No mundo do aprendizado de máquina, a mudança é a única constante. A dependência tradicional de grandes conjuntos de dados processados em lote está dando lugar a uma abordagem mais dinâmica e em tempo real dos dados. Esta evolução está sendo impulsionada pela compreensão de que ser capaz de processar e analisar dados em tempo real não é apenas uma vantagem – é uma necessidade.
Isto é particularmente verdadeiro em setores como o ecossistema de entrega de alimentos, onde as expectativas dos clientes e as necessidades empresariais podem mudar num piscar de olhos. Aqui, os mecanismos de streaming de dados surgem como atores-chave que transformam o cenário do processamento de dados e do aprendizado de máquina.
A situação com dados processados em lote
A previsão do tempo de entrega de alimentos tradicionalmente se baseia em dados processados em lote. Este método, embora um tanto eficaz, muitas vezes leva a insights obsoletos devido à latência entre a coleta e o processamento de dados. As variáveis de dados normalmente incluem o meio de transporte do parceiro de entrega, idade, classificações e a métrica crucial de distância entre o restaurante e o local de entrega.
Entre em streaming de dados: a revolução em tempo real
Nos últimos anos, a indústria de entrega de alimentos experimentou um tremendo aumento na demanda. Este aumento, parcialmente impulsionado pela pandemia, destacou as dolorosas limitações dos modelos de dados processados em lote e sublinhou a necessidade de processamento de dados em tempo real. O processamento de dados em tempo real permite insights imediatos e adaptabilidade – componentes essenciais em um setor impulsionado pelas expectativas dos clientes urgentes.
Tecnologias de streaming como o Apache Kafka surgiram para resolver os desafios criados pelo fluxo de dados em tempo real. Kafka, conhecido por sua capacidade de lidar com fluxos de dados de alto rendimento, fornece a base para ingestão e processamento de dados em tempo real. No entanto, a arquitetura do Kafka, embora robusta, muitas vezes requer componentes adicionais para transformação e processamento de dados.
Redpanda é uma implementação moderna da API Kafka posicionada como uma alternativa mais simplificada ao Kafka. Ele aborda algumas das complexidades do Kafka, fornecendo uma configuração e experiência operacional mais simples para os desenvolvedores.
Por exemplo, Redpanda Data Transforms é desenvolvido com WebAssembly (Wasm) e permite o processamento de dados no local. Isso significa que os dados podem ser limpos, transformados e preparados para modelos de aprendizado de máquina diretamente no corretor Redpanda, eliminando a necessidade de camadas adicionais de processamento de dados.
Implementando Redpanda em modelos preditivos em tempo real
Para ilustrar o papel do Redpanda em aplicativos de aprendizado de máquina (ML) que lidam com grandes volumes de dados em tempo real, continuarei com o exemplo de um serviço de entrega de comida.
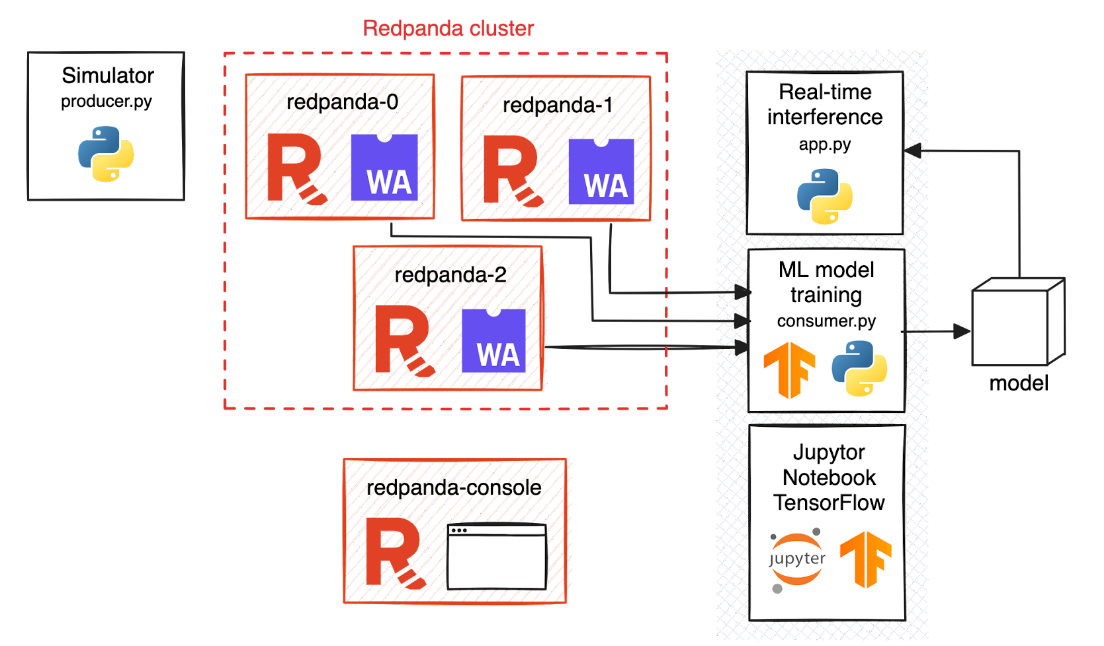
Arquitetura de como o Redpanda se encaixa em um serviço de entrega em tempo real alimentado por aprendizado de máquina (Fonte: Redpanda)
No modelo de previsão do “tempo de entrega de comida”, a arquitetura do Redpanda envolve estes componentes principais:
Ingestão de dados: Estes dados provêm de diversas fontes e são muitas vezes brutos e não estruturados, o que representa o primeiro desafio.
