GenAI cria experiências web personalizadas combinando dados proprietários com o conhecimento de usuários individuais. Como podemos garantir que esse conhecimento seja tratado com segurança de acordo com os padrões de conformidade de segurança?
Como podemos fornecer aos nossos usuários garantias em relação à exclusão de suas informações de identificação pessoal (PII)?
Vamos examinar as ferramentas e os padrões que você pode usar para garantir que seus aplicativos estejam em conformidade com os padrões de segurança e privacidade.
Por que RAG é a melhor arquitetura para garantir a privacidade de dados
A geração aumentada de recuperação, a arquitetura que enriquece as respostas da GenAI com dados privados, é comumente implantada para resolver grandes deficiências do modelo de linguagem, incluindo alucinações e janelas de contexto curtas.
Mas o RAG também nos ajuda a construir sistemas de IA conscientes da privacidade que esquecem informações específicas sobre indivíduos sob demanda.
Para cumprir os padrões de segurança, precisamos garantir que os dados do usuário:
Separação
Os namespaces separam os dados dos seus usuários e são adequados como uma primitiva de segurança.
Privacidade
Ao usar o RAG, os dados são fornecidos como contexto para um LLM apenas no momento da geração, mas os dados não precisam ser usados para treinamento ou ajuste fino de modelos de IA.
Isso significa que seus dados de usuário não são armazenados nos próprios modelos como conhecimento — eles são apenas mostrados aos modelos GenAI quando solicitamos o conteúdo gerado.
O RAG permite a personalização enquanto mantém controle rigoroso sobre qualquer PII usada para gerar respostas específicas do usuário.
Dados proprietários ou PII são compartilhados com o LLM conforme solicitação e podem ser rapidamente removidos do sistema, tornando as informações indisponíveis para solicitações futuras.
Exclusão sob demanda
Quando um usuário deseja ser esquecido, a exclusão de seus dados do índice do banco de dados vetorial fará com que o sistema RAG não tenha mais conhecimento deles.
Os LLMs não poderão responder perguntas sobre um determinado usuário ou tópico após a exclusão dos dados. A fase de recuperação não fornecerá mais nenhuma dessas informações ao LLM no momento da geração.
O RAG oferece mais flexibilidade no gerenciamento de dados específicos do usuário do que treinamento ou ajuste fino, porque você pode remover rapidamente dados sobre uma ou mais entidades de um sistema de produção sem afetar o desempenho do sistema para outros usuários.
Tratamento seguro de dados de clientes
Compreendendo diferentes tipos de dados
Projetar seu software para ter consciência da privacidade requer a compreensão dos riscos associados a cada tipo de dados de clientes que você armazena.
Primeiro, classifique os tipos de dados que você precisará armazenar em seu banco de dados vetorial. Especificamente, identifique quais dados são públicos, privados e quais contêm PII.
Imagine que estamos construindo um aplicativo de comércio eletrônico que armazenará uma combinação de dados públicos, confidenciais e PII:
Público: Nome da empresa, foto do perfil e cargo.
Privado: chaves de API, IDs de organização, histórico de compras.
Informações de identificação pessoal: Nome completo, data de nascimento, ID da conta.
Em seguida, determine quais dados serão armazenados apenas como vetores e quais devem ser armazenados em metadados para suportar a filtragem.
Nosso objetivo é equilibrar o armazenamento do mínimo de PII possível e o fornecimento de uma rica experiência de aplicação.
A filtragem com metadados é poderosa, mas sua forma mais simples requer o armazenamento de dados privados ou PII em texto simples, por isso queremos estar atentos aos campos que expomos.
Com esse entendimento, podemos considerar cada tipo de dados e aplicar as técnicas a seguir para tratá-los com segurança.
Segregar dados de clientes em índices
Use índices separados para finalidades diferentes. Se seu aplicativo gerencia descrições em linguagem natural de localizações geográficas e alguns dados de usuário pessoalmente identificáveis, crie dois índices separados, como locais e usuários.
Nomeie seus índices com base no que eles contêm. Pense nos índices como depósitos de alto nível para os tipos de dados que você está armazenando.
Segregar dados de clientes em namespaces
Como escrevemos anteriormente sobre a construção de sistemas de multilocação, os namespaces são primitivos convenientes e seguros para separar organizações ou usuários em um único índice.
