
Acelere o feedback do fluxo de trabalho do GitHub
3 de junho de 2024
Não construa seu futuro em bancos de dados de vetores especializados
3 de junho de 2024
Em meu tutorial anterior, mostrei como trazer dados em tempo real para LLMs por meio de chamadas de função, usando o LLM GPT-4o mais recente da OpenAI. Neste acompanhamento, analisarei a chamada de funções usando Hermes 2 Pro – Llama-3 8B, um poderoso LLM desenvolvido pela Nous Research e baseado na arquitetura Llama 3 da Meta, com 8 bilhões de parâmetros. É um modelo aberto e iremos executá-lo na inferência de geração de texto do Hugging Face.
Assim como na postagem anterior, integraremos a API do Flightaware.com — com o LLM para rastrear o status do voo em tempo real.
O AeroAPI da FlightAware é uma ferramenta perfeita para os desenvolvedores obterem acesso a informações abrangentes de voo. Ele permite rastreamento de voos em tempo real, dados históricos e futuros de voos e pesquisas de voos por vários critérios. A API apresenta dados em um formato JSON fácil de usar, tornando-os altamente utilizáveis e integráveis. Chamaremos a API REST para obter o status em tempo real de um voo com base no prompt enviado a um LLM pelo usuário.
O que é o Hermes 2 Pro?
Hermes 2 Pro – Llama-3 8B é excelente em tarefas de processamento de linguagem natural, escrita criativa, assistência de codificação e muito mais. Uma de suas características de destaque é a excepcional capacidade de chamada de funções, que permite executar funções externas e recuperar informações relacionadas a preços de ações, fundamentos da empresa, demonstrações financeiras e muito mais.
Este modelo aproveita um prompt de sistema especial e uma estrutura de chamada de função multivoltas com uma nova função ChatML, tornando a chamada de função confiável e fácil de analisar. De acordo com benchmarks, Hermes 2 Pro – Llama-3 obteve impressionantes 90% na avaliação de chamada de função construída em parceria com Fireworks AI.
Implantando Hermes 2 Pro localmente
Para esta configuração, estou usando um servidor Linux equipado com uma GPU NVIDIA GeForce RTX 4090, que vem com 24 GB de VRAM. Ele está executando o Docker e o NVIDIA Container Toolkit para permitir que contêineres acessem a GPU.
Usaremos o servidor Text Generation Inference da Hugging Face para executar o Hermes 2 Pro.
O comando abaixo inicia o mecanismo de inferência na porta 8080 e atende o LLM por meio de um endpoint REST.
export token="YOUR_HF_TOKEN" export model="NousResearch/Hermes-2-Pro-Llama-3-8B" export volume="/home/ubuntu/data" docker run --name hermes -d --gpus all -e HUGGING_FACE_HUB_TOKEN=$token --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:2.0.3 --model-id $model --max-total-tokens 8096
To test the endpoint, run the following command:
curl 127.0.0.1:8081
-X POST
-H 'Content-Type: application/json'
-d '{"inputs":"What is Deep Learning?"}'
Se tudo estiver certo, você deverá ver a resposta do Hermes 2 Pro.
Função para rastrear o status do voo
Antes de continuar, inscreva-se no FlightAware e obtenha sua chave API, necessária para usar a API REST. O nível pessoal gratuito é suficiente para concluir este tutorial.
Depois de ter a chave API, crie a função abaixo em Python para recuperar o status de qualquer voo.
Embora o código seja simples, deixe-me explicar as principais etapas.
Esta função, get_flight_status pega um parâmetro de voo (assumido como um identificador de voo) e retorna detalhes de voo formatados em formato JSON. Ele consulta a AeroAPI para buscar dados de voo com base no identificador de voo fornecido e formata detalhes importantes, como origem, destino, horário de partida, horário de chegada e status.
Vejamos os componentes do script:
Credenciais de API:
AEROAPI_BASE_URL é o URL base do FlightAware AeroAPI.
AEROAPI_KEY is the API key usado para autenticação.
Gerenciamento de sessão:
get_api_session: esta função aninhada inicializa uma solicitação. Isso define o cabeçalho necessário com a chave de API e retorna o objeto de sessão. Esta sessão tratará de todas as solicitações de API.
Busca de dados:
fetch_flight_data: Esta função leva ID_do_voo e sessão como argumentos. Ele constrói o URL do terminal com filtros de data apropriados para buscar dados de um dia e envia uma solicitação GET para recuperar os dados do voo. A função trata a resposta da API e extrai as informações relevantes do voo.
Conversão de tempo:
utc_to_local: converte a hora UTC (da resposta da API) em hora local com base na string de fuso horário fornecida. Esta função nos ajuda a obter os horários de chegada e saída de acordo com a cidade.