Transformação instantânea de dados: Uma vez ingerido, um script Golang personalizado usa o recurso Wasm do Redpanda para processar os dados dinamicamente. Isso inclui o cálculo da métrica de “distância” ausente – um recurso crítico para este modelo preditivo. Este processo exemplifica a engenharia de recursos em ML, onde os principais recursos de dados são desenvolvidos ou transformados para aumentar a precisão do modelo. A eficiência de transformação de dados em tempo real do Redpanda permite a criação e modificação imediata e dinâmica de recursos.
Treinamento de modelo de ML com TensorFlow: Os dados transformados são então alimentados em um modelo de ML criado usando TensorFlow I/O. O TensorFlow I/O facilita o consumo de fluxos de dados em tempo real, permitindo que o modelo seja continuamente atualizado com dados novos. No entanto, é importante observar que o treinamento inicial ainda requer um lote de dados históricos para estabelecer uma linha de base.
Implantação e inferência do modelo: Depois de treinado, o modelo é implantado para inferência em tempo real. À medida que novos dados chegam, o modelo ajusta dinamicamente suas previsões, fornecendo estimativas atualizadas do tempo de entrega.
Aplicativo voltado para o usuário: O componente final é um aplicativo voltado para o usuário que usa as previsões do modelo para fornecer aos clientes e parceiros de entrega estimativas de entrega precisas e em tempo real.
Configure a infraestrutura
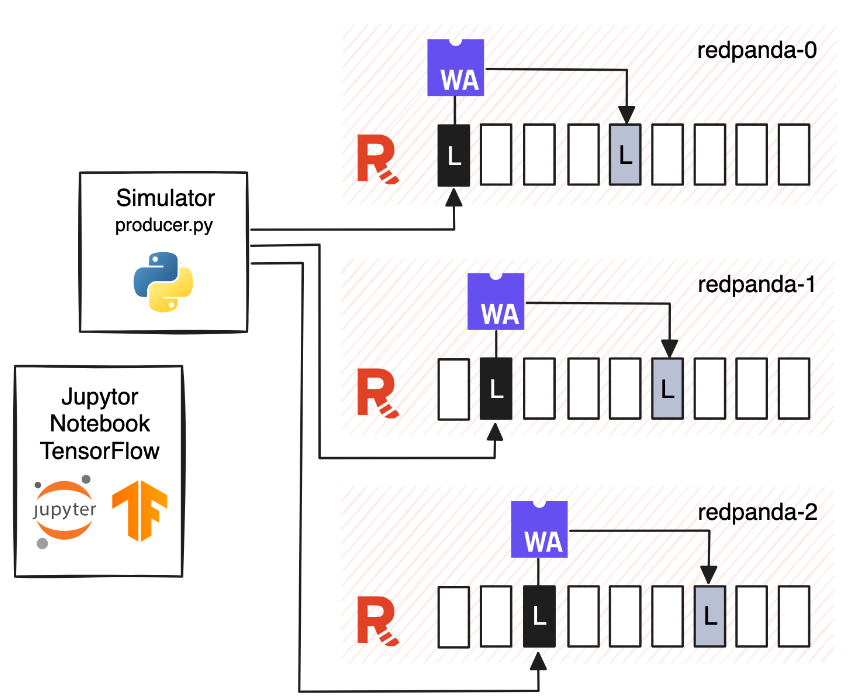
O diagrama a seguir ilustra o processo de configuração, que envolve várias etapas importantes.
Componentes da infra-estrutura proposta do serviço de entrega de alimentos. (Fonte: Redpanda)
1. Simule fluxos de dados
Um script Python simula o fluxo contínuo de dados, imitando cenários do mundo real de atualizações frequentes de pedidos.