Pense nos namespaces como partições específicas da entidade dentro de um índice. Se o seu índice for de usuários, cada namespace poderá ser mapeado para o nome de cada usuário. Cada namespace armazenaria apenas dados relevantes para seu usuário.
O uso de namespaces também ajuda a melhorar o desempenho da consulta, reduzindo o espaço total que precisa ser pesquisado ao retornar resultados relevantes.
Use prefixo de ID para consultar segmentos de conteúdo
Pinecone suporta prefixo de ID, uma técnica que anexa dados extras aos campos de ID de seus vetores no upsert para que você possa referenciar posteriormente “segmentos” de conteúdo, como todos os documentos da página 1, pedaço 23 ou todos os vetores de usuário A do Departamento Z.
O prefixo de ID é ideal para associar um conjunto de vetores a um usuário específico, para que você possa excluir com eficiência os dados desse usuário sempre que ele solicitar.
Por exemplo, imagine um aplicativo que processa pedidos de restaurantes para que os usuários possam encontrar suas compras usando linguagem natural:
O campo ID pode fornecer tags hierárquicas de qualquer composição que faça sentido em seu aplicativo.
Dessa forma, você pode realizar exclusões e listas em massa com mais facilidade:
O uso de prefixos de ID requer algum planejamento inicial ao projetar seu aplicativo, mas fornece um meio conveniente de fazer referência a todos os vetores e metadados relacionados a uma entidade específica.
A geração aumentada de recuperação também é ótima para excluir conhecimento
A Retrieval Augmented Generation adiciona dados proprietários, privados ou de rápida mudança às respostas do LLM para fundamentá-las na verdade e em contextos específicos.
Mas também é uma forma ideal de fornecer aos usuários finais garantias sobre o direito de serem esquecidos. Vamos considerar um cenário de comércio eletrônico onde nossos usuários podem usar linguagem natural para interagir com uma loja, recuperar pedidos antigos, adquirir novos produtos, etc.
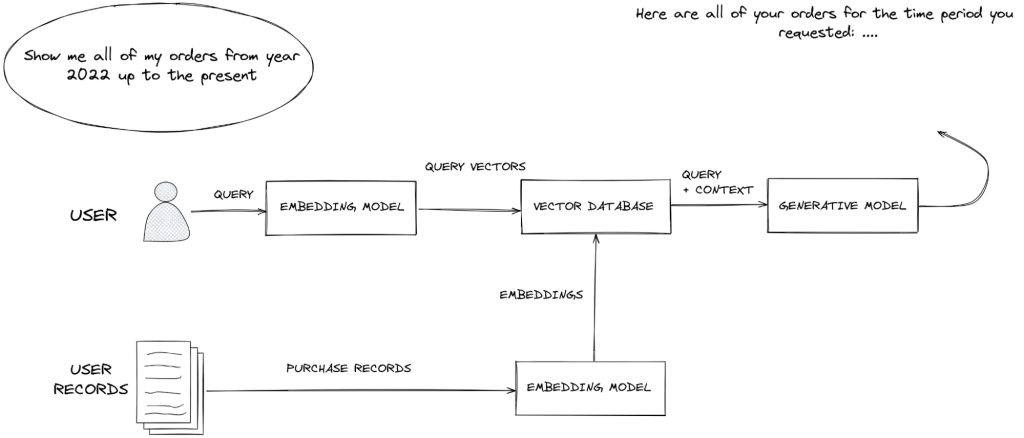
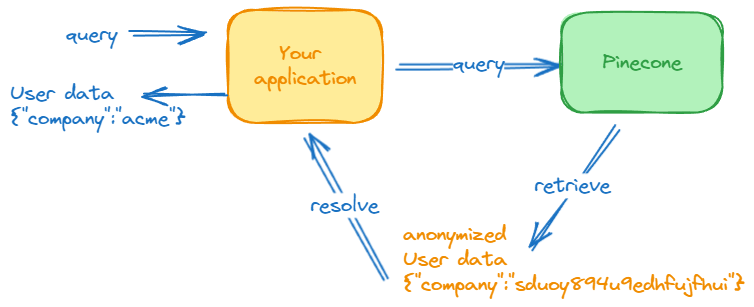
No fluxo de trabalho RAG a seguir, a consulta em linguagem natural do usuário é primeiro convertida em um vetor de consulta e depois enviada ao banco de dados vetorial para recuperar pedidos que correspondam aos parâmetros do usuário.
