O ganhador do Prêmio Turing, Dr. Mike Quebra-pedras continua inventando bancos de dados. Quarenta anos atrás, foi o primeiro sistema relacional, Ingress, e trinta anos atrás, foi PostgreSQL. Mais recentemente, ele co-criou um sistema de banco de dados transacional em memória, VoltDB.
Agora, ele está de volta com um sistema de banco de dados projetado para substituir toda a pilha de computação nativa da nuvem, DBOS (Database Operating System).
O Linux é muito antigo e o Kubernetes é muito complicado, proclamou a start-up por trás deste trabalho. Agora, um banco de dados foi projetado para substituir todos eles.
Para tornar essa visão realidade, a DBOS, Inc. levantou US$ 8,5 milhões em financiamento inicial liderado pela Engine Ventures, juntamente com Construct Capital, Sinewave e GutBrain Ventures.
O projeto foi fundado pelo Dr. Quebra-pedrasjunto com o criador do Apache Spark (e cofundador e CTO da Databricks, Matei Zaharia) e uma equipe conjunta de cientistas da computação do MIT e de Stanford.
O DBOS executa serviços do sistema operacional em um banco de dados distribuído de alto desempenho. Todos os estados, logs e outros dados do sistema são armazenados em tabelas acessíveis por SQL.
O resultado é uma nuvem de computação sem servidor escalonável, tolerante a falhas e ciber-resiliente para aplicativos nativos da nuvem, afirmam os criadores.
Com um sistema operacional executado em um banco de dados distribuído, você obtém tolerância a falhas, escalabilidade de vários nós e gerenciamento de estado. A observabilidade e a segurança ficam mais fáceis. Já se foram os contêineres e as camadas de orquestração.
“Você escreve menos código porque o sistema operacional está fazendo mais por você”, disse Stonebraker.
Hoje, os sistemas distribuídos são em grande parte construídos em um sistema operacional (Linux) projetado para rodar em um único servidor. Isso resulta em um número incrível de estados variáveis diferentes para gerenciar, em toda a pilha de infraestrutura (dados de aplicativos, sistemas de autenticação, mensagens, gerenciamento de cluster).
É claro que esta natureza fragmentada necessita de uma quantidade incalculável de ferramentas de observação e de segurança, uma vez que todos os estados proporcionam aos hackers mal-intencionados um terreno fértil para trabalhar.
O que poderia lidar com um milhão de estados com facilidade? Um banco de dados, é claro.
No projeto do DBOS, um OLTP distribuído de alto desempenho implementaria um conjunto de serviços de sistema operacional. Ele seria executado em um kernel mínimo do sistema operacional, com suporte para gerenciamento de memória, drivers de dispositivos, manipuladores de interrupções e tarefas básicas de gerenciamento de bytes.
Um banco de dados para governar todos eles
Esta não é a primeira vez que esta ideia é levantada: já em 2001, lembramo-nos de Larry Ellison argumentando que o middleware era uma “ideia estúpida”, que tudo deveria ser gerido por uma base de dados em si.
A ideia central por trás deste projeto DBOS vem de uma ideia simples: manter o controle do estado do sistema operacional deveria ser um problema de banco de dados, disse o Dr. Stonebraker disse.
A ideia surgiu de uma palestra da Zaharia. Ele observou que o serviço de nuvem Databricks para Apache Spark gerenciava rotineiramente um milhão de subtarefas de uma só vez. Todas as informações de estado e agendamento estavam sendo rastreadas em um banco de dados PostgreSQL, cujo desempenho lento frustrou a equipe administrativa do Databricks.
O gargalo do banco de dados poderia ser resolvido com bastante facilidade. Na verdade, era disso que se tratava o VoltDB, processamento transacional simultâneo compatível com ACID que poderia ser espalhado por vários servidores.
Antigamente, o Dr. Stonebraker foi um dos primeiros usuários do Unix em um PDP 11/40 com 48k de memória principal e 25MB de memória em disco. Então, todos os estados foram mantidos pelo próprio Unix. É claro que um milhão de estados representa um salto de seis ordens de grandeza em comparação com o PDP. Mas “a quantidade de estado que o sistema operacional precisa acompanhar é basicamente proporcional aos recursos”, disse o Dr. Stonebraker disse.
O próprio DBOS foi testado no SuperCloud do Massachusetts Institute of Technology, com mais de 32.000 processadores, terabytes de memória principal e muito mais terabytes de armazenamento secundário.
Na parte inferior da pilha está um sistema de banco de dados transacional distribuído, com um sistema de arquivos, mecanismo de agendamento e sistema de mensagens, todos construídos na parte superior.
Esses pesquisadores discutiram a pilha na Very Large Databases Conference 2023, detalhando o trabalho em um conjunto de artigos, cobrindo transações ACID e reprodução do sistema.
