
Gateway de saída: atribua IPs estáveis ao tráfego que sai dos clusters K8s
30 de abril de 2024
A versão 22 do Node.js melhora a experiência do desenvolvedor
30 de abril de 2024
Se você criar um modelo de linguagem grande (LLM) para usar especificamente com os dados da sua empresa, como filtrar os resultados para que a pessoa que consulta os dados receba apenas os resultados que está autorizada a ver?
A filtragem para proteger dados confidenciais é uma das muitas questões emergentes em torno da autorização e uso de LLMs.
Mas com uma arquitetura baseada em geração aumentada de recuperação (RAG) que pode extrair de um banco de dados vetorial, você pode escrever regras semelhantes a outras políticas de autorização para limitar quem pode ver o quê, de acordo com Graham Neray, CEO e cofundador da startup de autorização. Oso.
Em um artigo anterior do TNS, Badrul Sarwar, cofundador e CTO do serviço AIOps CloudAEye, explicou que, embora geralmente usado para adicionar dados de treinamento de um LLM, o RAG pode aproveitar os dados internos de um aplicativo e aumentar o conhecimento de um LLM para encontrar a resposta específica para uma pergunta.
Neray explicou: “O mesmo mecanismo que Oso usa para filtrar dados, digamos que quiséssemos mostrar as 10 principais páginas das quais você é proprietário… com esse mesmo mecanismo, você pode integrar bancos de dados vetoriais e fazer o exatamente o mesmo tipo de filtragem.”
Por exemplo, com um aplicativo baseado em LLM operando sobre Salesforce e outros dados de clientes, como parte de uma arquitetura baseada em RAG, os desenvolvedores podem escrever regras que retornem informações específicas apenas para as contas às quais um vendedor tem permissão de acesso.
Isso está gerando muito interesse no mundo das autorizações, disse Neray.
Em uma postagem no blog, Oso explica como isso funciona, supondo que alguém tenha usado um chatbot para perguntar: “Diga-me o que diz a isenção médica do colega de trabalho X” ou alguma outra consulta para dados confidenciais. Isso exige que o chatbot tenha os mesmos controles de acesso que o restante do seu aplicativo. A pesquisa envolve uma pesquisa de similaridade vetorial, mas o mesmo LLM deve ser usado para avaliar os prompts usados nessa pesquisa vetorial. Isso se refere à autorização.
O sistema RAG não sabe quais dados são considerados confidenciais.
Em vez de criar um banco de dados personalizado para cada usuário, você pode restringir os resultados apenas aos dados aos quais o usuário tem acesso. Por exemplo, essa consulta SQL pode incluir WHERE folder IN <folders_user_is_allowed_to_access> para encontrar as partes relevantes do conteúdo que o usuário pode ver.
“Parte do desafio neste mercado é que ninguém realmente entende o que está fazendo. Não é como o mercado de banco de dados, que existe desde sempre”, disse Neray.
“Bem, se você acha que ninguém sabe fazer autorização no mundo real, deixe-me falar sobre o nível de conhecimento no mundo do LLM. Todo mundo ainda está tentando descobrir. … Todo mundo está tentando descobrir como fazer isso de uma forma que não lhes cause problemas. … E não é uma solução exótica. Basicamente, estamos dizendo: ‘Ei, o mesmo mecanismo que você usa para filtrar coisas de bancos de dados pode ser usado para um banco de dados vetorial.’”
Em um artigo anterior, Liam Crilly da NGINX descreveu esse tipo de restrição aos LLMs como algo que os gateways de IA cuidarão, e muito mais.
“O gateway lida com autenticação e confiança zero, servindo como guardião dos serviços de IA e acesso à API. Ele também fornece uma camada de autorização para garantir que apenas usuários aprovados possam acessar serviços específicos ou que os serviços sejam aprovados para serem consumidos de acordo com políticas definidas. As políticas podem restringir o uso com base na geografia, unidade de negócios, função, fornecedor de infraestrutura ou tipo de infraestrutura”, explicou.
Um gateway de IA terá implicações para RAG e bancos de dados vetoriais, de acordo com Alex Salkever, autor e consultor do NGINX.
“Parte disso também pode ser governar ou proteger contra IA, questões de segurança e instruções de policiamento externas. Alguns estão centralizando a governança da API e simplificando para os desenvolvedores”, disse ele por e-mail.
Esses são tópicos sobre os quais se espera que o NGINX contribua com mais artigos.
Desacoplando dados e lógica de autorização
Oso originalmente pretendia separar autenticação e autorização e fornecer aos desenvolvedores um serviço de autorização fácil de usar no estilo Stripe para pagamentos ou Twilio para comunicações.