O contexto pessoal do usuário (seu histórico de pedidos) e algumas informações de identificação pessoal são buscados e fornecidos ao modelo generativo no momento da inferência para satisfazer sua solicitação.
RAG oferece controle sobre quais dados do usuário são apresentados aos LLMs
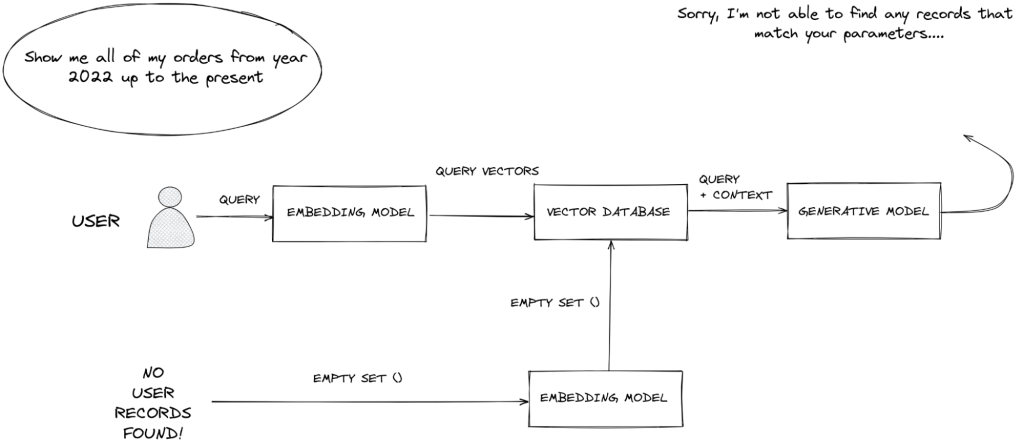
O que acontece quando você emite uma exclusão em lote usando o esquema de prefixo de ID?
Você excluiu todo o contexto específico do usuário do sistema para que as consultas de recuperação subsequentes não retornassem resultados – efetivamente excluímos o conhecimento de nosso usuário do LLM.
A prefixação de ID nos permite segregar, marcar e posteriormente listar ou excluir dados específicos de uma entidade. Isso nos permite estender o RAG para uma arquitetura que fornece garantias quanto à exclusão de dados.
Os dados mais seguros são aqueles que você não armazena
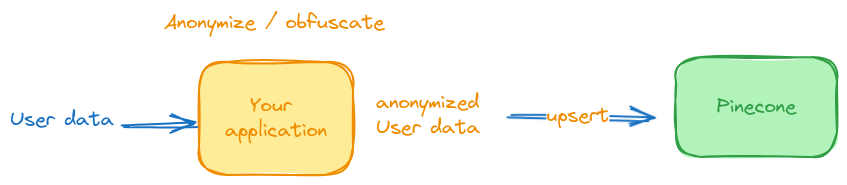
Tokenização para ofuscar dados do usuário
Muitas vezes você pode evitar armazenar informações de identificação pessoal inteiramente em um banco de dados vetorial. Em vez disso, você pode manter seus usuários seguros armazenando referências ou chaves estrangeiras para outros sistemas, como o ID da linha em seu banco de dados privado onde reside o registro completo do usuário.
Você pode manter os registros completos do usuário em um sistema de armazenamento criptografado e seguro no local ou hospedado por um provedor de serviços em nuvem. Isso reduz o número total de sistemas que veem os dados do usuário.
Esse processo às vezes é chamado de tokenização, que é análogo à forma como os modelos convertem palavras nos prompts que enviamos nos IDs das palavras em um determinado vocabulário. Você pode usar nossa demonstração interativa de tokenização aqui para explorar esse conceito.
Suponha que seu aplicativo possa fornecer uma tabela de consulta ou um processo de tokenização reversível. Nesse caso, você pode gravar suas chaves estrangeiras nos metadados associados aos seus vetores durante a inserção no banco de dados de vetores, em vez de valores de texto simples que tornam os dados do usuário visíveis.
As chaves estrangeiras podem ser qualquer coisa significativa para seu aplicativo: IDs de linha do PostgreSQL, IDs em seu banco de dados relacional onde você mantém registros de usuários, URLs ou nomes de bucket S3 que podem ser usados para procurar dados adicionais.
Ao atualizar seus vetores, você pode anexar quaisquer metadados que desejar:
Ofuscando dados do usuário com hash
Você pode usar hash para ocultar os dados do usuário antes de gravá-los nos metadados.
