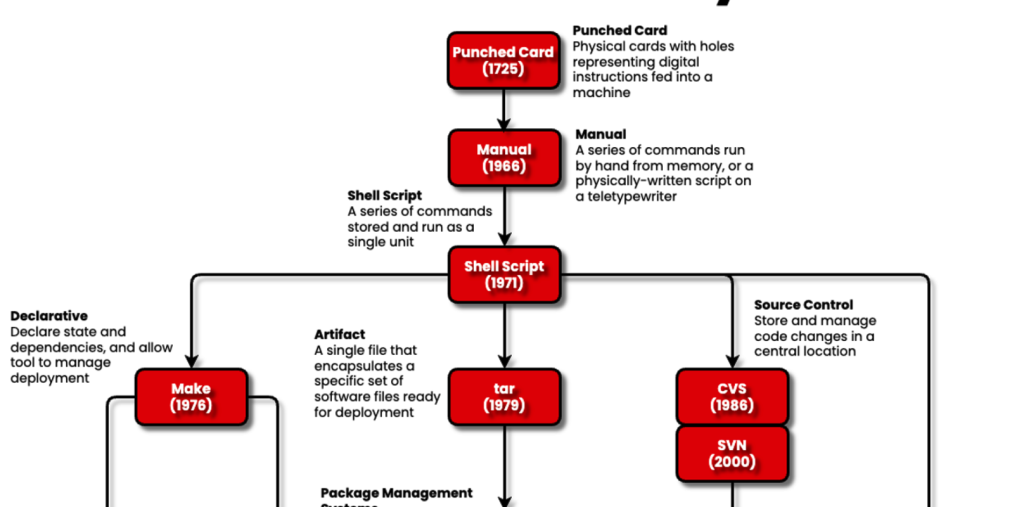
Com o 60º aniversário do BASIC e do SQL completando 50 anos, me senti inspirado a relembrar o passado do desenvolvimento de software. Então, quando vi o diagrama de Ian Miell que ele fez originalmente para uma apresentação (ele é sócio da Container Solutions), pude ver imediatamente como seria um ótimo dispositivo para guardar um pouco da história.
Nem todas as ferramentas foram colocadas no diagrama – apenas aquelas que Ian considerou terem feito um avanço considerável. Por exemplo, falta o Ansible, uma ferramenta de configuração com a qual estou bastante familiarizado. Muitos desenvolvedores em meio de carreira hoje sem dúvida verão Kubernetes como o resultado final reconhecível na árvore “nativa da nuvem”. Mas este post é mais sobre o que veio antes. Então vamos voltar.
Socando
Enquanto cartões perfurados soam verdadeiramente misteriosos, eles foram usados em nossa escola na década de 1980. Os alunos das primeiras aulas de Estudos de Computação escreviam instruções com cartões perfurados em uma linguagem chamada CESIL (Linguagem de Instrução para Educação em Computação nas Escolas). Eles foram enviados para um mainframe para serem processados, com os resultados impressos. Escusado será dizer que muito poucas crianças têm algo para administrar. E os computadores continuaram chatos.
Embora as interfaces gráficas do usuário (GUI), como o Microsoft Windows, tenham ajudado a democratizar quem poderia usar a computação entre a população em geral, foi o script de shell onde os programadores viram pela primeira vez como um processo poderia ser controlado por uma sequência de comandos, e como este era um domínio separado do próprio código do programa.
Uma das primeiras revoluções silenciosas foi parar de pensar em termos de uma sequência de comandos. O salto conceitual da codificação sequencial foi o declarativo forma – não que alguém tenha usado esse termo. Isso só foi possível quando havia memória disponível e espaço de sistema suficientes para separar o conceito do que precisava ser feito e como fazê-lo. SQL é um bom exemplo de linguagem declarativa porque declaramos o que queremos criar ou ver, mas não mencionamos exatamente como ou onde (ou mesmo por que) isso deveria acontecer. Isso deu início ao caminho dos computadores como ferramentas de computação, mas com ambas as coisas mantendo uma identidade sutilmente separada. Também foi um pouco contra a ideia do “programador” como um trabalhador que digitava linhas de código roboticamente e nos conduziu à era do “desenvolvedor”.
No início dos anos 90, quando quis construir um programa executável usando a linguagem C, precisei Fazer. Foi uma ferramenta declarativa e uma das primeiras ferramentas de automação de produção de software. Como lembramos ao olhar para Zig, C precisa reunir o código-fonte, incluir arquivos de cabeçalho, compilar a linguagem em código-objeto e, em seguida, vincular as bibliotecas necessárias em um único formato executável. Portanto, havia uma cadeia de eventos que precisavam ser realizados, e estes foram inferidos a partir das instruções e do tipo de arquivo de destino.
Olhando através do diagrama de make, um alcatrão file foi uma das primeiras tentativas organizacionais de criar conjuntos portáteis de arquivos para implantação. Eu teria visto isso primeiro em um arquivo zip, mas introduziu o mesmo conceito – foi usado para fazer um sistema de destino parecer com o sistema de desenvolvimento. Esta foi uma visão inicial do gerenciamento de configuração.
