
Microsoft renova HDInsight, seu robusto serviço de Big Data
24 de janeiro de 2024
Gotemburgo, Suécia, usou IoT de código aberto para reduzir drasticamente o desperdício de água
24 de janeiro de 2024
Com microsserviços, cada equipe lida com partes menores do aplicativo por vez, modularizando o desenvolvimento e a complexidade operacional. Por outro lado, porém, criou-se a necessidade de validar e testar se todas as peças estão funcionando bem juntas. Essa necessidade deu origem a muitas novas classes de soluções nos últimos anos — ambientes efêmeros, ambientes sob demanda, ambientes de visualização, etc. Eles compartilham um propósito comum: ajudar a garantir que a funcionalidade funcione como um todo, o mais cedo possível no ciclo de vida de desenvolvimento.
Todas essas classes de ambientes de microsserviços têm sido tradicionalmente configuradas como cópias totalmente separadas de todo o conjunto de microsserviços. Essas pilhas podem, de fato, compartilhar a infraestrutura subjacente – como executar no mesmo cluster Kubernetes em diferentes namespaces, ou executar em clusters de nó único, ou mesmo (em uma escala menor), como contêineres Docker em algum nó local ou remoto. No entanto, essa noção de executar pilhas de cada microsserviço e todas as suas dependências separadamente umas das outras tem algumas desvantagens:
- Dimensionamento de custos: Eles aumentam os custos com o número de microsserviços e muitas vezes acabam precisando de soluções alternativas para manter os custos sob controle, tanto em termos de esforço de manutenção quanto de gastos com infraestrutura. As implicações de custo podem fazer com que os desenvolvedores façam fila em algum ambiente compartilhado para realizar seus testes.
- Dependências obsoletas e divergência da produção: cada ambiente contém sua própria cópia de cada dependência, o que é difícil de manter sincronizado, especialmente porque as alterações são feitas em cada microsserviço e enviadas continuamente. Além disso, outra forma de divergência que ocorre é que as dependências e integrações de terceiros com serviços em nuvem podem se comportar de maneira diferente nesses ambientes de preparação ou produção, aumentando a probabilidade de uma classe de problemas “funcionou no teste, mas não na produção”.
- Maior sobrecarga operacional: os custos operacionais aumentam mesmo que uma pessoa possua apenas um microsserviço na pilha.
- Experiência de desenvolvedor abaixo do ideal: é difícil para uma equipe de plataforma oferecer suporte a cada um desses ambientes, o que muitas vezes leva a uma experiência ruim para o desenvolvedor e ao baixo uso. O tempo necessário para configurar o ambiente também afeta a produtividade do desenvolvedor. Quanto mais microsserviços você tiver, mais lento será o surgimento desses ambientes.
Muitas soluções alternativas foram exploradas para ajudar a lidar com isso na prática, mas quero apresentar uma maneira diferente de pensar sobre ambientes que traz vários benefícios em relação às abordagens anteriores.
![]()
Signadot é uma plataforma de teste nativa do Kubernetes para microsserviços. Usando o Signadot, as equipes de engenharia “mudam para a esquerda” nos testes para detectar problemas mais cedo e aumentar a confiança no lançamento.
Saber mais
As últimas novidades da Signadot
$(document).ready(function() { $.ajax({ método: ‘POST’, url: ‘/no-cache/sponsors-rss-block/’, headers: { ‘Cache-Control’: ‘no- cache, no-store, must-revalidate’, ‘Pragma’: ‘no-cache’, ‘Expires’: ‘0’ }, dados: { patrocinadorSlug: ‘signadot’, numItems: 3 }, sucesso: função (dados) { if (data.startsWith(‘ERROR’)) { console.log(data); $(‘.sponsor-note-rss’).hide(); } else { $(‘.sponsor-note-rss-items -signadot’).html(dados); } } }); });
Repensando ambientes de microsserviços
Quando desenvolvemos microsserviços, cada desenvolvedor ou equipe de desenvolvimento trabalha para mudar uma pequena parte do todo. Independentemente da frequência com que os lançamentos chegam à produção, é comum que cada microsserviço tenha seu próprio processo de CI/CD que envia atualizações para algum ambiente superior, como o de teste. Dada essa configuração e o desejo de testar no início do ciclo de vida de desenvolvimento, podemos pensar em cada ambiente de desenvolvimento/pré-visualização/teste de microsserviço como uma combinação do que mudou e das versões “mais recentes” de todo o resto.
