

Paul é engenheiro de software sênior, defensor independente do desenvolvedor e redator técnico. Mais informações de Paul podem ser encontradas em seu site, paulie.dev.
Leia mais de Paul Scanlon


Neste artigo, mostrarei como criei uma ação agendada do GitHub que se conecta ao meu banco de dados Neon PostgreSQL, cria um backup usando pg_dump e carrega-o em um AWS S3 Bucket todas as noites à meia-noite (ET).
Existem três componentes principais para criar esse tipo de backup agendado:
Aqui está um link para a ação finalizada que estou usando para fazer backup do banco de dados usado pelo meu site. The Action faz backup do meu banco de dados Neon todas as noites à meia-noite e exclui todos os anteriores .sql.gz arquivos do bucket S3.
Posteriormente neste artigo, explicarei o que cada uma das etapas faz e onde você precisará fazer alterações para que funcione com seu banco de dados, repositório GitHub e credenciais AWS.
Mas primeiro…
Existem três partes na configuração da AWS:
Um provedor de identidade (IdP) OIDC (OpenID Connect) na AWS é um serviço de terceiros que lida com autenticação. O GitHub deve ser adicionado como um provedor de identidade para permitir que a ação use suas credenciais da AWS.
Para criar um novo provedor de identidade, navegue até IAM > Gerenciamento de acesso > Provedores de identidade e clique em Adicionar provedor.
Na próxima tela, selecione OpenID Connect e adicione o seguinte aos campos URL do provedor e Público:
sts.amazonaws.comQuando terminar, clique em Adicionar provedor.
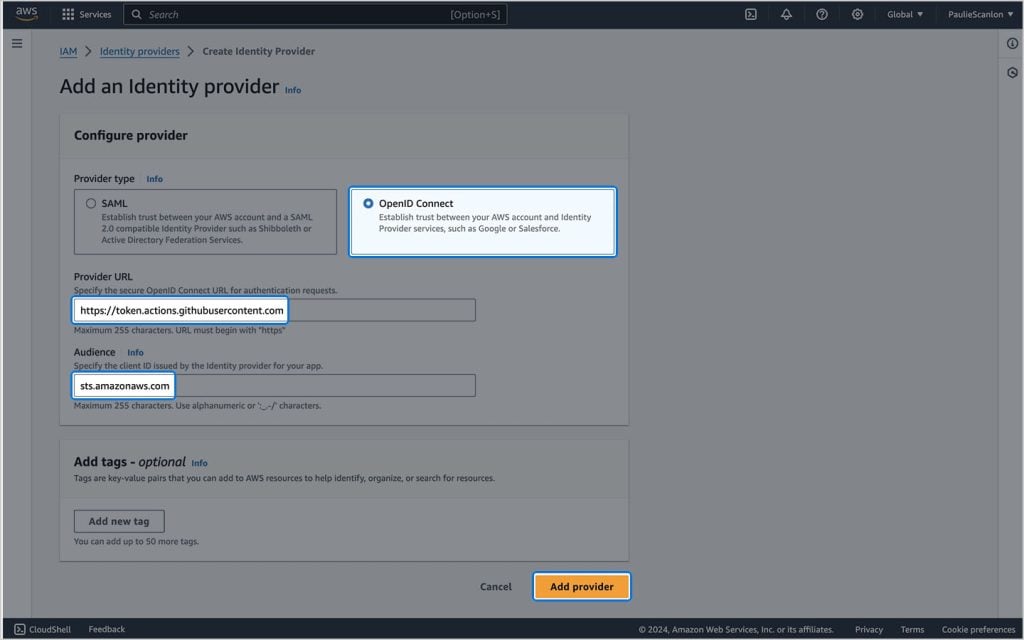
Agora você verá que esse provedor está visível na lista em IAM > Gerenciamento de acesso > Provedores de identidade.
Uma função é uma identidade que você pode assumir para obter credenciais de segurança temporárias para tarefas ou ações específicas na AWS. As funções são usadas para delegar permissões e conceder acesso aos serviços da AWS sem a necessidade de credenciais como senhas ou chaves de acesso.
Para criar um novo provedor de identidade, navegue até IAM > Gerenciamento de acesso > Funções e clique em Criar função.