Dr. Stonebraker rotulou o Linux como “vazado”, o que significa que há muitas maneiras pelas quais vulnerabilidades de segurança podem ser introduzidas. Além disso, construir um sistema operacional sobre um banco de dados ofereceria a capacidade de reverter para um estado anterior à exploração de uma vulnerabilidade (pense nisso como um Apple Time Machine, mas para servidores).
O banco de dados centralizado também ajudará na depuração, disse o Dr. Stonebraker disse. Dividir aplicativos em microsserviços torna muito difícil depurá-los ou até mesmo fazer com que o comportamento injustificado apareça em cada teste (estes são conhecidos como “Heisenbugs”)
“Executamos todos os seus microsserviços de forma transacional. Portanto, os microsserviços paralelos são classificados pelo nosso sistema de controle de simultaneidade e, basicamente, ou não há Heisenbugs ou eles são muito, muito mais difíceis de encontrar”, disse o Dr. Stonebraker disse.
Originalmente, o sistema foi simulado no VoltDB, mas os patrocinadores queriam optar por um sistema de valor-chave de código aberto, então escolheram o FoundationDB como base. (Dr. Stonebraker admitiu que qualquer sistema OLTP distribuído compatível com PostgreSQL funcionaria, como, digamos, CockroachDB).
DBOS Cloud: um banco de dados distribuído para suporte transacional
O primeiro serviço comercial desenvolvido é o DBOS Cloud, uma plataforma transacional de Funções como Serviço (FaaS), disponível para desenvolvedores neste lançamento inicial.
O DBOS, que roda no Firecracker da Amazon Web Services, está inicialmente disponível para os desenvolvedores experimentarem por meio do DBOS Cloud, lançado hoje.
DBOS Cloud é uma plataforma de aplicativos transacionais sem servidor alimentada pelo sistema operacional DBOS e pode ser usada para construir e executar funções, fluxos de trabalho e aplicativos sem servidor. Pense nisso como AWS Lambda, mas com suporte transacional.
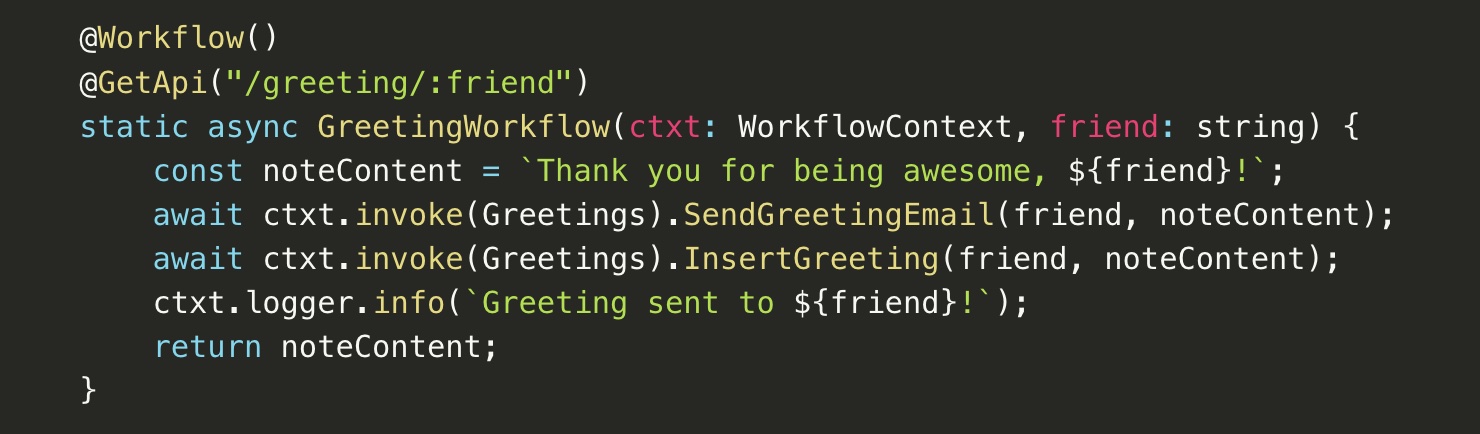
O DBOS torna o código TypeScript tolerante a falhas muito mais fácil de criar e mais barato de executar (DBOS).