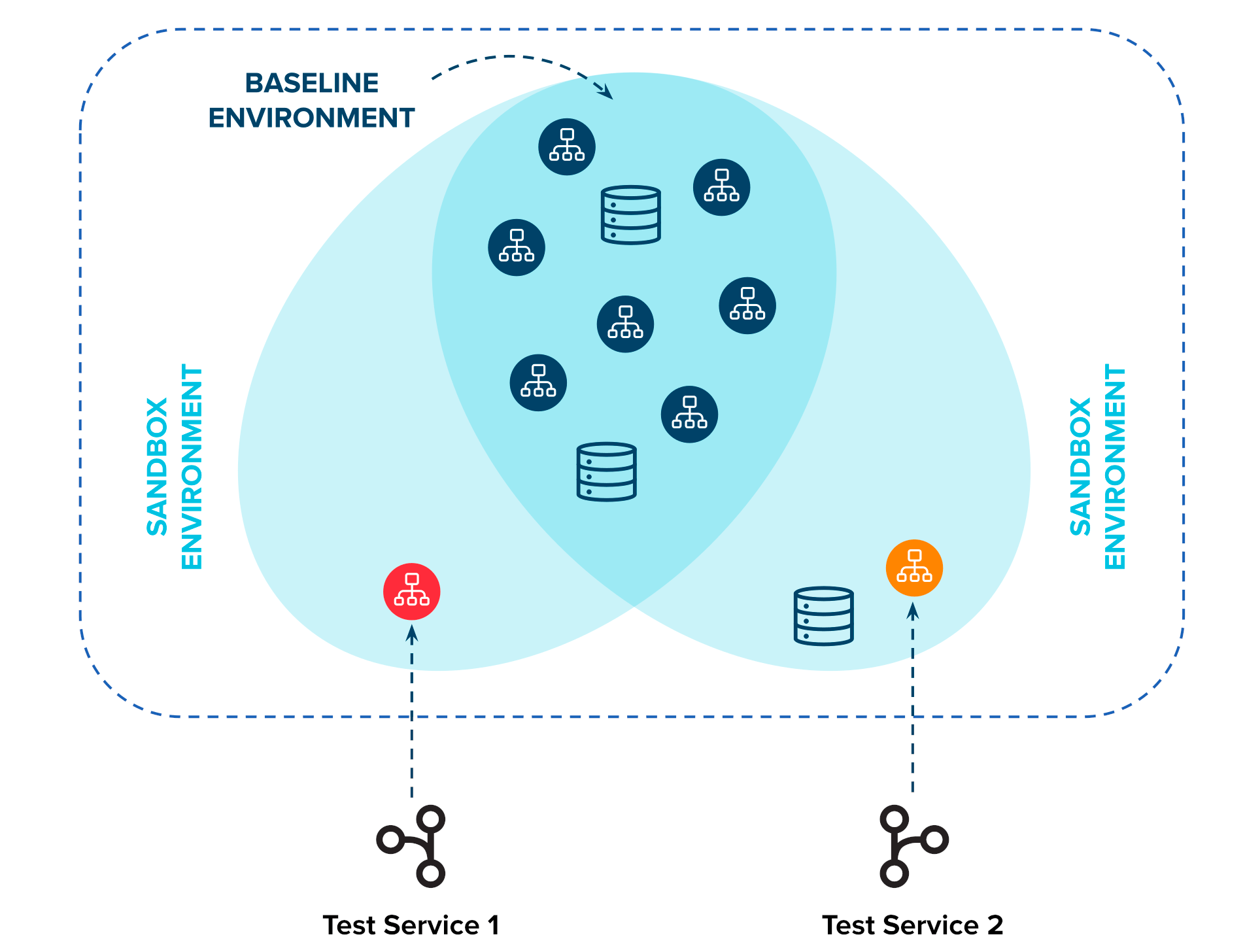
Conforme mostrado acima, definimos as versões mais recentes de todos os microsserviços na pilha como o ambiente de linha de base. O ambiente de linha de base serve como a versão padrão de cada dependência de microsserviço para qualquer ambiente configurado e atualizado continuamente a partir de cada processo de CI/CD. Geralmente é um único cluster Kubernetes, como teste (ou mesmo produção). Para cada novo ambiente de desenvolvimento/teste/visualização, implantamos apenas “o que mudou” (referido como sandbox acima), que geralmente é um pequeno número de microsserviços em comparação com o número geral, e compartilhamos quaisquer dependências inalteradas com o ambiente de linha de base .
Esta metodologia compartilha algumas semelhanças com o canarying na produção, mas neste caso, há uma ênfase maior no isolamento suficiente de microsserviços para criar sandboxes