
Como RapidAI usa Edge, Kubernetes e IA para impulsionar o tratamento de AVC
15 de março de 2024
Python: se você não conhece declarações condicionais, leia isto
15 de março de 2024
Vector Search é um componente da plataforma Vertex AI do Google Cloud e permite a pesquisa de bilhões de itens semanticamente semelhantes ou relacionados, aproveitando o poder dos serviços de correspondência de similaridade vetorial. Esses recursos têm uma ampla gama de aplicações, incluindo mecanismos de recomendação, mecanismos de pesquisa, chatbots e classificação de texto, tornando-os uma ferramenta versátil para empresas e desenvolvedores. É um dos principais blocos de construção da estrutura Retrieval Augmented Generation (RAG).
Neste tutorial prático, exploraremos primeiro como gerar embeddings para um PDF e armazená-los em um Vertex AI Vector Search Index. Depois disso, aproveitaremos os recursos de pesquisa semântica do Gemini para implementar o RAG.
Parte 1: gerar embeddings e armazená-los em um índice de pesquisa vetorial Vertex AI
O processo de uso do Vector Search para correspondência semântica envolve várias etapas:
- Gerar uma incorporação: primeiro, crie representações de incorporação de itens fora do Vector Search ou use Generative AI no Vertex AI para criar incorporações.
- Carregar incorporação para armazenamento em nuvem: faça upload da sua incorporação no Cloud Storage para torná-la acessível ao serviço Vector Search.
- Inserir na pesquisa vetorial: conecte seus embeddings ao Vector Search criando um índice a partir de seu embedding, que pode então ser implantado em um endpoint de índice para consulta.
Para este caso de uso, usaremos o manual do funcionário de uma empresa fictícia chamada Lakeside Bicycles. O objetivo final é construir um chatbot para que os funcionários recuperem as políticas mencionadas neste documento.

Comece habilitando as APIs do Google Cloud para os serviços que usaremos.
gcloud services enable compute.googleapis.com aiplatform.googleapis.com storage.googleapis.com
Faça login no GCP e armazene as credenciais em cache localmente.
gcloud auth application-default login
Crie um requirements.txt com o conteúdo abaixo e instale as dependências em um ambiente virtual Python.
pypdf2 google-cloud-storage google-cloud-aiplatform jupyter
python -m venv venv source venv/bin/activate
pip install -r requirements.txt jupyter notebook
Agora estamos prontos para importar os módulos. Inicie um novo Jupyter Notebook e adicione os trechos de código abaixo:
from google.cloud import storage from vertexai.language_models import TextEmbeddingModel from google.cloud import aiplatform import PyPDF2 import re import os import random import json import uuid
project=”YOUR_GCP_PROJECT” location="us-central1" pdf_path="lakeside_handbook.pdf" bucket_name = "lakeside-content" embed_file_path = "lakeside_embeddings.json" sentence_file_path = "lakeside_sentences.json" index_name="lakeside_index"
Agora criaremos um conjunto de funções auxiliares que nos auxiliam no fluxo de trabalho.
A primeira função aceita um PDF e o divide em uma lista de frases. Isso será usado para gerar embeddings por frase.
def extract_sentences_from_pdf(pdf_path):
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page in reader.pages:
if page.extract_text() is not None:
text += page.extract_text() + " "
sentences = (sentence.strip() for sentence in text.split('. ') if sentence.strip())
return sentences
Em seguida, precisamos de uma função que aceite uma ou mais sentenças e as converta em embeddings, passando-as pelo incorporação de texto-gecko@001 modelo.
def generate_text_embeddings(sentences) -> list:
aiplatform.init(project=project,location=location)
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@001")
embeddings = model.get_embeddings(sentences)
vectors = (embedding.values for embedding in embeddings)
return vectors
Iremos agrupar as duas funções acima em outra função que nos ajuda a dividir o PDF em dois arquivos JSON – um que possui um ID exclusivo para a frase e outro que possui o mesmo ID exclusivo, mas os embeddings correspondentes para cada frase.