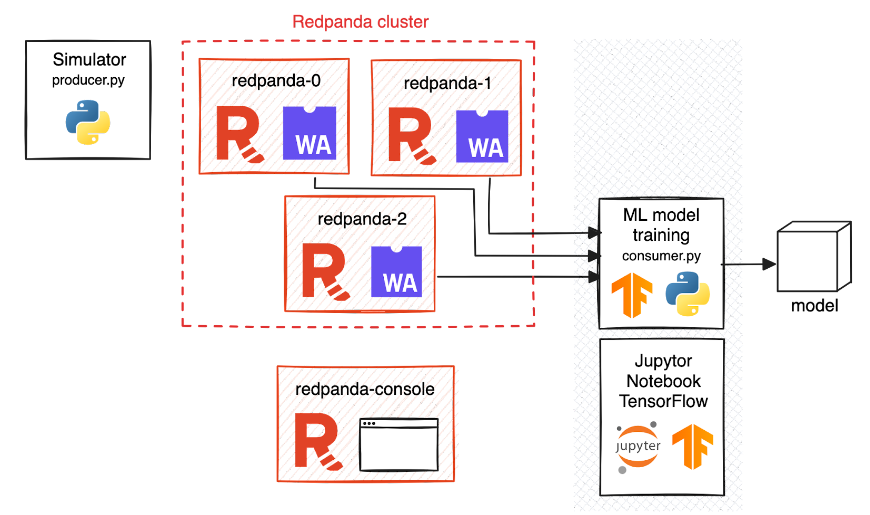
2. Configure o cluster
Um cluster Redpanda é configurado para lidar com os fluxos de dados. Isso envolve configurar o número de corretores e configurar o Console Redpanda para monitoramento.
3. Implante transformações de dados
O script Golang para transformação de dados é implantado usando o Redpanda rpk transform deploy comando. Isso garante que a lógica de transformação de dados seja aplicada uniformemente em todos os nós do intermediário.
Os dados são processados no broker da partição para a qual são enviados e o resultado é gravado diretamente na memória. (Fonte: Redpanda)
Inicie o projeto Redpanda Transforms:
Construa a transformação em um módulo WebAssembly (Wasm) e implante-a no cluster Redpanda para execução:
Implante o módulo no cluster Redpanda. Redpanda distribui o módulo implantado por todos os corretores do cluster. Essa distribuição é vital para balanceamento de carga e tolerância a falhas. Independentemente de qual corretor esteja gerenciando uma partição ou tópico específico, a lógica de transformação estará disponível para processar os dados para reduzir a latência e aumentar a eficiência, já que não há necessidade de mover dados pela rede para processamento.
4. Treine o modelo TensorFlow
O modelo de E/S do TensorFlow é treinado usando dados históricos em lote e fluxos de dados em tempo real. Essa abordagem híbrida ajuda a garantir que o modelo se beneficie da profundidade dos dados históricos e, ao mesmo tempo, permaneça ágil com atualizações em tempo real.
Wasm auxilia no pré-processamento de dados no formato desejado e os prepara para o treinamento do modelo de ML. (Fonte: Redpanda)
Para transmitir dados diretamente de tópicos Redpanda para um conjunto de dados do TensorFlow, configure o conjunto de dados para ingerir dados do tópico “dados de modelo” em um cluster Redpanda. O loop de processamento principal lida com dados em lotes: ele acumula mensagens e depois as embaralha e decodifica antes de usá-las para treinamento. Posteriormente, o modelo é treinado para uma época com cada lote e depois salvo e exportado.
Vantagens e aplicações futuras
A integração do Redpanda na modelagem preditiva oferece várias vantagens:
Latência reduzida: Ao processar dados em tempo real, a latência entre a coleta de dados e a geração de insights é significativamente reduzida.
Atualizações dinâmicas do modelo: O fluxo contínuo de dados permite que o modelo se adapte e melhore ao longo do tempo, levando a previsões mais precisas.
Arquitetura simplificada: A realização de transformações de dados dentro do corretor reduz a necessidade de camadas adicionais de processamento de dados, simplificando a arquitetura geral.
Esta abordagem, embora demonstrada através do exemplo da previsão do tempo de entrega de alimentos, tem implicações de longo alcance. Pode ser aplicado a muitos setores onde a análise de dados em tempo real é crucial, tais como mercados financeiros, monitorização de cuidados de saúde e gestão de cidades inteligentes.
Mecanismos modernos de streaming de dados, como o Redpanda, não estão apenas transformando a maneira como lidamos com os dados – eles estão remodelando o futuro dos aplicativos de ML em tempo real. À medida que continuamos a explorar e a inovar, as possibilidades são tão vastas e excitantes quanto os fluxos de dados que procuramos aproveitar.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Christina Lin é Diretora de Defesa do Desenvolvedor da Redpanda Data, onde transforma soluções inovadoras de streaming de dados em conteúdo facilmente acessível para todos aprenderem. Ela tem mais de 20 anos de experiência em desenvolvimento de software e trabalhou como…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.







{kind=link}
{kind=link}
{kind=link}