que possam ser usadas durante o processo de desenvolvimento. Na seção a seguir, veremos como esse sistema de ambientes sandbox pode ser construído na prática.
Solicitar locação
Na seção anterior, examinamos a construção lógica de um sandbox, que combina itens em teste com um conjunto comum de dependências do ambiente de linha de base. Na prática, tal sistema baseia-se em duas ideias principais: solicitação de locação e roteamento.
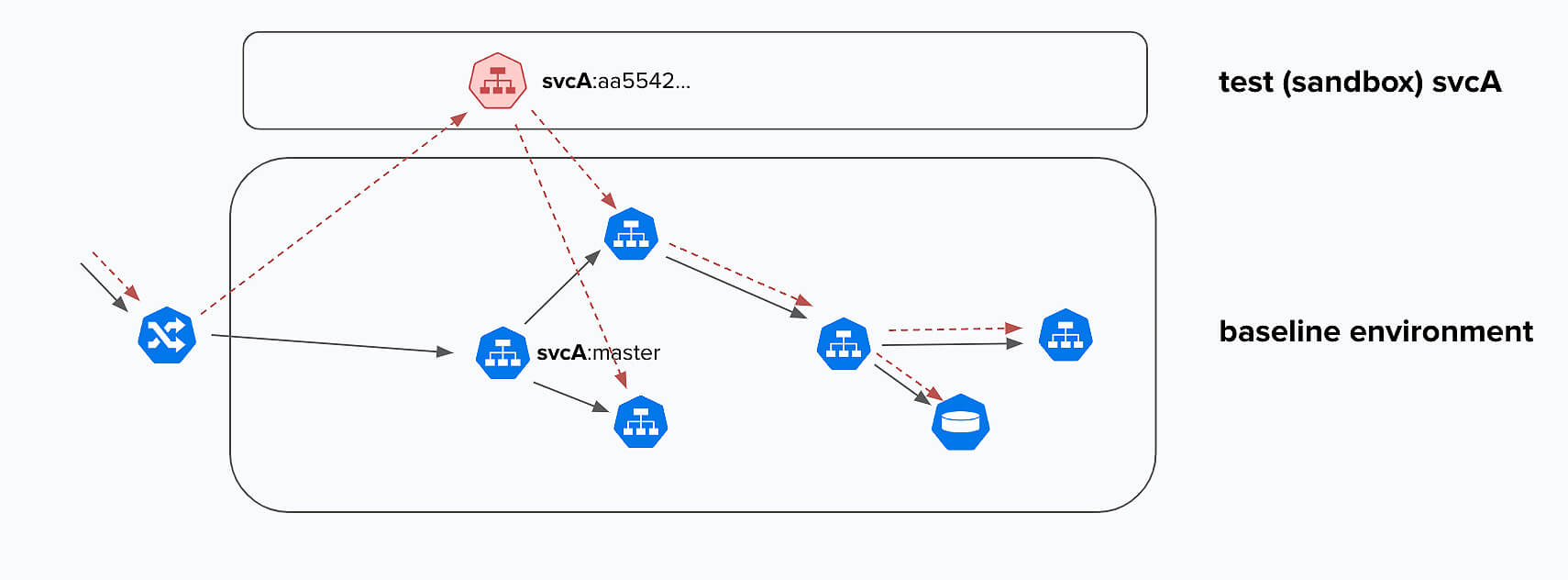
Tomando a figura acima, assumimos que uma solicitação pode ser marcada com um identificador especial, algo que indica qual inquilino está enviando a solicitação. Contanto que essas informações de locação sejam transmitidas ao longo da cadeia de serviço para serviço à medida que a chamada atravessa o sistema, podemos tomar uma decisão de roteamento usando aquela locação específica para decidir que uma solicitação específica deve ser