNSW e FIV garantem que os dados relevantes sejam localizados rapidamente, aumentando a precisão das respostas. Além disso, os bancos de dados vetoriais lidam com grandes volumes de dados, fornecendo a escalabilidade necessária para consultas em tempo real e respostas imediatas do usuário.
Um banco de dados vetorial SQL leva essas vantagens ainda mais ao integrar a pesquisa vetorial com SQL. Isso permite interações de dados complexas e precisas. Essa integração simplifica o desenvolvimento e reduz a curva de aprendizado para a construção de aplicações RAG robustas.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Usama Jamil, defensor do desenvolvedor na MyScale, traz consigo uma vasta experiência e um profundo interesse em ciência de dados. Com paixão por explorar novas tendências no domínio de IA/ML, Usama se esforça para tornar conceitos complexos acessíveis a…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.







{kind=link}
{kind=link}
{kind=link}