Ocultar não é criptografia. Ocultar os dados do usuário não oferece as mesmas proteções que criptografá-los, mas pode dificultar o vazamento acidental de PII.
Seu aplicativo fornece a lógica para fazer hash das PII do usuário antes de anexá-las aos vetores associados como metadados:
Existem muitos tipos de operações de hash, mas em um alto nível, elas convertem os dados de entrada em uma série de caracteres que não fazem sentido por si só, mas podem ser reversíveis ou quebráveis por um invasor.
Seu aplicativo pode ofuscar os dados do usuário de várias maneiras, incluindo hashing de mensagens inseguro ou codificação base64, antes de gravar valores nos metadados:
Com os dados do usuário com hash e armazenados como metadados, seu aplicativo executa consultas por meio da mesma lógica de hash para derivar os valores do filtro de metadados.
O banco de dados vetorial retorna os resultados mais relevantes para sua consulta como antes.
Seu aplicativo então desofusca os dados do usuário antes de operá-los ou devolvê-los ao usuário final:
Esta abordagem fornece defesa adicional em profundidade. Mesmo que um invasor pudesse acessar seu armazenamento de vetores, ele ainda precisaria reverter o hash no nível do aplicativo para obter os valores de texto simples.
Criptografando e descriptografando metadados
Ofuscar e fazer hash dos dados do usuário é melhor do que armazená-los em texto simples, mas é insuficiente para proteger contra um invasor qualificado e motivado.
Criptografar metadados antes de cada upsert, criptografar novamente os parâmetros de consulta para realizar consultas e descriptografar a saída final de cada solicitação pode introduzir uma sobrecarga significativa em seu sistema, mas é a melhor maneira de garantir que seus dados de usuário estejam seguros e que seu armazenamento de vetores não tem conhecimento dos dados confidenciais sobre os quais está atendendo consultas.
Tudo na engenharia é uma troca, e você precisará equilibrar cuidadosamente o impacto no desempenho da criptografia e descriptografia constantes, além da sobrecarga de manutenção e rotação segura de suas chaves privadas, com os riscos de vazamento de dados confidenciais do cliente.
Retenção e exclusão de dados em bancos de dados vetoriais
Se você seguir a convenção recomendada de implementação de multitenancy mantendo namespaces separados, poderá descartar convenientemente tudo armazenado nesse namespace com uma única operação.
Para excluir todos os registros de um namespace, especifique o apropriado deleteAll parâmetro para o seu cliente e fornecer um namespace parâmetro assim:
Criar software de IA com reconhecimento de privacidade é possível com planejamento
A construção bem-sucedida de software de IA com reconhecimento de privacidade requer consideração e classificação antecipada dos dados que você planeja armazenar.
É necessário deixar para você manipuladores cuidadosos para segmentos de conteúdo, como vimos com o prefixo de ID e a filtragem de metadados, que você pode usar para excluir com eficiência o conhecimento de usuários ou organizações inteiras do seu sistema.
Com um banco de dados vetorial Pinecone em sua pilha e algum planejamento cuidadoso, você pode construir sistemas de IA generativos que respondam igualmente às necessidades dos usuários e respeitem sua privacidade.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Zachary Proser é um desenvolvedor defensor da equipe da Pinecone, onde cria aplicativos de IA em público para ensinar outras pessoas como criar sistemas escaláveis, seguros e que respeitam a privacidade. Zachary é um hacker de código aberto que escreve software há 12 anos….
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.



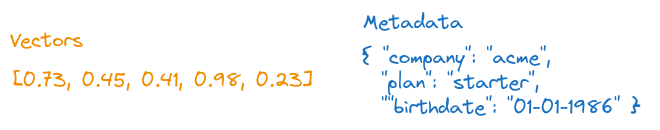
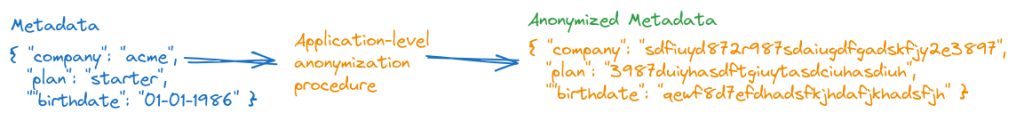




{kind=link}
{kind=link}
{kind=link}