atendida por um serviço “em área restrita” svcA em vez da versão mais recente da versão da linha de base do svcA. Então, precisamos de dois componentes para fazer esse tipo de fluxo:
- Uma forma de marcar solicitações com locação usando um identificador especial à medida que fluem por uma rede de microsserviços.
- Uma forma de tomar uma decisão de roteamento localizada com base na presença do identificador especificado acima.
Felizmente, essa noção de passar um contexto de solicitação tornou-se simples nos microsserviços modernos, graças ao OpenTelemetry. Com a instrumentação OpenTelemetry em microsserviços, essa funcionalidade já está disponível. Um cabeçalho de bagagem especial é encaminhado automaticamente para o próximo microsserviço subsequente. Assim, desde que o OpenTelemetry seja usado para instrumentar nossos microsserviços, teremos a capacidade de marcar uma solicitação automaticamente, sem nenhum esforço adicional.
Agora, quando se trata de realmente tomar a decisão de roteamento, a solução mais natural são malhas de serviço como Istio, Linkerd, etc. Essas malhas permitem a criação de regras para tomar exatamente esses tipos de decisões de roteamento localizadas. Portanto, terminamos com algo assim:
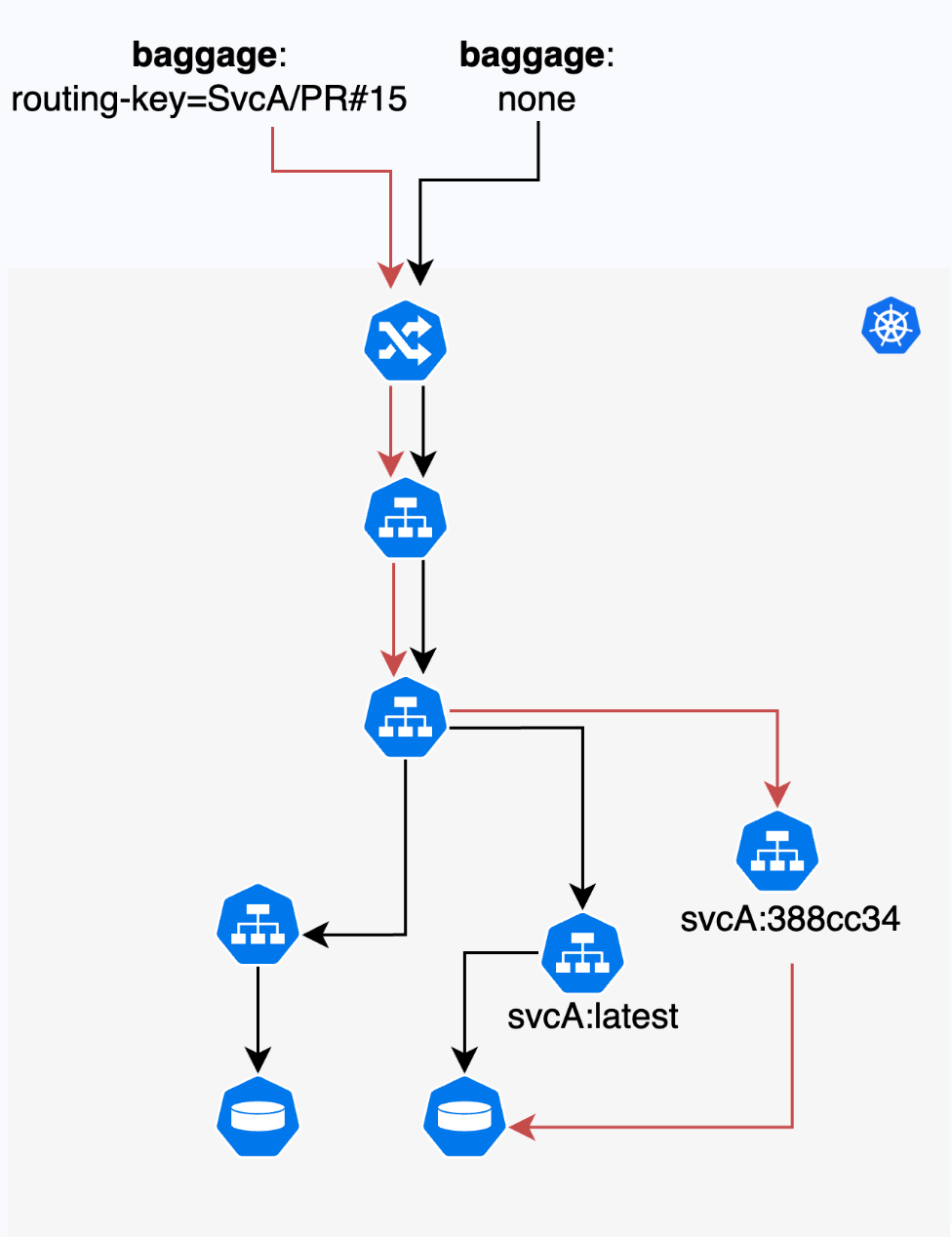
Uma das grandes vantagens de usar esse sistema é que testar vários microsserviços juntos se torna extremamente simples. Freqüentemente, os recursos abrangem vários microsserviços, o que torna difícil testá-los juntos até que todos cheguem a algum ambiente compartilhado comum. Aqui, é possível criar um novo inquilino que seja uma combinação de dois outros inquilinos apenas controlando o identificador com o qual estamos marcando a solicitação, o que ajuda a introduzir novas formas de colaboração durante o processo de construção de microsserviços.
