O Apache Kafka é amplamente utilizado em organizações maiores para armazenar e trocar dados, mas tem um grande problema: não é possível consultar esses dados facilmente. Alguém deve sempre duplicar os dados em um banco de dados regular para consultá-los. Isto retarda a inovação de dados e força as empresas a construir pipelines onde tudo pode acontecer.
Permitir que cada membro da equipe de uma organização acesse e utilize dados em tempo real usando a solução que desejam é uma estratégia transformadora que impulsiona a adoção generalizada e a eficiência operacional. Isto capacita não apenas os desenvolvedores, mas também os analistas de negócios, cientistas de dados e tomadores de decisão a construir uma cultura orientada a dados.
Kafka é apenas para streaming de ETL?
Kafka era de código aberto em 2011, quando bancos de dados massivos e big data eram reis. Desde então, aprendemos muito sobre como usar essa nova forma de mover e transformar dados e, ao mesmo tempo, mantê-los em movimento.
Hoje, o Kafka é usado principalmente para mover dados de maneira confiável para um destino com o qual todos possam trabalhar. Pode ser um banco de dados, data warehouse ou data lake que os usuários podem consultar (como PostgreSQL, ClickHouse, Elasticsearch ou Snowflake) e com os quais a equipe de análise pode trabalhar e que pode ser usado para construir painéis e modelos de aprendizado de máquina. O Kafka costuma ser usado apenas por seus recursos em tempo real e não contém dados históricos – a retenção de dados padrão no Kafka é de apenas alguns dias, após os quais os dados são excluídos automaticamente.
Kafka é combinado com tecnologias de processamento de stream como Kafka Streams, Apache Spark ou Apache Flink para fazer transformações, filtrar os dados, enriquecê-los com dados dos usuários e talvez fazer algumas junções entre várias fontes. Kafka é ótimo para construir extração, transformação e carregamento de streaming (ETL), que captura, transforma e carrega dados para outro local em tempo real, em contraste com o processamento em lote tradicional, que é definido de forma programada (a cada X minutos).
Tudo parece bem, mas o Kafka tem uma grande desvantagem: ele não torna os dados acessíveis.
Kafka não é muito bom para consultas
O Apache Kafka costuma ser o local onde todos os dados de uma organização são criados antes de serem movidos para outros aplicativos. Então, todos os aplicativos se comunicam e produzem dados por meio do Kafka. Mas, de alguma forma, esses dados são pouco acessíveis a não desenvolvedores, incluindo cientistas de dados, analistas e proprietários de produtos.
Explorar e trabalhar com dados não é nem mesmo simples para desenvolvedores porque não existe uma linguagem simples como SQL para falar sobre dados com Kafka. Freqüentemente, você precisa de ferramentas externas como o Conductor ou ferramentas avançadas de linha de comando em seu terminal para examinar e analisar os dados – mas isso só pode ir até certo ponto.
Nem todos em uma organização entendem de tecnologia, e as organizações desejam fornecer uma experiência consistente para que todos se comuniquem igualmente. Por exemplo, eles querem que toda a equipe, não importa o quão confortável esteja com a tecnologia, seja capaz de trabalhar em um novo projeto sem ter que aprender novas ferramentas complexas.
No espaço Kafka, as organizações dependem de equipes de engenharia de dados para construir os pipelines e ETL necessários para tornar os dados acessíveis. Essas equipes também usam ferramentas de captura de dados alterados (CDC), como o Debezium, para mover os dados para fora do Kafka, o que dilui a propriedade, a segurança e as responsabilidades dos dados.
Mas Apache Kafka não é um banco de dados… é?
Como Martin Kleppmann discutiu em sua palestra “Is Kafka a Database?” no Kafka Summit SF 2018: Kafka pode atingir todos os requisitos de atomicidade, consistência, isolamento e durabilidade (ACID) de um banco de dados construindo processadores de fluxo. Kafka também tem suporte completo para transações exatamente uma vez, e a proposta KIP-939 do Apache está surgindo para oferecer suporte ao protocolo two-phase commit (2PC) para fazer transações distribuídas com outros bancos de dados.