Processamento de dados:
O script determina chaves para horários de partida e chegada com base na disponibilidade de horários estimados ou reais, com retorno aos horários programados. Em seguida, ele constrói um dicionário contendo detalhes de voo formatados.

A captura de tela acima mostra a resposta que recebemos da API FlightAware para o voo EK524 da Emirates que voa de Dubai para Hyderabad. Observe que os horários de chegada e partida são horários locais baseados na cidade.
Nosso objetivo é integrar esta função ao Gemini 1.0 Pro para fornecer acesso em tempo real às informações de rastreamento de voos.
Integrando a função com Hermes 2 Pro
Comece instalando a versão mais recente do Hugging Face Python SDK com o comando abaixo:
pip install --upgrade huggingface_hub
Importe o módulo e inicialize o cliente apontando-o para o endpoint TGI.
from huggingface_hub import InferenceClient
client = InferenceClient("http://127.0.0.1:8080")
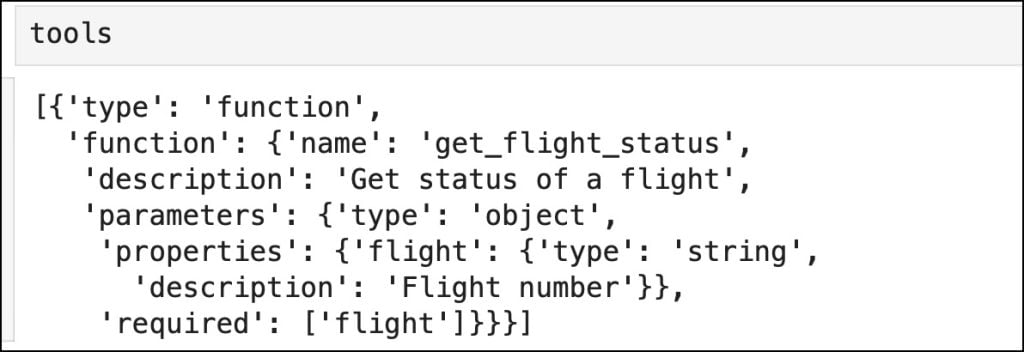
A seguir, defina o esquema da função no mesmo formato da chamada da função OpenAPI.
tools = (
{
"type": "function",
"function": {
"name": "get_flight_status",
"description": "Get status of a flight",
"parameters": {
"type": "object",
"properties": {
"flight": {
"type": "string",
"description": "Flight number"
}
},
"required": ("flight")
}
}
}
)
Isto preenche a lista com uma ou mais funções que o LLM pode usar como ferramentas.
Agora criaremos o chatbot que aceita o prompt e determina se a função precisa ser chamada. Se sim, então o LLM primeiro retorna o nome da função e os argumentos que precisam ser invocados. A saída da função é enviada ao LLM como parte da segunda invocação. A resposta final terá a resposta factualmente correta com base na saída da função.
def chatbot(prompt):
messages = (
{
"role": "system",
"content": "You're a helpful assistant! Answer the users question best you can based on the tools provided. Be concise in your responses.",
},
{
"role": "user",
"content": prompt
},
)
response = client.chat_completion(messages=messages, tools=tools)
tool_calls = response.choices(0).message.tool_calls
if tool_calls:
available_functions = {
"get_flight_status": get_flight_status,
}
for tool_call in tool_calls:
function_name = tool_call.function.name
function_to_call = available_functions(function_name)
function_args = tool_call.function.arguments
function_response = function_to_call(flight=function_args.get("flight"))
messages.append(
{
"role": "tool",
"name": function_name,
"content": function_response
}
)
final_response = client.chat_completion(messages=messages)
return final_response
return response
A formatação automática do prompt que o LLM alvo espera é um benefício do uso das bibliotecas Hugging Face Python. Por exemplo, ao usar funções, o prompt do Hermes 2 Pro precisa ser estruturado em um formato específico:
<|im_start|>system
You are a function calling AI model. You are provided with function signatures within XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions. Here are the available tools: ({'type': 'function', 'function': {'name': 'get_stock_fundamentals', 'description': 'Get fundamental data for a given stock symbol using yfinance API.', 'parameters': {'type': 'object', 'properties': {'symbol': {'type': 'string'}}, 'required': ('symbol')}}}) Use the following pydantic model json schema for each tool call you will make: {'title': 'FunctionCall', 'type': 'object', 'properties': {'arguments': {'title': 'Arguments', 'type': 'object'}, 'name': {'title': 'Name', 'type': 'string'}}, 'required': ('arguments', 'name')} For each function call return a json object with function name and arguments within XML tags as follows:
{'arguments': , 'name': }
<|im_end|>
Da mesma forma, a saída da função pode ser enviada ao LLM no formato abaixo:
<|im_start|>tool
{"name": "get_stock_fundamentals", "content": {'symbol': 'TSLA', 'company_name': 'Tesla, Inc.', 'sector': 'Consumer Cyclical', 'industry': 'Auto Manufacturers', 'market_cap': 611384164352, 'pe_ratio': 49.604652, 'pb_ratio': 9.762013, 'dividend_yield': None, 'eps': 4.3, 'beta': 2.427, '52_week_high': 299.29, '52_week_low': 152.37}}
<|im_end|>
Garantir que o prompt siga este modelo requer uma formatação cuidadosa. A classe InferenceClient lida com essa tradução de forma eficiente, permitindo que o desenvolvedor use o formato OpenAI familiar de funções de sistema, usuário, ferramenta e assistente no prompt.