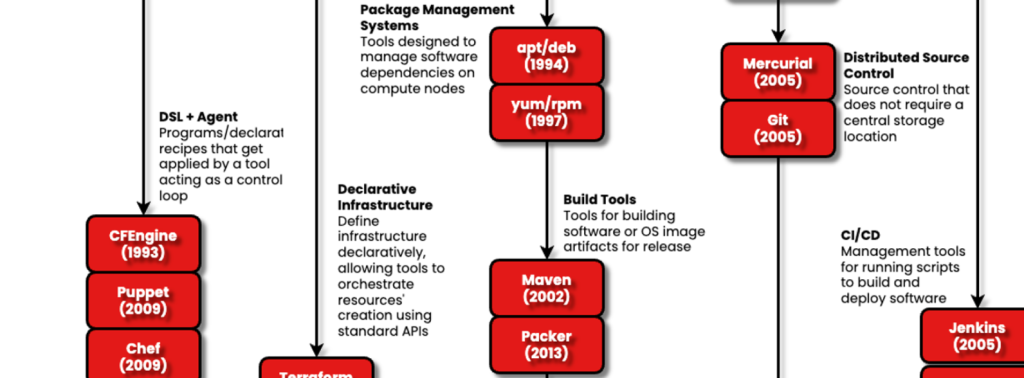
O controle de origem (ou controle de versão, à direita do tar no diagrama) levou algum tempo para se tornar relevante. Os arquivos e o armazenamento eram caros e os programas eram pequenos. Mas à medida que o tamanho e o tempo de investimento aumentavam e o conceito de colaboração se tornava comum, eram necessárias ferramentas. CVS (Concurrent Versioning System) foi o primeiro sistema cliente-servidor reconhecido que rastreou alterações em um repositório de código. Lembro-me de uma conversa com minha equipe sobre mudar de SVN para Git. O Git não foi uma venda simples, porque tinha as três etapas básicas de adicionar, confirmar e enviar código, em comparação com as duas etapas dos sistemas de controle de origem anteriores. O Git tratou sua máquina local como um repositório válido.
Eu declaro
Trabalhar com scripts — ou receitas — para qualquer um dos principais gerenciadores de configuração (Ansible, Chef ou fantoche) significava que, na década de 2000, os desenvolvedores deveriam estar totalmente cientes de um pipeline. Isso os aproximou de outras partes do processo de produção, como a Garantia de Qualidade (QA), pois tinham a oportunidade de realizar testes mais adiante.
A parte “distribuída” do Git que importava não era o fato de ele não precisar de um local de armazenamento central – a maioria das organizações ainda executava um com BitBucketGitLab ou GitHub – é que a “fonte da verdade” poderia ser distribuída razoavelmente bem às filiais. As diferenças entre o “ramo principal” e o “ramo de lançamento” atual podem ser metodicamente compreendidas. Esta foi uma técnica importante para manter a sanidade durante a colaboração. As filiais podem ser acopladas a ambientes, como preparação, teste e produção.
Java, a principal linguagem deste período, usava Maven para gerenciamento de dependências para puxar para baixo faltando artefatos. Na tentativa de resolver tudo, muitas vezes ele derrubava o que parecia ser toda a Internet para garantir que seu repositório local tivesse tudo o que precisava para construir seu projeto.
Jenkinso resultado bem-sucedido de uma bifurcação do projeto, foi a chave para o sucesso da Integração Contínua/Desenvolvimento Contínuo (CI/CD). Ele automatizou o processo de extrair código do controle de origem, construí-lo e, em seguida, entregá-lo a um ambiente, talvez para testes automatizados. Lembro-me de alguém criando semáforos físicos para mostrar se nossa construção central estava funcionando ou não. Tentar sair do trabalho na sexta-feira à noite com o semáforo vermelho era ruim e fez com que as pessoas adquirissem o hábito de não verificar as últimas alterações no final da semana.
