No mundo atual, orientado por dados, a pesquisa rápida e precisa em grandes quantidades de dados não estruturados é crucial para alimentar aplicações de IA de ponta. Desde IA generativa e pesquisa de similaridade até mecanismos de recomendação e descoberta virtual de medicamentos, os bancos de dados de vetores surgiram como a tecnologia de base que permite esses recursos avançados. No entanto, a demanda insaciável por indexação em tempo real e alto rendimento continuou a ampliar os limites do que é possível com soluções tradicionais baseadas em CPU.
Indexação em tempo real: Os bancos de dados vetoriais geralmente precisam ingerir e indexar novos dados vetoriais continuamente e em alta velocidade. Os recursos de indexação em tempo real são essenciais para manter o banco de dados atualizado com os dados mais recentes, sem criar gargalos ou atrasos.
Alto rendimento: Muitas aplicações que utilizam bancos de dados vetoriais, como sistemas de recomendação, mecanismos de pesquisa semântica e detecção de anomalias, exigem processamento de consultas em tempo real ou quase em tempo real. O alto rendimento permite que os bancos de dados vetoriais lidem com um grande volume de consultas recebidas simultaneamente, fornecendo respostas de baixa latência aos usuários finais ou serviços.
No centro dos bancos de dados vetoriais está um conjunto central de operações vetoriais, como cálculos de similaridade e operações matriciais, que são altamente paralelizáveis e computacionalmente intensivos. Com sua arquitetura massivamente paralela composta por milhares de núcleos capazes de executar vários threads simultaneamente, as GPUs são um mecanismo computacional ideal para acelerar essas operações.
Aproveitando a aceleração da GPU
Para enfrentar esses desafios, a NVIDIA desenvolveu o CUDA-Accelerated Graph Index for Vector Retrieval (CAGRA), uma estrutura acelerada por GPU que aproveita os recursos de alto desempenho das GPUs para fornecer rendimento excepcional para cargas de trabalho de bancos de dados vetoriais.
No NVIDIA GTC 2024, Zilliz e NVIDIA revelaram o Milvus 2.4, o primeiro banco de dados vetorial do mundo acelerado por poderosas capacidades de indexação e pesquisa de GPU. Milvus é um sistema de banco de dados vetorial de código aberto desenvolvido para pesquisa de similaridade vetorial em grande escala e cargas de trabalho de IA. Criado inicialmente por Zilliz, um inovador no mundo do gerenciamento de dados não estruturados e tecnologia de banco de dados vetorial, o Milvus fez sua estreia em 2019. Para incentivar o amplo envolvimento e adoção da comunidade, ele é hospedado pela Linux Foundation desde 2020.
Milvus 2.4 aproveita o poder de computação massivamente paralelo das GPUs NVIDIA e o novo CAGRA da biblioteca RAPIDS cuVS. Essa aceleração de GPU permite ganhos significativos de desempenho no Milvus: os benchmarks demonstram desempenho de pesquisa vetorial até 50x mais rápido do que índices baseados em CPU de última geração, como Hierarchical Navigable Small Worlds (HNSW).
Explorando a arquitetura Milvus 2.4
Milvus foi projetado para ambientes nativos de nuvem e segue uma filosofia de design modular. Ele separa o sistema em vários componentes e camadas envolvidas no tratamento de solicitações de clientes, processamento de dados e gerenciamento de armazenamento e recuperação de dados vetoriais. Este design modular permite que Milvus atualize ou melhore a implementação de módulos específicos sem alterar suas interfaces. Essa modularidade torna relativamente fácil incorporar suporte de aceleração de GPU ao Milvus.
A arquitetura Milvus 2.4
A arquitetura modular inclui componentes como coordenador, camada de acesso, fila de mensagens, nó de trabalho e camadas de armazenamento. O Nó de Trabalho é subdividido em Nós de Dados, Nós de Consulta e Nós de Índice. Os nós de índice são responsáveis pela construção de índices, enquanto os nós de consulta cuidam da execução da consulta.
Para aproveitar os benefícios da aceleração de GPU, o CAGRA está integrado aos nós de índice e consulta da Milvus. Essa integração permite transferir tarefas computacionalmente intensivas, como construção de índices e processamento de consultas, para GPUs, aproveitando seus recursos de processamento paralelo.
