
Por que as ações HTML se tornaram repentinamente uma tendência do JavaScript
31 de maio de 2024
Copilot+ PCs: Compreendendo a evolução da pilha de PCs com IA da Microsoft
31 de maio de 2024
PITTSBURGH — Você nem sempre precisa de um cluster para analisar até mesmo um conjunto de dados muito grande. Há muitas coisas que você pode compactar em um único servidor executando o sistema de banco de dados analítico em processo DuckDB de código aberto.
Esta foi uma conclusão de uma série de apresentações comparando o desempenho de soluções analíticas que foram feitas na PyCon, uma conferência de programadores Python realizada na semana passada em Pittsburgh. Lá, eles compararam sistemas e perguntaram, por exemplo, se um sistema Dask era mais rápido em análises do que o Apache Spark.
Mas se você evitar totalmente a configuração de um sistema distribuído, poderá evitar muitas dores de cabeça com a manutenção.
Conforme explicado em uma apresentação feita por Kevin Kho e Han Wang, você pode obter muita quilometragem com uma única máquina, se ela for otimizada corretamente. E esta é a missão do DuckDB.
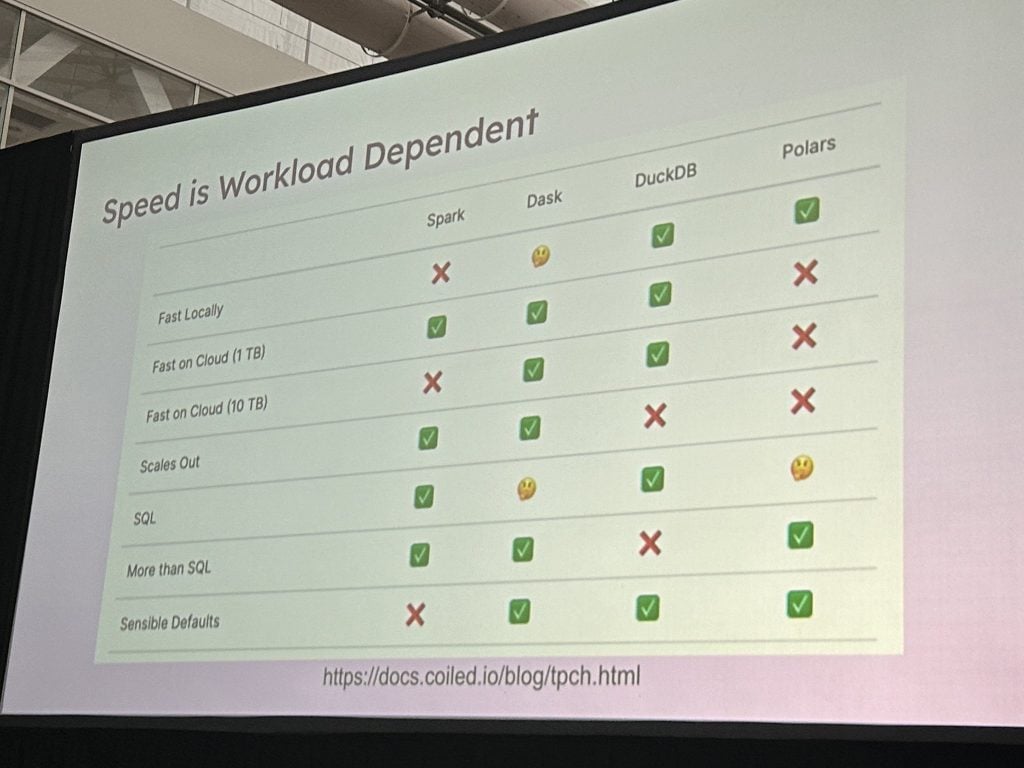
Em 2021, H20.ai testou o DuckDB em um conjunto de benchmarks comparando a velocidade de processamento de várias ferramentas semelhantes a bancos de dados populares na ciência de dados de código aberto.
Os testadores executaram cinco consultas em 10 milhões de linhas e nove colunas (cerca de 0,5 GB). Duck completou a tarefa em apenas dois segundos. Isso foi surpreendente para um banco de dados executado em um único computador. Ainda mais surpreendente, ele percorreu 100 milhões de linhas (5 GB) em 14 segundos.
Esses números foram impressionantes e, em 2023, o pessoal do DuckDB voltou e ajustou as configurações e atualizou o hardware e reduziu a carga de trabalho de 5 GB para dois segundos e 0,5 GB em menos de um segundo.
Ele ainda abordou a carga de trabalho de 50 GB – normalmente reservada para sistemas distribuídos como o Spark – em 24 segundos.
“Este é um número alucinante. As melhorias são incríveis”, disse Wang, líder de tecnologia da Lyft Machine Learning Platform, na apresentação.
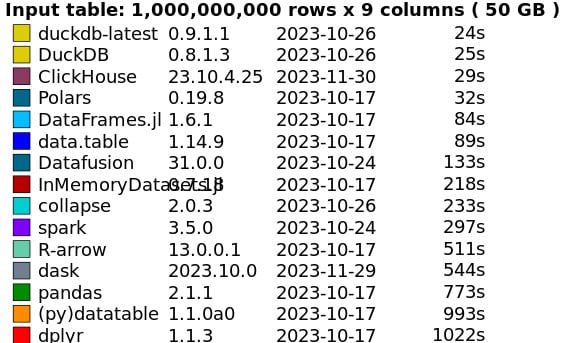
Benchmark de sistemas de Big Data do DuckDB, 2003.