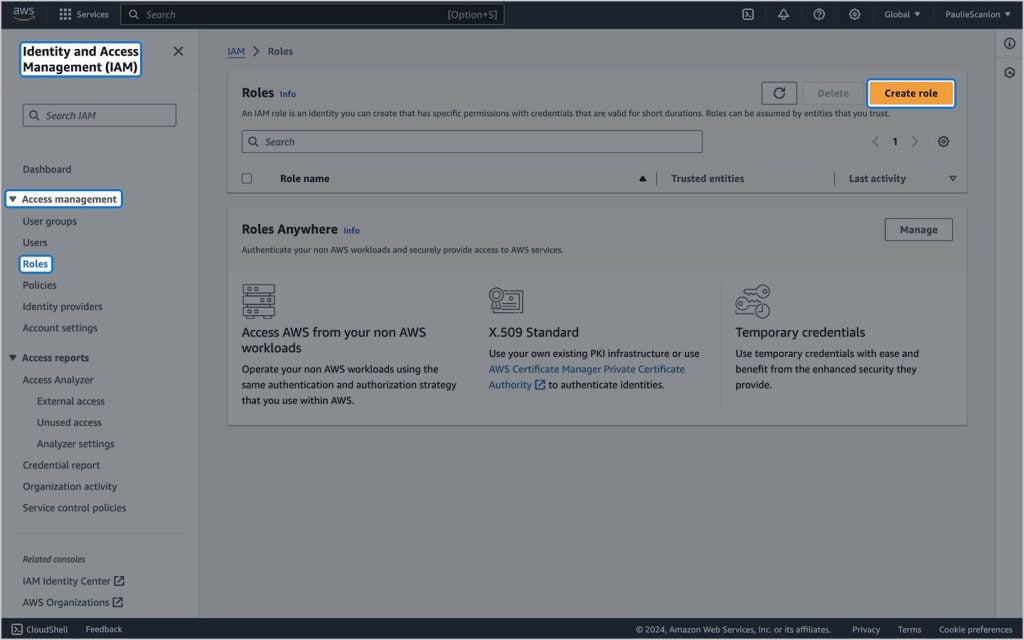
Na próxima tela, crie uma identidade confiável para a função.
Nesta tela selecione Identidade Webe selecione token.actions.githubusercontent.com de Identidade Web menu suspenso.
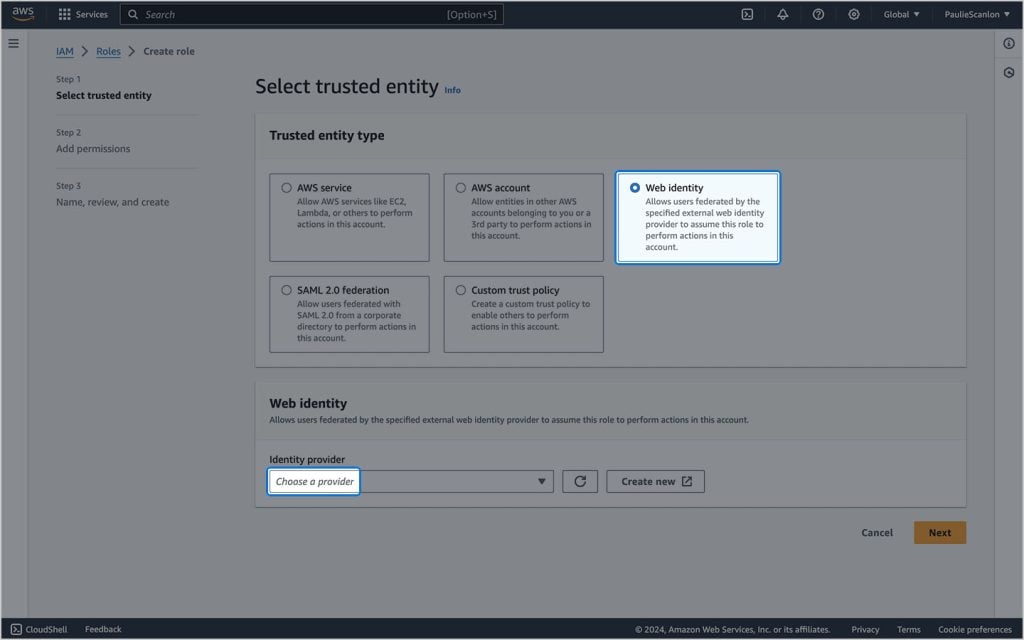
Depois de selecionar o Provedor de Identidade, você verá vários campos para preencher. Selecione sts.amazonaws.com no menu suspenso Público e preencha os detalhes do repositório GitHub de acordo com seus requisitos.