Durante a primeira chamada para a API de conclusão de chat, o LLM responde com a resposta abaixo:

Posteriormente, após invocar a função, incorporamos o resultado na mensagem e o enviamos de volta ao LLM.
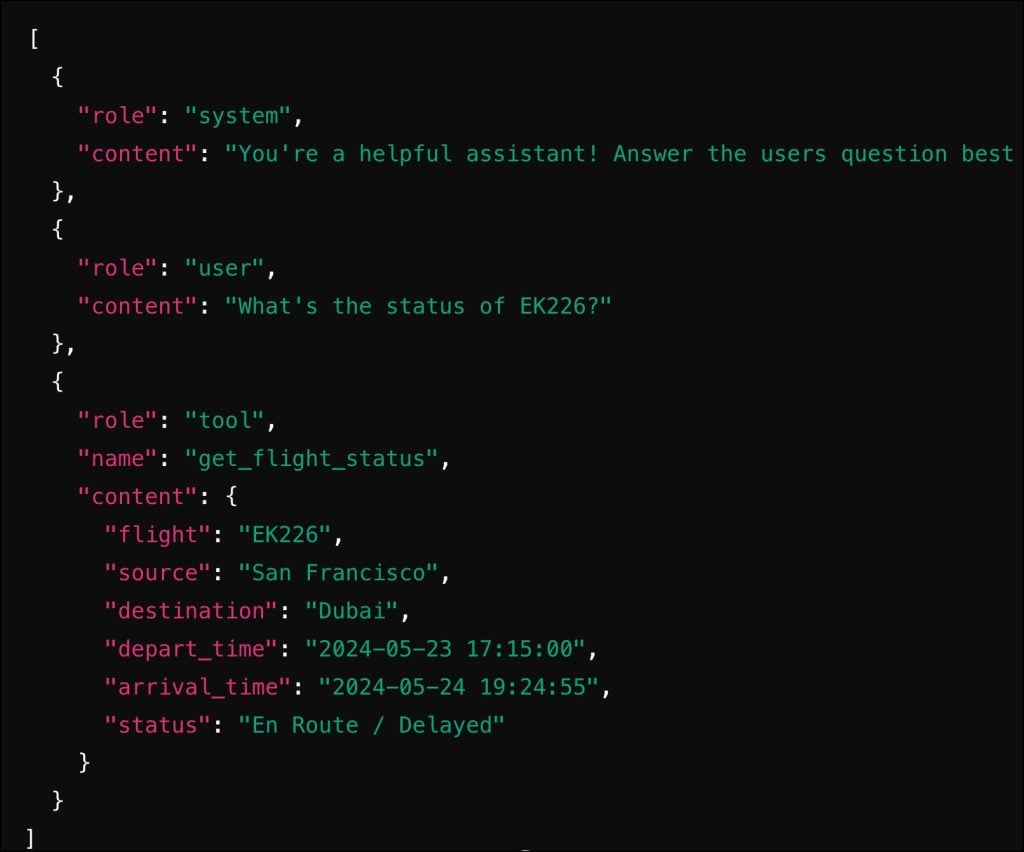
Como você pode ver, o fluxo de trabalho de integração de chamadas de funções é muito semelhante ao do OpenAI.
É hora de invocar o chatbot e testá-lo por meio de um prompt.
res=chatbot("What's the status of EK226?")
print(res.choices(0).message.content)

Isso conclui o tutorial sobre como usar uma técnica de chamada de função com o modelo aberto, Hermes 2 Pro. O código completo do chatbot é mostrado abaixo.
A postagem Construindo um aplicativo LLM aberto usando Hermes 2 Pro implantado localmente apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}
{kind=link}