O serviço oferece os seguintes benefícios:
Suporte para funções e fluxos de trabalho com estado
Tolerância a falhas integrada com execução única garantida
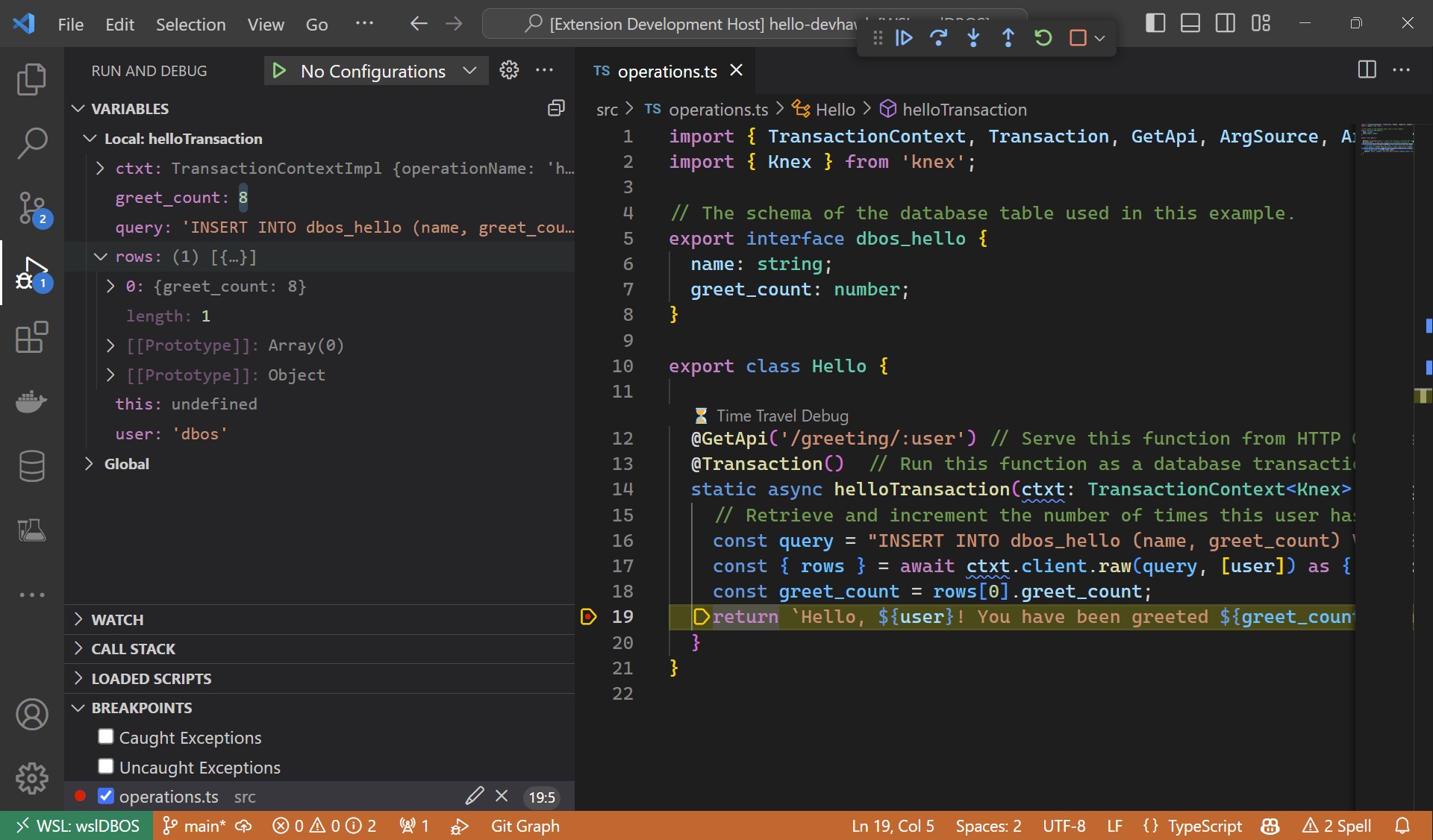
Depuração de viagem no tempo
Dados de observabilidade acessíveis por SQL
Ativação da autodetecção e autorrecuperação de ataques cibernéticos
Um repositório GitHub inclui algumas das ferramentas que a empresa desenvolveu, incluindo uma estrutura TypeScript para interagir com DBOS e o “depurador viajante do tempo” para VSCode.
DBOS Cloud mantém uma trilha de auditoria completa de código e processamento de dados e os armazena em tabelas SQL criptografadas. O DBOS Cloud Time Travel Debugger permite que os dados sejam reproduzidos e examinados para solucionar problemas, garantir a conformidade regulatória ou procurar fraudes, etc. (DB Chefe)
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Joab Jackson é editor sênior do The New Stack, cobrindo computação nativa em nuvem e operações de sistema. Ele faz reportagens sobre infraestrutura e desenvolvimento de TI há mais de 25 anos, incluindo passagens pela IDG e pela Government Computer News. Antes disso, ele…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.







{kind=link}
{kind=link}
{kind=link}