Quando terminar, clique em Próximo.
Para referência, as opções mostradas na imagem abaixo são para o seguinte repositório: https://github.com/PaulieScanlon/paulie-dev-2023
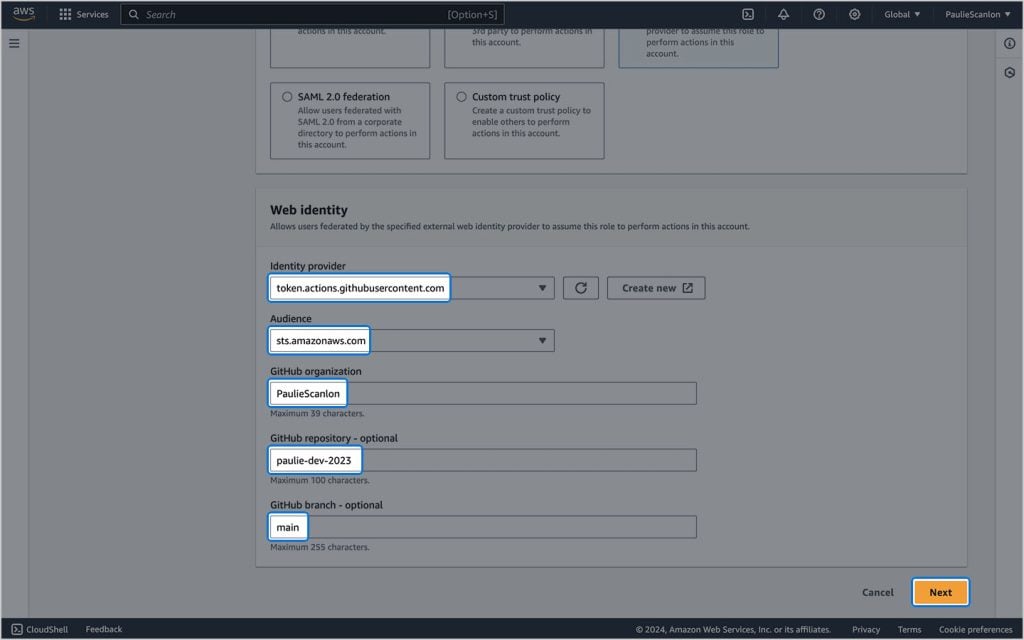
Você pode pular a seleção de qualquer coisa nesta tela e clicar Próximo continuar.
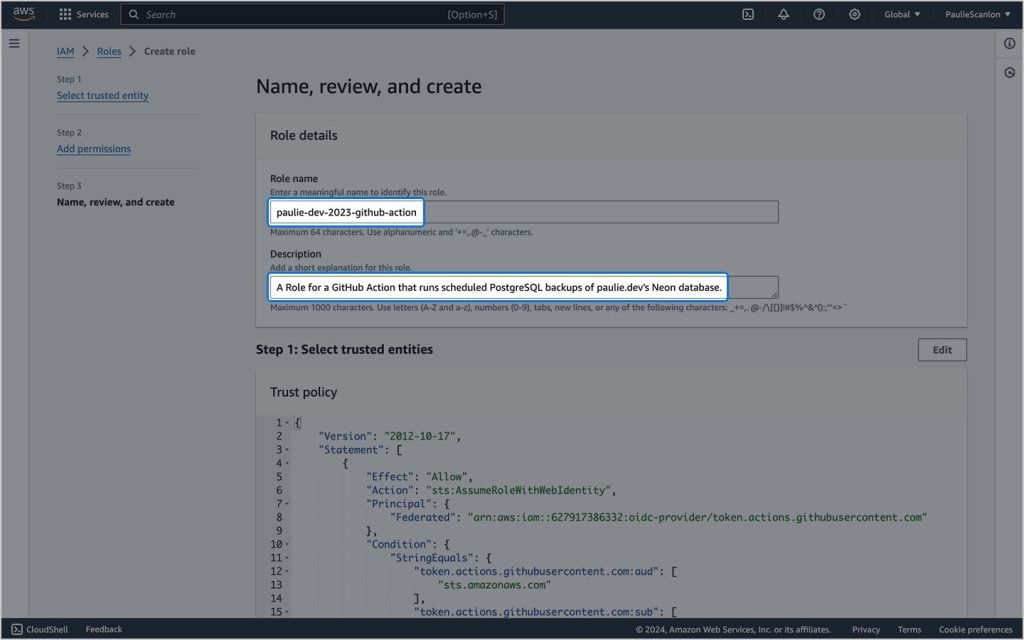
Nesta tela, dê um nome e uma descrição à função. Você usará o nome da função no código da ação do GitHub (eu nomeei o meu, paulie-dev-2023-github-action). Considere nomear a função especificamente para evitar confusão no futuro.