def generate_and_save_embeddings(pdf_path, sentence_file_path, embed_file_path):
def clean_text(text):
cleaned_text = re.sub(r'u2022', '', text) # Remove bullet points
cleaned_text = re.sub(r's+', ' ', cleaned_text).strip() # Remove extra whitespaces and strip
return cleaned_text
sentences = extract_sentences_from_pdf(pdf_path)
if sentences:
embeddings = generate_text_embeddings(sentences)
with open(embed_file_path, 'w') as embed_file, open(sentence_file_path, 'w') as sentence_file:
for sentence, embedding in zip(sentences, embeddings):
cleaned_sentence = clean_text(sentence)
id = str(uuid.uuid4())
embed_item = {"id": id, "embedding": embedding}
sentence_item = {"id": id, "sentence": cleaned_sentence}
json.dump(sentence_item, sentence_file)
sentence_file.write('n')
json.dump(embed_item, embed_file)
embed_file.write('n')
Para simplificar o upload dos embeddings para o Google Cloud Storage, criaremos outra função auxiliar chamada upload_file que aceita o nome do bucket e o nome do arquivo.
def upload_file(bucket_name,file_path):
storage_client = storage.Client()
bucket = storage_client.create_bucket(bucket_name,location=location)
blob = bucket.blob(file_path)
blob.upload_from_filename(file_path)
Por fim, criaremos um índice de pesquisa vetorial apontado para o bucket GCS e implantaremos o endpoint.
def create_vector_index(bucket_name, index_name):
lakeside_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = index_name,
contents_delta_uri = "gs://"+bucket_name,
dimensions = 768,
approximate_neighbors_count = 10,
)
lakeside_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = index_name,
public_endpoint_enabled = True
)
lakeside_index_endpoint.deploy_index(
index = lakeside_index, deployed_index_id = index_name
)
Agora estamos prontos para invocar as funções para criar, configurar e implantar o Vector Search Index.
Passo 1: Gerar Embeddings para o PDF
generate_and_save_embeddings(pdf_path,sentence_file_path,embed_file_path)
Chamar o método acima gera dois arquivos semelhantes aos abaixo:
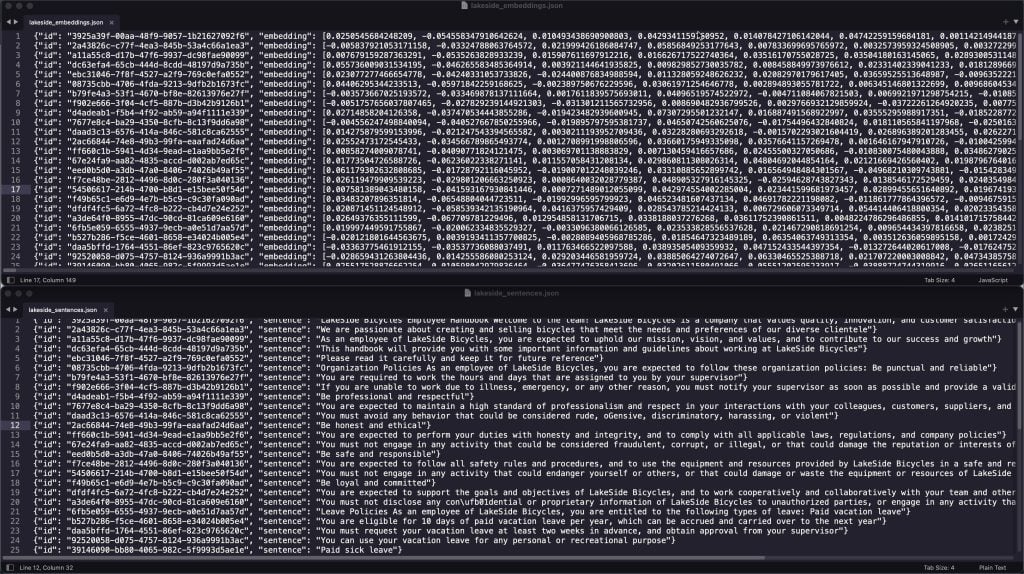
O UUID é comum entre os dois arquivos. Isso nos ajudará a identificar as sentenças correspondentes quando o Vector Search retornar os IDs correspondentes dos embeddings com base em uma pesquisa por similaridade.
Nosso objetivo é fazer upload do arquivo JSON com embeddings para um bucket do Cloud Storage e iniciar a criação do Vector Search Index Endpoint.
Chamaremos os métodos abaixo para completar o fluxo de trabalho:
Etapa 2: fazer upload do arquivo Embeddings para o Cloud Storage
upload_file(bucket_name,file_path)
Isso resulta na criação de um bucket e no upload do arquivo JSON para ele. Você pode verificar isso no Console do Cloud.