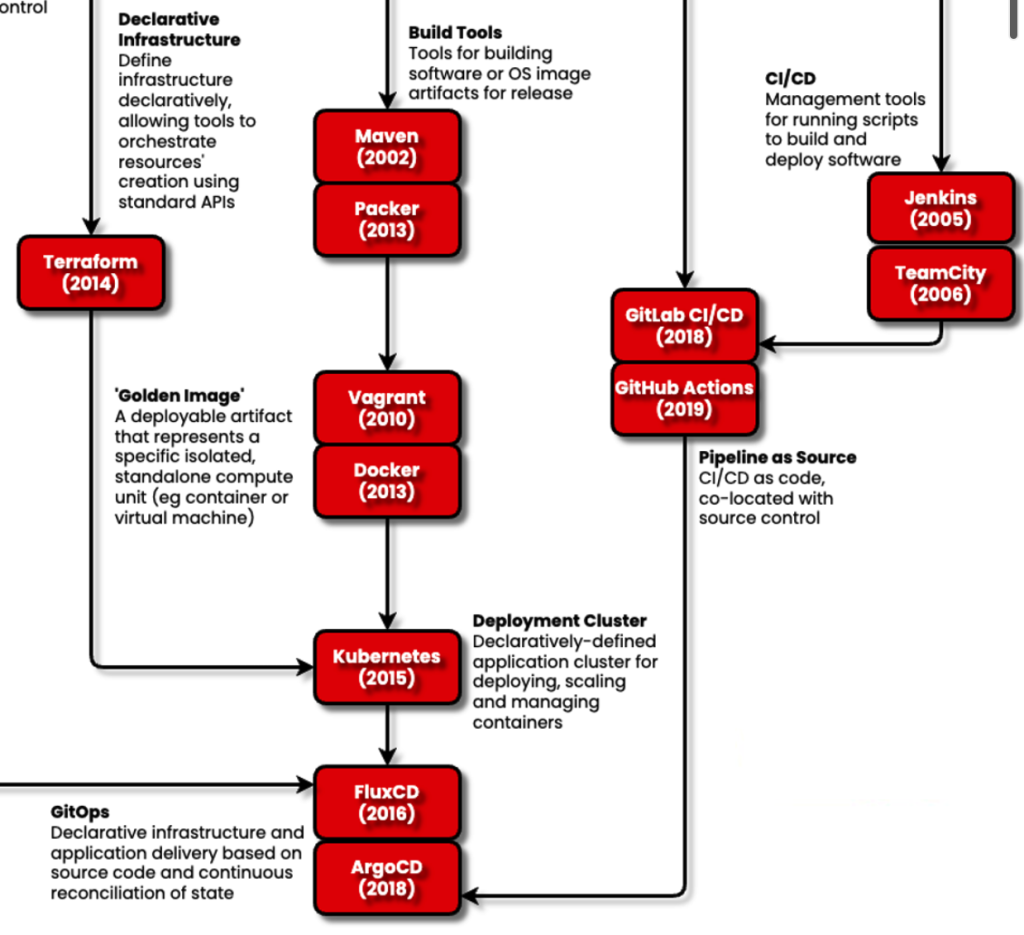
O caminho para a nuvem
Finalmente, chegamos ao início da era da nuvem. Quando você literalmente não consegue mexer na sua infraestrutura, torna-se ainda mais importante declarar antecipadamente o que você quer fazer. Estamos agora na década de 2010. Como as equipes de desenvolvedores agora geralmente recebiam laptops, havia a necessidade de capturar de alguma forma a experiência do Linux no Windows ou (se você tivesse sorte) em um Mac. Lembro-me de usar as primeiras máquinas virtuais (VMs), como o VirtualBox da Oracle. Se tentássemos usar um sistema operacional Linux com uma GUI, a VM teria que lidar com partes complicadas, como garantir que o mouse do seu laptop funcionasse corretamente, digamos, no Ubuntu.
O princípio do isolamento foi exercido em VMs e finalmente aprimorado no recipienteque não tentou abstrair uma máquina física inteira.
Docker tem sido o eixo central da adoção da nuvem, pois permite que o desenvolvedor comunique-se com o contêiner, sem se preocupar tanto com a localização do contêiner. A responsabilidade de se preocupar com a infra-estrutura global poderia então ser transferida para outro lugar. Em vez de um projeto, tínhamos agora um imagem.
Hoje estamos na parte inferior do diagrama, onde o foco mudou para gerenciamento, orquestração, escalonamento e monitoramento de contêineres.
A nuvem nos apresentou novas oportunidades e uma série de problemas diferentes. Uma empresa, a Amazon, conseguiu controlar a mentalidade do desenvolvimento em nuvem – nossos artefatos ou componentes são agora EC2 e S3. Os desenvolvedores foram apresentados aos caprichos da Internet, desde a capacidade máxima até a geografia e a legalidade do armazenamento de dados.
Neste momento, aguardamos novas repercussões da IA Generativa. Pode-se argumentar que o conceito de “nativo da nuvem” não é mais tão prevalente, já que o GitOps carro-chefe Weaveworks não está mais ativo.
Mas o diagrama não é necessariamente sobre nuvem, ou programação declarativa, ou mesmo sobre DevOps. Trabalhei com a maioria das ferramentas mencionadas aqui sem pensar nesses termos. É claro que se trata de uma jornada sinuosa, à medida que passamos mais tempo tentando descobrir como gastar o mínimo de tempo possível lidando com os resultados das mudanças.
A história aqui também trata do valor da colaboração, bem como da busca contínua pela Fonte da Verdade. E ainda assim o futuro ainda consistirá em um desenvolvedor dizendo as palavras “mas funciona na minha máquina” por algum tempo.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
David é desenvolvedor de software profissional baseado em Londres na Oracle Corp. e na British Telecom, e consultor ajudando equipes a trabalhar de maneira mais ágil. Ele escreveu um livro sobre UI design e tem escrito artigos técnicos desde então….
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.







{kind=link}
{kind=link}
{kind=link}