Dentro dos nós de índice, o suporte CAGRA foi incorporado aos algoritmos de construção de índices, permitindo a construção e o gerenciamento eficientes de índices vetoriais de alta dimensão em hardware de GPU. Essa aceleração reduz significativamente o tempo e os recursos necessários para indexar conjuntos de dados vetoriais em grande escala.
Da mesma forma, CAGRA é usado nos nós de consulta para acelerar a execução de pesquisas complexas de similaridade vetorial. Ao aproveitar o poder de processamento da GPU, o Milvus pode realizar cálculos de distância de alta dimensão e pesquisas de similaridade em velocidades sem precedentes, resultando em tempos de resposta de consulta mais rápidos e melhor rendimento geral.
Avaliando Desempenho
Para esta avaliação, utilizamos três tipos de instância disponíveis publicamente na AWS:
m6id.2xgrande: Este tipo de instância é alimentado pela CPU Intel Xeon 8375C.
g4dn.2xgrande: Esta instância acelerada por GPU está equipada com uma GPU NVIDIA T4.
g5.2xgrande: Este tipo de instância apresenta a GPU NVIDIA A10G.
Ao aproveitar esses diversos tipos de instâncias, pretendemos avaliar o desempenho e a eficiência do Milvus com integração CAGRA em diferentes configurações de hardware. A instância m6id.2xlarge serviu como base para o desempenho baseado em CPU, enquanto as instâncias g4dn.2xlarge e g5.2xlarge nos permitiram avaliar os benefícios da aceleração de GPU usando as GPUs NVIDIA T4 e A10G, respectivamente.
Ambientes de avaliação, AWS
Usamos dois conjuntos de dados vetoriais disponíveis publicamente no VectorDBBench:
OpenAI-500K-1536-dim: Este conjunto de dados consiste em 500.000 vetores, cada um com dimensionalidade de 1.536. É derivado do modelo de linguagem OpenAI.
Cohere-1M-768-dim: Este conjunto de dados contém 1 milhão de vetores, cada um com dimensionalidade de 768. Ele é gerado a partir do modelo de linguagem Cohere.
Esses conjuntos de dados foram escolhidos especificamente para avaliar o desempenho e a escalabilidade do Milvus com integração CAGRA sob diferentes volumes de dados e dimensionalidades vetoriais. O conjunto de dados OpenAI-500K-1536-dim permite avaliar o desempenho do sistema com um conjunto de dados moderadamente grande de vetores de dimensões extremamente altas. Em contraste, o conjunto de dados Cohere-1M-768-dim testa a capacidade do sistema de lidar com volumes maiores de vetores de dimensões moderadamente altas.
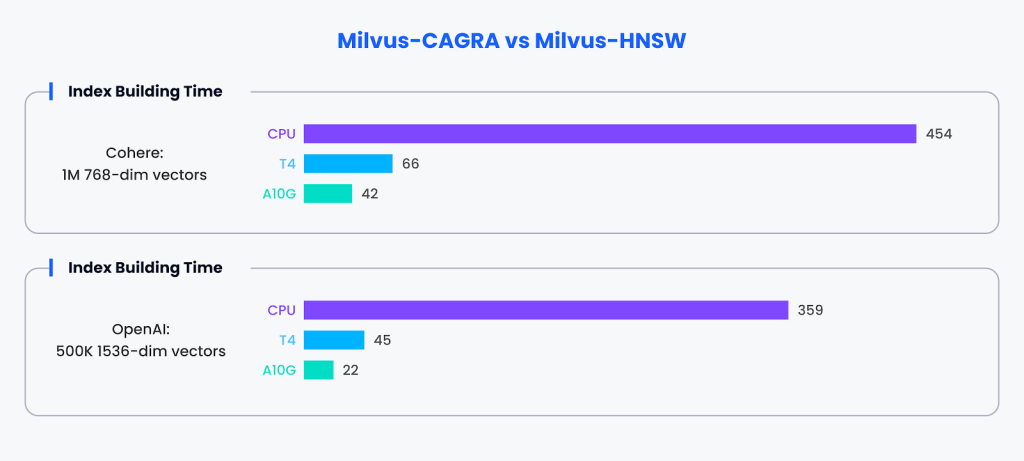
Tempo de construção do índice
Comparamos o tempo de construção do índice entre Milvus com a estrutura de aceleração de GPU CAGRA e a implementação padrão do Milvus usando o índice HNSW em CPUs.