Etapa 3: Criação e implantação de endpoint de índice de pesquisa vetorial
create_vector_index(bucket_name, index_name)
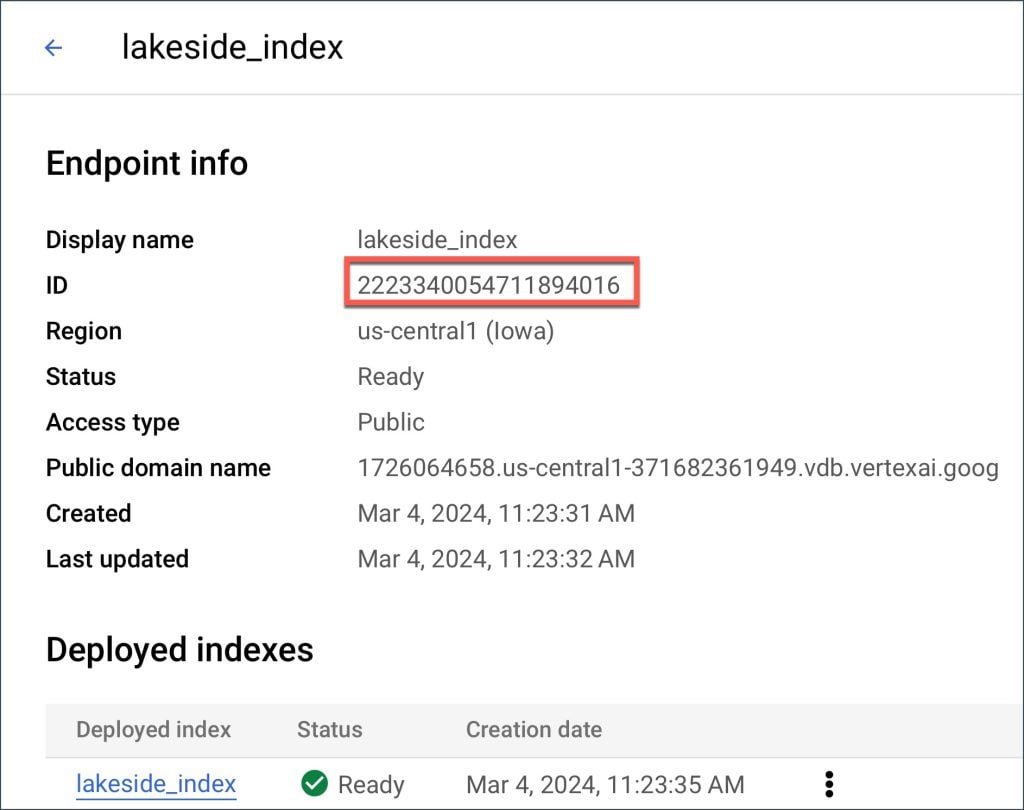
A última etapa leva pelo menos 20 minutos para ser concluída. Por favor, seja paciente. Quando terminar, você poderá verificar o Cloud Console.
Você pode acessar o código completo abaixo:
Veja o código no Gist.
Com o índice implementado, estamos prontos para implementar o RAG com Gemini Pro, o LLM mais capaz do Google disponível na Vertex AI.
Parte 2: Implementando RAG com Gemini e Vector Search no Google Cloud Vertex AI
Agora estamos prontos para importar os módulos. Inicie um novo Jupyter Notebook e adicione os trechos de código abaixo:
from vertexai.language_models import TextEmbeddingModel from google.cloud import aiplatform import vertexai from vertexai.preview.generative_models import GenerativeModel, Part import json import os
project=”YOUR_GCP_PROJECT” location="us-central1" location="us-central1" sentence_file_path = "lakeside_sentences.json" index_ep="2223340054711894016"
Você pode obter o ponto final do índice de pesquisa vetorial no console.