A conclusão? Um número surpreendente de projetos autodenominados de “big data” não precisa do Spark ou de alguma outra solução distribuída: eles podem caber perfeitamente em um único servidor, observou Wang. Essa abordagem elimina a sobrecarga considerável de gerenciamento de um sistema distribuído e mantém todos os dados e códigos na máquina local.
Apresentando DuckDB
Muita coisa está acontecendo com o DuckDB, um sistema de banco de dados SQL analítico e relacional em processo criado em 2018. Duas coisas que o diferenciam imediatamente das outras plataformas de dados.
1: Ele combina SQL com Python, fornecendo aos desenvolvedores/analistas uma linguagem de consulta expressiva que é executada em dados no próprio processo de aplicação.
2: Destina-se a ser executado apenas em uma única máquina. Este é um recurso, não um bug, pois elimina toda a complexidade de executar uma plataforma de dados em uma plataforma distribuída.
“Assim que um problema se torna grande demais para o Pandas, você tem que lançar um sistema distribuído gigante nele. É como quebrar uma noz com uma marreta. Não é ergonômico”, disse Alex Monahan, em outra apresentação da Pycon. Monham é engenheiro de software de implantação avançada da MotherDuck, que oferece um serviço de análise sem servidor baseado no Duck.
Os dois criadores do DuckDB – Hannes Mühleisen (CEO) e Mark Raasveldt (CTO) – fundaram o DuckDB Labs, que fornece suporte comercial para o sistema de banco de dados, que foi projetado para oferecer uma análise de dados de médio porte rápida e fácil de implantar. .
Eles se inspiraram consideravelmente no pequeno banco de dados que podiam, considerando o DuckDB como o SQLite de colunas, em vez de linhas.
Com uma interface no estilo Python, o Duck também foi construído especificamente para a comunidade de ciência de dados. Os dados serão analisados, modelados e visualizados. Os cientistas de dados tendem a não usar bancos de dados, confiando em arquivos CSV e outras fontes de dados não ou semiestruturadas. Duck permite que eles incorporem operações de dados diretamente em seu próprio código.
O software de código aberto licenciado pelo MIT é escrito em C++, por isso é rápido.
DuckDB foi feito para ser rápido, aproveitando todos os núcleos do servidor e hierarquias de cache. E enquanto o SQLite é um mecanismo de banco de dados baseado em linhas que processa uma linha por vez, o Duck pode processar um vetor inteiro, de 2.048 linhas, de uma só vez.
É uma instalação binária única do instalador Python. Está disponível para múltiplas plataformas, todas pré-compiladas para que possam ser baixadas e executadas por meio de uma linha de comando ou por meio de bibliotecas clientes. Existe até uma versão que roda em um navegador via WebAssembly.
É um aplicativo em processo e grava em disco, o que significa que não é limitado pela RAM do servidor, ele pode usar todo o disco rígido, abrindo caminho para trabalhar com tamanhos de dados de terabytes. Ao contrário de um banco de dados cliente-servidor, ele não depende de um mecanismo de transporte de terceiros para enviar os dados do servidor para o cliente. Em vez disso, assim como o SQLite, o aplicativo pode extrair os dados como parte de uma chamada Python, em uma comunicação durante o processo dentro do mesmo espaço de memória.
“Você leu exatamente onde está”, disse Monahan.
Você pode gravar quadros de dados nativamente no banco de dados de várias maneiras diferentes, incluindo funções definidas pelo usuário, uma API relacional completa, a biblioteca Ibis para gravar quadros de dados simultaneamente em várias fontes de dados de back-end e PySpark, mas com uma importação diferente declaração.
Como DuckDB e Python funcionam juntos
Além da linha de comando, vem com clientes para 15 idiomas. Python é o mais popular, mas também existe Node, JBDC e OBDC. Ele pode ler arquivos CSV, JSON, arquivos Apache Iceberg. DuckDB pode ler arquivos Pandas, Polaris e Arrow nativamente, sem copiar os dados para outro formato. Ao contrário da maioria dos sistemas de banco de dados somente SQL, ele mantém o original dos dados à medida que são ingeridos.
“Portanto, isso poderia caber em muitos fluxos de trabalho”, disse Monahan.
Ele também pode ler arquivos pela Internet, incluindo aqueles do GitHub (via FTP), Amazon S3, armazenamento de Blobs do Azure e Google Cloud Storage. Ele pode gerar tensores TensorFlow e Pytorch.
DuckDB usa uma variante SQL que é muito parecida com Python, que pode ingerir frames de dados nativamente.
Monahan produziu um exemplo de aplicativo “Hello World” para ilustrar:
produzirá a saída:
((42,))
O banco de dados utiliza PostgreSQL como base, embora algumas modificações tenham sido feitas no SQL, tanto para simplificar a linguagem quanto para ampliar suas capacidades.

As maneiras como o DuckDB estende e simplifica o SQL (apresentação de Alex Monahan na Pycon)
O Big Data está morto?
Em resumo, DuckDB é um banco de dados rápido com uma intenção revolucionária: tornar possível a análise de um único computador, mesmo para conjuntos de dados muito grandes. Questiona a necessidade de soluções baseadas em Big Data.
Em uma postagem do blog MotherDuck de 2023 amplamente divulgada, provocativamente intitulada “Big Data Is Dead”, Jordan Tigani observou que “a maioria dos aplicativos não precisa processar grandes quantidades de dados”.
“A quantidade de dados processados para cargas de trabalho analíticas é quase certamente menor do que você pensa”, escreveu ele. Portanto, faz sentido olhar para um software de análise simples e baseado em computador antes de saltar para um data warehouse ou sistema de análise distribuído mais caro.
A postagem DuckDB: análise Python em processo para dados não muito grandes apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}
{kind=link}