Quando estiver pronto, clique Criar função.
Existem duas partes na criação de um bucket S3:
Os buckets AWS S3 (Amazon Simple Storage Service) são contêineres de armazenamento usados para armazenar objetos no serviço de armazenamento em nuvem da Amazon. Um bucket S3 pode armazenar qualquer quantidade de dados, desde arquivos e documentos até imagens e vídeos ou, no caso de backup de banco de dados, um .gz (GNUzip).
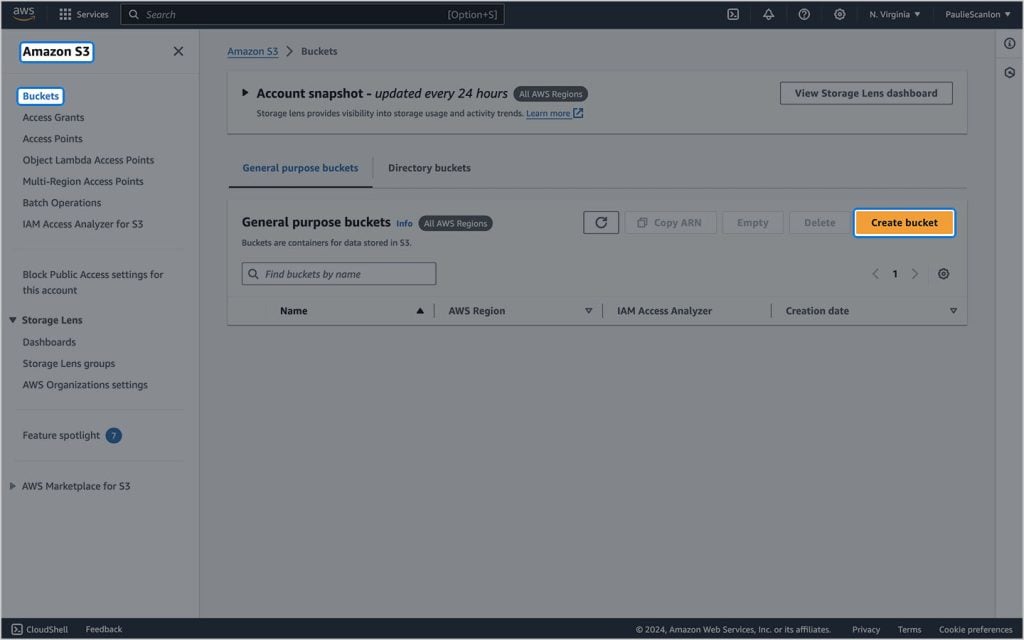
Para criar um novo Bucket, navegue até S3 > Buckets e clique em Crie um balde.
Na próxima tela, selecione Propósito geral para o tipo de balde e, em seguida, dê um nome ao seu balde.
A coisa mais importante a notar nesta tela é qual região você está criando o bucket para.