Curiosamente, Kleppman concluiu que “não há consultas ad-hoc, com certeza”, e você deve mover seus dados para um banco de dados real para tais assuntos. Seis anos depois, esta é a única ressalva que ainda está presente e atrasa todos que desejam trabalhar com Kafka.
Lidando com a bagunça de dados
As organizações têm toneladas de dados em Kafka e bancos de dados. A qualidade dos dados varia. As regras não são as mesmas em todos os lugares. Ninguém tem a mesma visão de tudo. É difícil saber quais dados estão onde ou onde está a fonte da verdade. É o que chamamos de confusão de dados.
A duplicação de dados do Kafka para bancos de dados adiciona uma espessa camada de complexidade. Devido a modelos de segurança fundamentalmente diferentes, a propriedade e a segurança dos dados tornam-se frágeis e possivelmente inconsistentes. Kafka tem sua maneira de proteger os dados e os bancos de dados têm outra maneira. Essa incompatibilidade de segurança é difícil de corrigir e, se você adicionar requisitos como mascaramento de dados ou criptografia em nível de campo, será quase impossível.
É assim que acontecem os vazamentos de dados. Por exemplo, em Março, uma violação do governo francês expôs dados de até 43 milhões de pessoas. Estes incidentes sustentam uma clara deficiência de competências, consistência e maturidade no ecossistema.
A rápida multiplicação de produtos de dados agrava a fragmentação do panorama de dados dentro das organizações. Esta proliferação cria silos de dados, cada um operando isoladamente, diluindo o potencial de uma estratégia de dados unificada. O desenvolvimento ad hoc de pipelines de dados, construídos fora de uma estrutura de governação coesa, deixa as organizações vulneráveis a imprecisões e inconsistências.
SQL é o jogo final?
SQL é uma linguagem de programação muito conhecida e popular, classificada em 6º lugar no Índice TIOBE e usada por 40% dos desenvolvedores em todo o mundo – com notáveis 78% deles utilizando SQL frequentemente em seu trabalho.
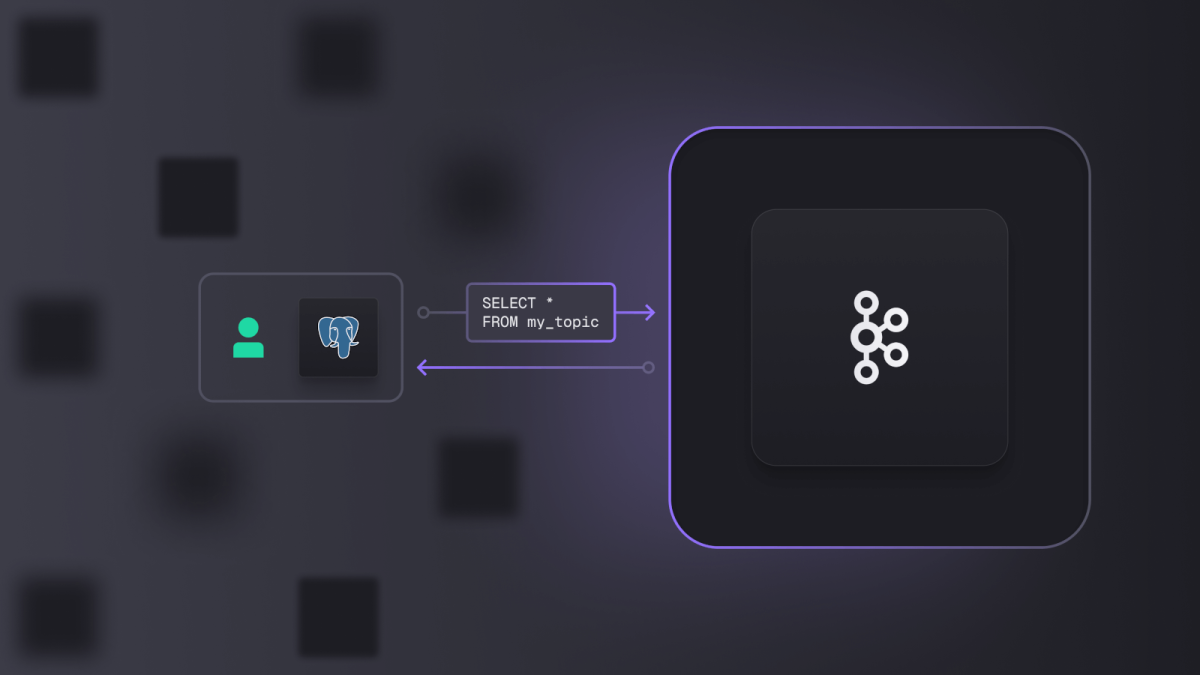
Quando falamos de SQL, temos que falar de PostgreSQL. Ele emergiu como o principal protocolo de banco de dados e todos os fornecedores envolvidos em dados desejam ser compatíveis com ele. Ferramentas como Grafana, Metabase, Tableau, DBeaver e Apache Superset podem se conectar a serviços que oferecem um endpoint compatível com PostgreSQL. Ter uma plataforma Kafka que fornece esse ponto de extremidade para qualquer tópico permite o uso dessas ferramentas para visualização de dados e introspecção direta.