A autorização continua a ser um problema difícil, especialmente num mundo de microsserviços onde existem tantas peças móveis. Embora a abordagem de Zanzibar do Google, que exige que as empresas centralizem e copiem antecipadamente todos os dados de autorização relevantes em um único serviço de autorização, tenha sido obrigatória para autorização, Oso considerou-a muito trabalhosa e muito propensa a erros.
Oso lançou recentemente o que chama de Autorização Distribuída. Em vez de sincronizar e centralizar todos os seus dados, com a Autorização Distribuída você pode centralizar apenas os dados de autorização comuns e deixar o restante nos bancos de dados onde residem atualmente. Oso então se integra a esses bancos de dados e reúne todos os dados no backend.
Neray gostou dessa abordagem centralizada para montar um quebra-cabeça.
“Em um mundo monolítico, todas as peças do quebra-cabeça estão em um banco de dados. Em um mundo de microsserviços ou onde usamos LLMs, eles tendem a estar em vários serviços diferentes e em vários bancos de dados diferentes”, explicou ele. E a maioria das empresas não possui os recursos do Google.
“Portanto, empresas fora do Google que desejam implementar esse modelo em que centralizam todos esses dados, configuram todos esses sistemas complicados para sincronizar, copiar, reconciliar, desduplicar e gerenciar o desvio entre seus serviços principais e os sistemas centrais de autorização”, ele disse.
“O engenheiro médio que trabalha neste problema quer configurar essa infraestrutura como se quisesse cavar na cabeça. Então, o que construímos é um sistema que permite que esses engenheiros centralizem apenas os dados que são compartilhados por todos esses serviços… depois deixem o restante dos dados em todos esses microsserviços, e nós juntaremos tudo para eles no fundo. “
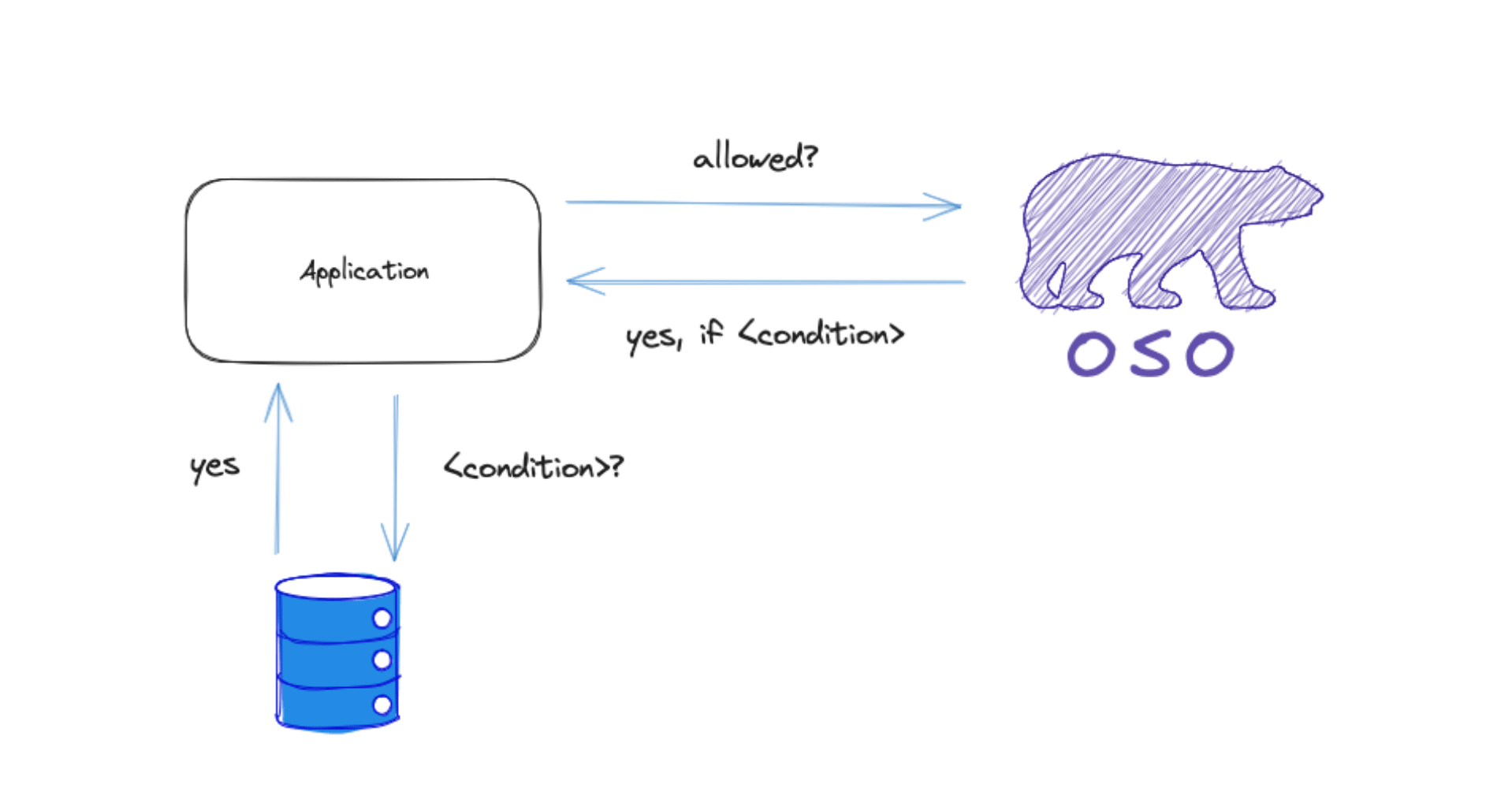
O defensor do desenvolvedor Oso, Greg Sarjeant, explicou em uma postagem no blog:
“Nosso aplicativo ficou frágil porque a lógica do aplicativo e a lógica de autorização estavam interligadas.”