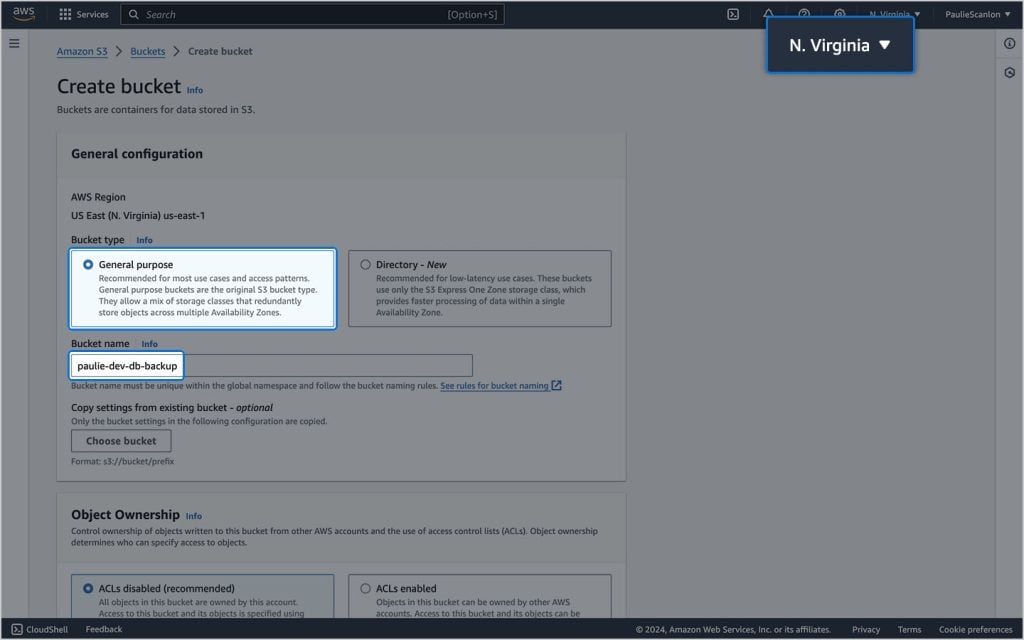
Conforme mencionado, meu provedor de banco de dados é o Neon, que implanta bancos de dados na AWS. No meu caso, é importante criar meu bucket S3 na mesma região do meu banco de dados (us-east-1 N. Virginia) para não incorrer em cobranças de saída ao realizar backups. Isso ocorre porque ao realizar um dump do banco de dados, você extrai uma grande quantidade de dados do armazenamento; e ao carregá-lo em um bucket S3, você insere uma grande quantidade de dados de volta no armazenamento. Ao garantir que as regiões da AWS sejam iguais, os dados não apenas nunca sairão da rede da AWS, mas também nunca sairão da região da AWS — e, portanto, sem cobranças de saída e sem custos.
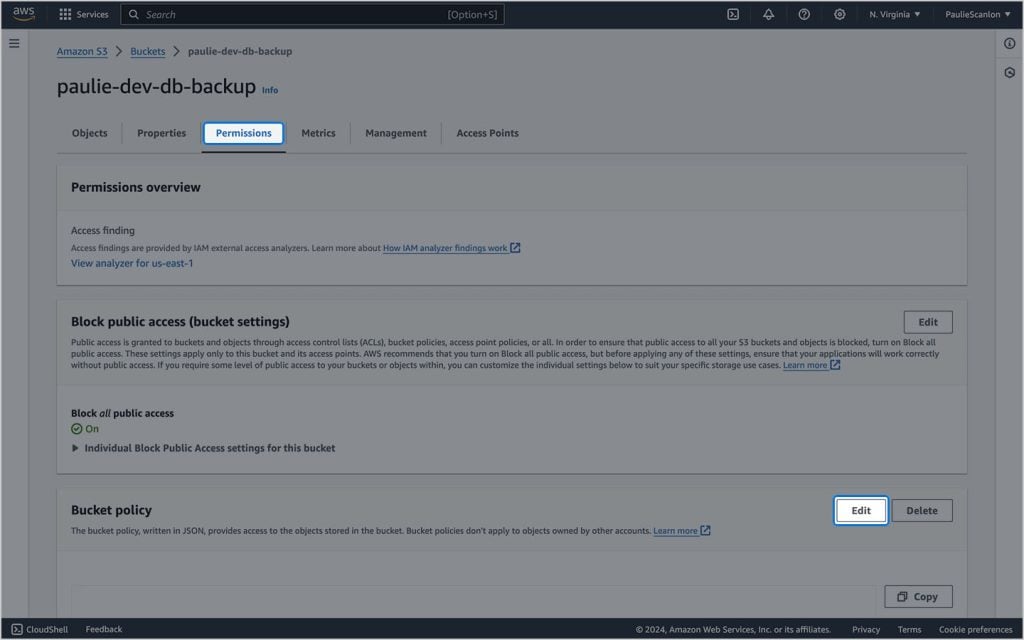
Para garantir que a função usada na ação do GitHub possa executar ações no bucket S3, você precisará atualizar a política do bucket.
Selecione seu bucket, selecione a guia Permissões e clique em Editar.