Vá em frente e inicialize o modelo e o índice vetorial
aiplatform.init(project=project,location=location)
vertexai.init()
model = GenerativeModel("gemini-pro")
lakeside_index_ep = aiplatform.MatchingEngineIndexEndpoint(index_endpoint_name=index_name)
Agora criaremos funções auxiliares para gerar embeddings para a consulta, carregar o arquivo local com ids e frases e mapear os ids correspondentes retornados pelo Vector Search com as frases.
def generate_text_embeddings(sentences) -> list:
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@001")
embeddings = model.get_embeddings(sentences)
vectors = (embedding.values for embedding in embeddings)
return vectors
Carregue o arquivo e preencha cada linha em uma lista Python.
def load_file(sentence_file_path):
data = ()
with open(sentence_file_path, 'r') as file:
for line in file:
entry = json.loads(line)
data.append(entry)
return data
Quando a Pesquisa vetorial retornar ids correspondentes dos embeddings com base na pesquisa por similaridade, mapearemos aqueles com o arquivo de frase local e, em seguida, concatenaremos todas as frases correspondentes em uma frase grande. Isso atua como contexto para o modelo.
def generate_context(ids,data):
concatenated_names=""
for id in ids:
for entry in data:
if entry('id') == id:
concatenated_names += entry('sentence') + "n"
return concatenated_names.strip()
Agora estamos prontos para implementar o RAG. O primeiro passo é aceitar a consulta e então gerar os embeddings para isso. Antes disso, vamos ter certeza de que o arquivo JSON das frases está carregado em uma lista que poderemos acessar posteriormente.
data=load_file(sentence_file_path)
#query=("How many days of unpaid leave in an year")
#query=("Allowed cost of online course")
#query=("process for applying sick leave")
query=("process for applying personal leave")
qry_emb=generate_text_embeddings(query)
Agora realizaremos a pesquisa semântica com base nos embeddings gerados e nos embeddings armazenados no Vector Search.
response = lakeside_index_ep.find_neighbors(
deployed_index_id = index_name,
queries = (qry_emb(0)),
num_neighbors = 10
)
Vector Search agora retorna um conjunto de UUIDs que correspondem aos embeddings.

A próxima etapa é recuperar os ids e transformá-los em uma lista.
matching_ids = (neighbor.id for sublist in response for neighbor in sublist)
Chamaremos agora o generate_context método auxiliar para gerar o contexto que pode ser injetado no prompt. Esta é a etapa mais crucial no pipeline do RAG.
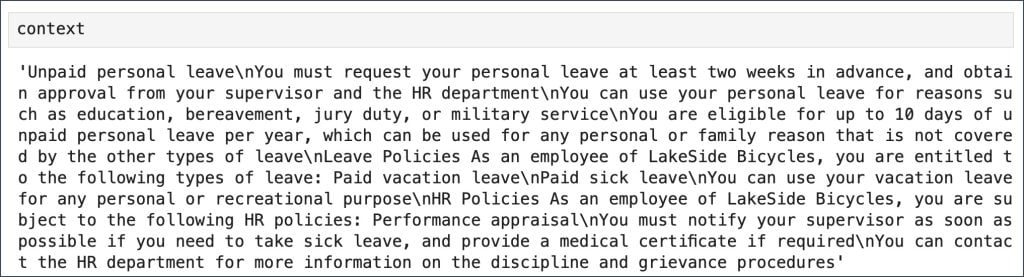
context = generate_context(matching_ids,data)
Para a consulta, “processo para solicitar licença pessoal”, obtivemos o contexto abaixo concatenando as frases do arquivo local.
Agora é hora de gerar o prompt aumentado com o contexto e a consulta original.
prompt=f"Based on the context delimited in backticks, answer the query. ```{context}``` {query}"
Quando finalmente invocamos o modelo, ele retorna com a resposta esperada derivada do contexto, que é factualmente correta.
chat = model.start_chat(history=()) response = chat.send_message(prompt) print(response.text)
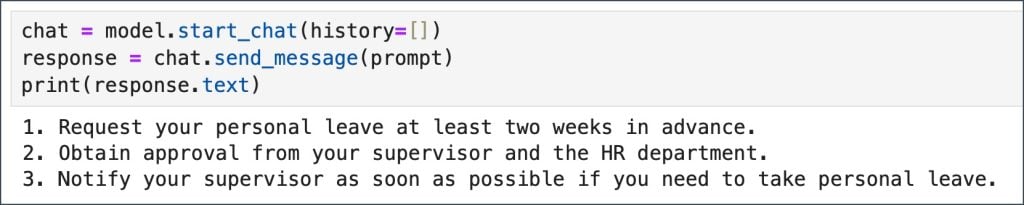
Abaixo está o código completo para esta parte do tutorial.
Veja o código no Gist.
A postagem Como armazenar embeddings na pesquisa vetorial e implementar RAG apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}
{kind=link}