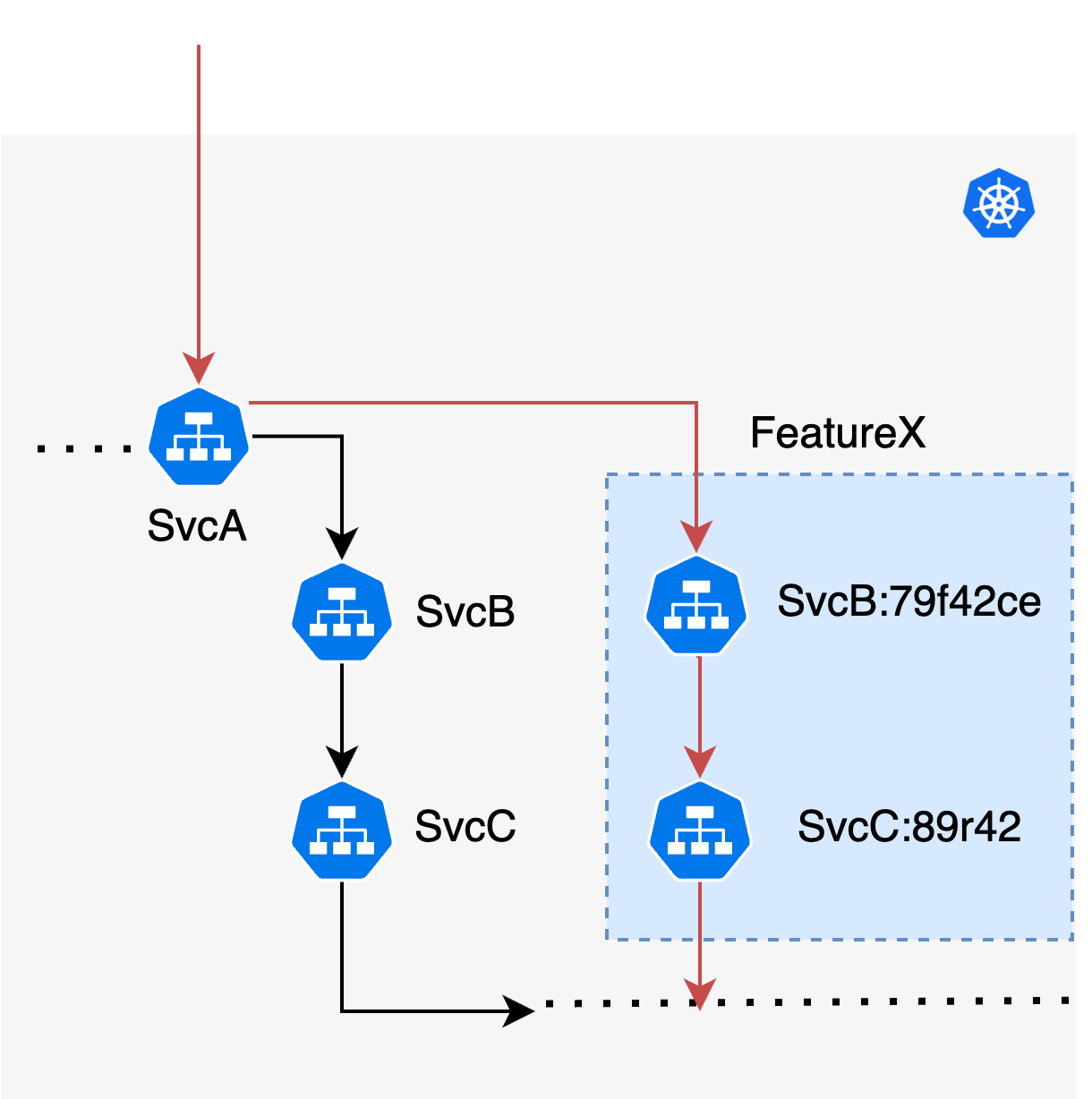
Isolamento de dados
Acima, usamos um microsserviço simples sem estado, onde usamos um protocolo L7 como HTTP ou gRPC, o que facilitou a rotulagem e o roteamento de solicitações. Na prática, existem bancos de dados, filas de mensagens, dependências de nuvem, webhooks, etc., para os quais o isolamento usando a locação de solicitação pode não ser suficiente.
Por exemplo, testar alterações de esquema em um banco de dados usado por um microsserviço pode exigir a configuração de uma instância de banco de dados efêmera ou de bancos de dados lógicos para realizar o isolamento necessário. Nestes casos em que a locação da solicitação é insuficiente, você pode usar um nível de isolamento mais alto. Normalmente, existem dois níveis mais elevados de isolamento que são normalmente usados: isolamento lógico e isolamento de infraestrutura.