Agora você pode adicionar a política a seguir, que concede à função que você criou anteriormente acesso para executar ações S3 List, Get, Put e Delete. Você precisará listar o nome do bucket duas vezes em Recursos – um sem a barra final, outro com uma barra final e curinga. Sem os dois links, a Action irá falhar (não sei porquê, desculpe).
No trecho acima, substitua o nome da função (paulie-dev-2023-github-action) pelo nome da sua função e substitua o nome do bucket S3 (paulie-dev-db-backup) pelo nome do seu bucket S3.
Quando estiver pronto, clique em Salvar alterações.
Há uma série de variáveis sensíveis usadas no GitHub Action. No meu caso, o repositório é público e naturalmente não quero revelá-los no código da Action. Para evitar isso, estou usando GitHub Secrets.
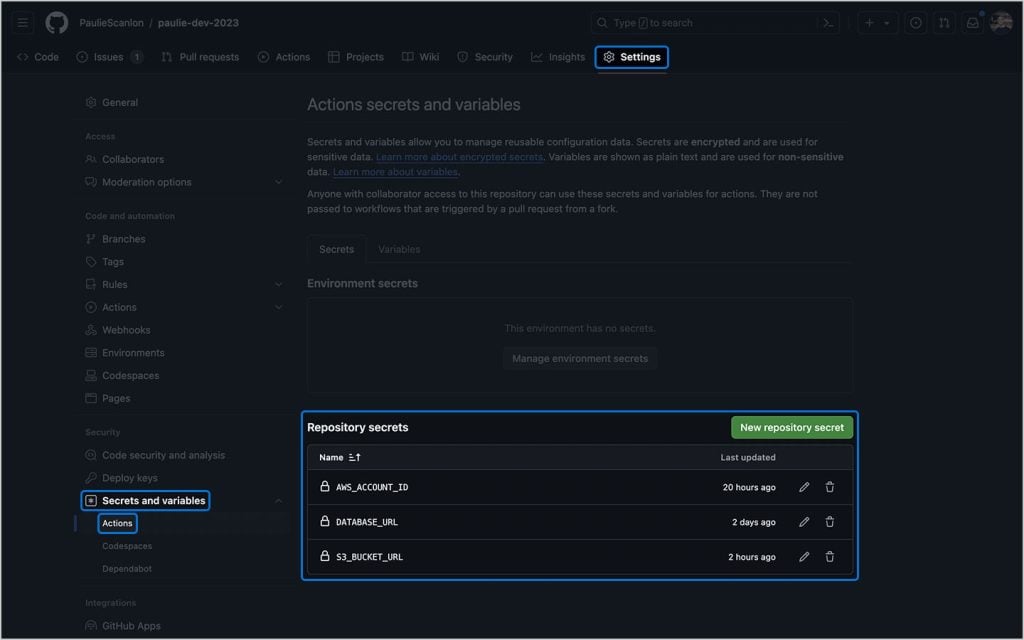
Para fazer o mesmo em sua conta GitHub, navegue até Configurações > Segredos e variáveis > Ações e adicione as seguintes variáveis.
AWS_ACCOUNT_ID
DATABASE_URL
S3_BUCKET_URL
Com a função da AWS, o bucket S3 do provedor de identidade, a política do bucket S3 e os segredos do GitHub configurados, agora você pode criar a ação do GitHub.
No seu repositório, crie um novo diretório e nomeie-o .github. Dentro deste diretório, crie outro diretório e nomeie-o workflows. Em seguida, crie um novo arquivo (chamei o meu db-backup.yml).
Adicione o seguinte código ao .yml arquivo. As alterações que você pode precisar fazer são para PG_VERSION (que é a versão PostgreSQL do seu banco de dados) e o AWS_REGION (a região do balde S3).
Você também pode querer renomear a ação. O meu tem nome Backup de néon | paulie-dev (us-east-1) e o trabalho que nomeei backup de banco de dados.
Abaixo estão cada uma das etapas contidas na Ação, juntamente com uma explicação sobre o que cada uma faz.
workflow_dispatch é um evento no GitHub Actions que permite acionar manualmente um fluxo de trabalho executado por meio da interface do usuário do GitHub Actions e é particularmente útil para fins de desenvolvimento e teste.
Este será o nome do trabalho executado na ação.
id-token: write concede permissão para escrever tokens OIDC, permitindo que o trabalho seja autenticado com serviços externos, por exemplo, AWS.