SQL oferece uma base sólida para a construção de um ecossistema de dados unificado, com Kafka servindo como a única fonte de verdade em seu núcleo. O PostgreSQL se destaca por sua ampla compatibilidade e facilidade de introdução graças a muitos fornecedores acessíveis. Sua natureza de código aberto, integração perfeita com ambientes de desenvolvimento e configuração e gerenciamento simples fazem dele a escolha preferida de banco de dados em termos de escalabilidade, versatilidade, flexibilidade e robustez.
Ao modernizar o Kafka para incorporar recursos SQL, podemos reduzir significativamente a necessidade de pipelines de dados e replicação. Também conduzirá à eficiência global, à eficiência de custos, à governação mais simples e a menos falhas de segurança.
Isto também integraria engenheiros de dados diretamente nas equipes de produto, em vez de mantê-los isolados em seus próprios silos com seus próprios roteiros de dados, fortalecendo a colaboração entre desenvolvedores e equipes de análise.
Indo mais longe com IA e aprendizado de máquina (ML)
SQL é perfeito para análises ad hoc, painéis ou construção de pipelines de dados. Mas não é o melhor para lidar com os enormes volumes de dados necessários para ciência de dados e IA/ML. É aqui que brilham tecnologias como Apache Parquet e Apache Iceberg.
Eles fornecem sistemas baseados em colunas e otimizações de filtro pushdown que consultam com eficiência grandes quantidades de dados. Muitos cientistas de dados os adoram porque podem ser consultados com suas ferramentas, como Apache Spark, Pandas, Dask e Trino. Isso melhora a acessibilidade aos dados e simplifica a criação de aplicativos de IA/ML.
Conforme compartilhamos em nossa análise do Kafka Summit London 2024, a capacidade do Kafka de servir como a única fonte da verdade — à medida que as organizações procuram expor dados no Kafka em vários formatos — está se tornando uma realidade. A Confluent anunciou o TableFlow, que materializa perfeitamente os tópicos do Apache Kafka como tabelas do Apache Iceberg sem a necessidade de construir e manter pipelines de dados.
Preparando o caminho para liberar dados
O Conductor e o Kafka, com recursos para dar suporte às necessidades de dados em tempo real, atendem ao processamento analítico online (OLAP) e aos requisitos de negócios usando SQL. Eles também atendem às demandas de IA/ML com formatos de arquivo como Parquet e Iceberg. Dessa forma, eles estão abrindo caminho para um futuro onde os dados serão verdadeiramente acessíveis e otimizados para diversas preferências de consumo. Construir produtos de dados verdadeiros e eliminar a necessidade de duplicação técnica em diferentes armazenamentos de dados levará a um ecossistema de dados mais eficiente e seguro.
Se você deseja liberar seus dados e torná-los mais acessíveis em sua organização e, ao mesmo tempo, remover atritos de governança e segurança, agende uma demonstração do Conductor.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Stephane Derosiaux é cofundador e CTO da Conductor. Entusiasta do Apache Kafka, ele se dedica a criar a melhor experiência de streaming de dados para desenvolvedores e organizações. Ele tem mais de 15 anos de experiência em engenharia de software e dados, adquirido…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.





{kind=link}
{kind=link}
{kind=link}