O isolamento lógico ocorre quando você usa a mesma infraestrutura subjacente (digamos, cluster de banco de dados PostgreSQL), mas configura alguma unidade de locação abaixo, como um novo banco de dados ou um esquema para aquele locatário específico. O isolamento da infraestrutura é a solução, oferecendo infraestrutura dedicada para aquele locatário específico, como a configuração de um cluster de banco de dados PostgreSQL separado. Em ambos os casos, você pode usar mecanismos de configuração como variáveis de ambiente/mapas de configuração no Kubernetes para conectar o recurso lógico ou físico efêmero ao restante do sandbox.
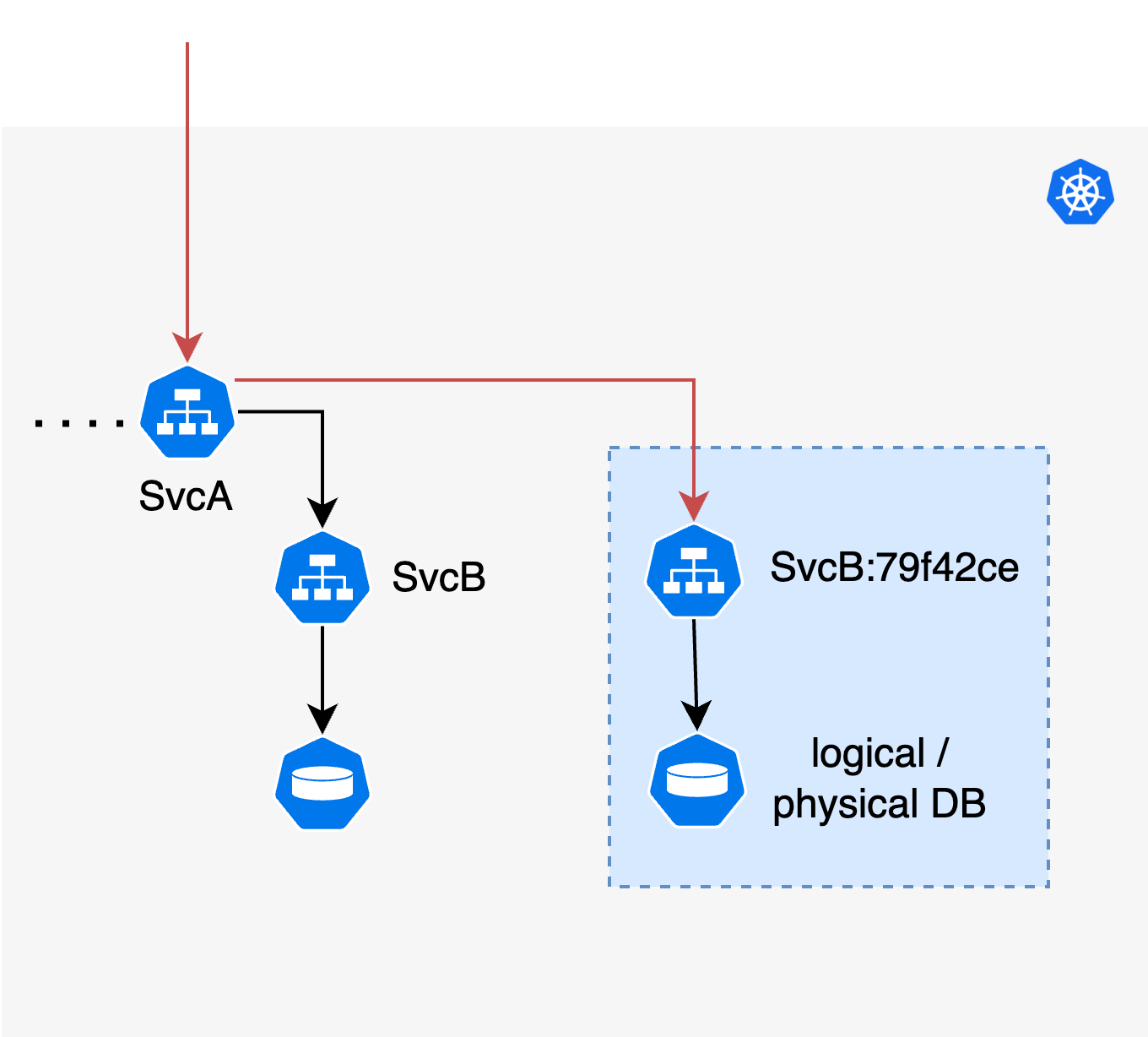
O nível de isolamento a escolher depende do caso de utilização, mas existe uma compensação clara: níveis mais elevados aumentam o trabalho operacional envolvido na criação e gestão da infraestrutura, ao mesmo tempo que oferecem menos interferência de outros intervenientes no resto do sistema. Na prática, na maioria dos casos, o isolamento lógico é suficiente, exceto quando o próprio armazenamento de dados não possui tal provisão, ou em certos cenários de teste de desempenho/carga.