Essas variáveis são uma combinação de segredos do GitHub e variáveis que não são confidenciais, mas são usadas no código da ação.
Estou instalando o PostgreSQL a partir de um repositório Apt, que contém o pacote PostgreSQL relevante adequado para uso em ambientes Ubuntu. O PG_VERSION A variável de ambiente é usada no comando de instalação para garantir que estou instalando o PostgreSQL versão 16.
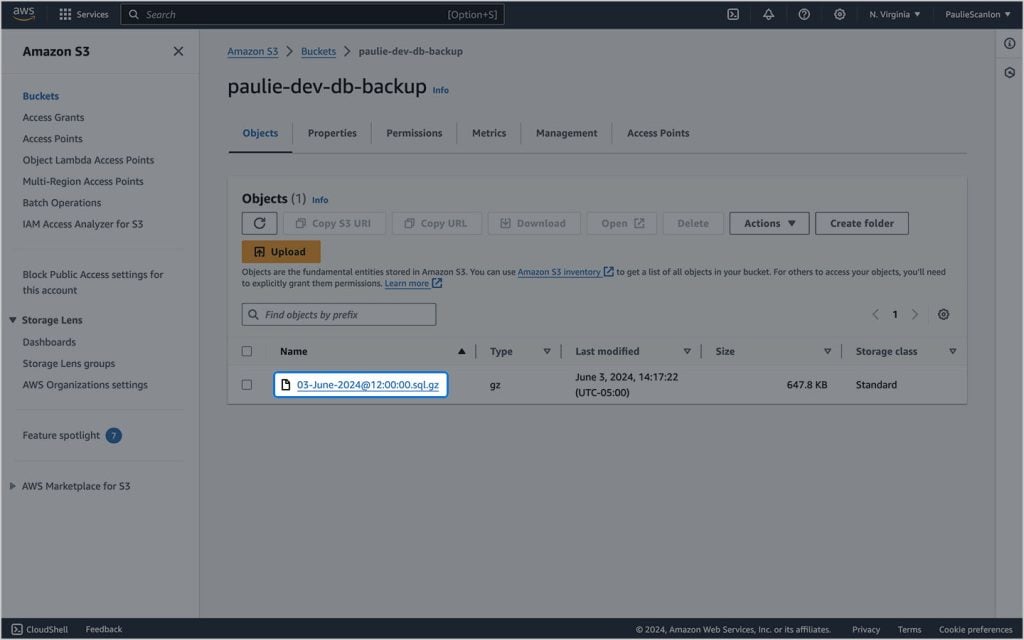
Para criar backups com uma data como parte do nome do arquivo, criei uma etapa que irá criar um carimbo de data/hora e salvá-lo no ambiente da Action. Posteriormente, posso me referir a esse valor usando env.TIMESTAMP. Aqui está um recurso útil para entender as opções de formato de carimbo de data/hora Unix: Imprima ou defina a data e hora do sistema.
Usar a mesma formatação que usei resultaria em um novo arquivo chamado algo assim: 03-June-2024@19:17:13.sql.gz
Esta etapa foi realmente muito frustrante. Para garantir que você está usando a versão do PostgreSQL instalada (no meu caso 16), preciso acessar o pg_dump diretamente dos binários. A não inclusão deste caminho resulta na tentativa da Action de usar uma versão incorreta do PostgreSQL.
Estou usando a ação configure-aws-credentials da AWS para configurar as credenciais necessárias para que a ação do GitHub interaja com os serviços da AWS, usando a função definida anteriormente.
Esta etapa é opcional e esvaziará o bucket S3 antes de gravar um novo arquivo. No meu caso, não preciso de mais do que o último backup – mas você pode querer continuar e salvar todos os backups anteriores. Nesse caso, você pode remover esta etapa com segurança. Você também pode querer remover s3:ListBucket, s3:GetObject e s3:DeleteObject da lista de ações na política do bucket S3.
Finalmente, o upload para S3. Muito simplesmente, usando o AWS cp comando eu copio o recém-criado .sql.gz arquivo e carregue-o no S3_BUCKET_URL.
E é isso. Agora tenho uma ação agendada no GitHub que é executada todas as noites à meia-noite, que executa um backup completo dos dados e do esquema do meu banco de dados Neon PostgreSQL e os carrega em um balde S3 para proteção – coisa adorável!
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER



{kind=link}
{kind=link}
{kind=link}