Para o conjunto de dados Cohere-1M-768-dim, os tempos de construção do índice são:
CPU (HNSW): 454 segundos
GPU T4 (CAGRA): 66 segundos
GPU A10G (CAGRA): 42 segundos
Para o conjunto de dados OpenAI-500K-1536-dim, os tempos de construção do índice são:
CPU (HNSW): 359 segundos
GPU T4 (CAGRA): 45 segundos
GPU A10G (CAGRA): 22 segundos
Os resultados mostram claramente que CAGRA, a estrutura acelerada por GPU, supera significativamente a construção de índice HNSW baseado em CPU, com a GPU A10G sendo a mais rápida em ambos os conjuntos de dados. A aceleração de GPU fornecida pelo CAGRA reduz o tempo de construção de índice em até uma ordem de grandeza em comparação com a implementação de CPU, demonstrando os benefícios de aproveitar o paralelismo de GPU para operações vetoriais computacionalmente intensivas, como construção de índice.
Taxa de transferência
Também comparamos o desempenho entre Milvus com a estrutura de aceleração de GPU CAGRA e a implementação padrão Milvus usando o índice HNSW em CPUs. A métrica que avaliamos é consultas por segundo (QPS), que mede o rendimento da execução da consulta.
Variamos o tamanho do lote, representando o número de consultas processadas simultaneamente, de 1 a 100 durante o processo de avaliação. Essa ampla variedade de tamanhos de lote nos permitiu realizar uma avaliação realista e completa, avaliando o desempenho em diferentes cenários de carga de trabalho de consulta.
Avaliando o rendimento
Os gráficos mostram que:
Para um tamanho de lote de 1, o T4 é 6,4x a 6,7x mais rápido que a CPU, e o A10G é 8,3x a 9x mais rápido.
Quando o tamanho do lote aumenta para 10, a melhoria de desempenho é mais significativa: T4 é 16,8x a 18,7x mais rápido e A100 é 25,8x a 29,9x mais rápido.
Com um tamanho de lote de 100, o ganho de desempenho continua a crescer: T4 é 21,9x a 23,3x mais rápido e A100 é 48,9x a 49,2x mais rápido.
Os resultados demonstram ganhos substanciais de desempenho ao aproveitar a aceleração da GPU para consultas de bancos de dados vetoriais, especialmente para lotes maiores e dados de dimensões mais altas. Milvus com CAGRA desbloqueia os recursos de processamento paralelo das GPUs, permitindo melhorias significativas no rendimento e tornando-o adequado para cargas de trabalho exigentes de bancos de dados vetoriais.
Novas trilhas em chamas
Os benchmarks indicam que a integração da estrutura de aceleração de GPU CAGRA da NVIDIA no Milvus 2.4 representa uma grande conquista em bancos de dados vetoriais. O poder de computação massivamente paralelo das GPUs aumentou significativamente o desempenho das operações de indexação e pesquisa de vetores, melhorando o processamento de dados vetoriais de alto rendimento e em tempo real.
A colaboração Milvus 2.4 entre Zilliz e NVIDIA exemplifica o poder da inovação aberta e do desenvolvimento orientado pela comunidade, trazendo aceleração de GPU para bancos de dados vetoriais.
O Milvus 2.4 de código aberto já está disponível, e as empresas que procuram um serviço de banco de dados vetorial totalmente gerenciado podem esperar a aceleração da GPU chegando ao Zilliz Cloud ainda este ano. Zilliz Cloud oferece uma experiência perfeita para implantação e dimensionamento do Milvus nos principais provedores de nuvem, como AWS, Google Cloud Platform e Azure, sem sobrecarga operacional.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Charles Xie é o fundador e CEO da Zilliz, uma empresa dedicada ao desenvolvimento de uma plataforma de dados não estruturados de ponta para aplicações de IA. Ele é o criador do Milvus, um banco de dados vetorial de código aberto líder que é usado por mais de 5.000 empresas…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.







{kind=link}
{kind=link}
{kind=link}