Filas de mensagens
Para filas de mensagens, é mais simples criar informações de locação nas próprias mensagens (como é habilitado pelo OpenTelemetry) e tomar uma decisão no microsserviço consumidor se uma determinada mensagem é relevante para si mesma. A ideia principal aqui é permitir que os consumidores consumam mensagens seletivamente para que não acabem processando mensagens destinadas a um locatário diferente.

Em um sistema como o Apache Kafka, isso é feito configurando um grupo de consumidores separado por locatário e, em seguida, fazendo alterações na camada de aplicação nas bibliotecas de consumidores para implementar esse tipo de lógica para consumir mensagens seletivamente.
Trabalhos assíncronos e dependências de terceiros
Em alguns casos, um microsserviço pode não estar participando de fluxos de solicitações, mas agindo de forma completamente assíncrona, como um cron job que realiza alguma operação periodicamente, ou ser ele próprio um ponto de origem das solicitações. Nesse caso, você ainda pode criar um “sandbox” para uma nova versão dele, mas a locação seria especificada para aquela instância específica em sandbox do próprio microsserviço. Essencialmente, nosso “inquilino” neste contexto torna-se um microsserviço completo, em vez de uma solicitação.
Este mesmo método também se aplica nos casos em que existe uma dependência de terceiros que não respeita os cabeçalhos de locação ou se você estiver usando um protocolo personalizado onde não é possível adicionar metadados de cabeçalho. A ideia principal é voltar a usar a configuração para isolamento sempre que não for possível usar a locação de solicitação.
Conclusão
A abordagem de criação de ambientes usando locação de solicitação e isolamento ajustável resolve várias desvantagens da configuração tradicional de ambientes de visualização, teste e desenvolvimento no Kubernetes. Especificamente, como estamos implantando o mínimo de microsserviços necessários para cada ambiente, isso é altamente econômico, mesmo em escala, como evidenciado por empresas que executam várias centenas desses sistemas internamente, como o SLATE da Uber, o Staging Overrides da Lyft e o Doordash.
Ele também garante testes de alta fidelidade com as dependências mais recentes e é rápido de configurar, trazendo ganhos em termos de experiência e produtividade do desenvolvedor. Essa abordagem permite novas maneiras de colaborar de maneira mais integrada entre desenvolvedores e equipes de desenvolvimento que trabalham em diferentes microsserviços.
Nós da Signadot estamos construindo uma solução nativa do Kubernetes que facilita a criação desses tipos de ambientes e seu uso para visualizações, desenvolvimento e ambientes de teste no Kubernetes. Estamos entusiasmados em ajudar a tornar isso possível e reduzir a complexidade envolvida na operacionalização dos itens acima. Você pode ler mais sobre a abordagem da Signadot em nossa documentação ou falar conosco em nosso canal comunitário no Slack!
A postagem Dimensionando ambientes com OpenTelemetry e Service Mesh apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}
{kind=link}