“… E se, em vez disso, você pudesse centralizar sua lógica e seus dados de autorização comuns (coisas como funções) no serviço de autorização e, em seguida, distribuir a avaliação das questões de autorização entre o servidor e o cliente? Isso é autorização distribuída. Em vez de apenas responderyesounoOso Cloud agora pode responder a uma pergunta de autorização comyes, if.”
Segue uma lista de condições que yes, if. Essas condições são avaliadas pelo cliente usando seus dados locais. Basicamente, o serviço Oso Cloud avalia o máximo que sabe da solicitação e, em seguida, entrega a solicitação ao cliente em seu aplicativo para tomar uma decisão final.
‘(Obter) a capacidade de fornecer esta autorização de nível empresarial sem ter que configurar toda essa infraestrutura de sincronização é uma grande vitória para (as equipes da plataforma).’
– Graham Neray, CEO e cofundador da Oso
Neray afirma que a integração com dados mais próximos de sua fonte é mais segura do que movê-los e tentar sincronizá-los.
“Ao mudar para um modelo como este, você obtém o que é efetivamente uma abordagem determinística. Então agora as pessoas podem realmente testar sua lógica de autorização, podem registrá-la, auditá-la e ver se está funcionando. E isso se torna uma parte discreta de sua pilha, da mesma forma que um banco de dados seria, em vez de ser uma espécie de 30 instruções de código IF aninhadas”, disse ele, acrescentando que é uma bênção para as equipes de engenharia de plataforma.
“Essas equipes estão sob uma pressão imensa; eles estão sendo solicitados a fazer mais pelo negócio. Eles definitivamente não estão conseguindo um quadro de funcionários adicional. Eles precisam reduzir a conta do Datadog de dados. Eles estão de plantão e estão fazendo todas essas coisas. E a última coisa que eles querem fazer é configurar uma infraestrutura de sincronização de dados sob medida, que é notoriamente desafiadora e propensa a erros. … (Obter) a capacidade de fornecer esta autorização de nível empresarial sem ter que configurar toda essa infraestrutura de sincronização é uma grande vitória para eles. É uma grande vitória em termos de tempo, é uma grande vitória em termos de risco. E é uma grande vitória em termos do que eles podem oferecer aos seus clientes internos.”
O fornecedor de tecnologia de atendimento ao cliente Intercom usa o Oso desde antes de ter um produto comercial. O engenheiro principal sênior Brian Scanlan elogiou Oso como “construindo para construtores e buscando um problema específico”.
“A maioria das pilhas de tecnologia adjacentes estavam tentando fazer muito (toda a autorização e autenticação para seu aplicativo – não queríamos ter que fazer uma grande revisão de todo o nosso gerenciamento de usuários), não tinham desenvolvedores atraentes documentação ou não tinham maneiras fáceis de começar a usar sua biblioteca/ferramenta”, disse ele por e-mail.
“A promessa da abordagem de Oso à autorização foi cumprida (para nós). Removemos praticamente todas as fontes de bugs de autorização em nosso aplicativo, eliminando muito trabalho de alta pressão de nossas equipes e nos dando mais confiança para construir mais recursos com base em controles de autorização rígidos. Faz alguns anos que não tocamos em Oso. É um problema amplamente resolvido para nós, que é exatamente o que você deseja de um bloco de construção fundamental de aplicativos SaaS multilocatários modernos com necessidades de autorização sofisticadas.”
A postagem Como controlar o acesso na autorização distribuída LLM Data Plus apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}
{kind=link}