Exclusivo: Microsoft e Google unem forças no OneTable, uma solução de código aberto para desafios de data lake
13 de janeiro de 2024
Ex-CEO da Angi revela chaveiro para revolucionar a fabricação de CPG
13 de janeiro de 2024
O ajuste fino de modelos de linguagem grande (LLM) tornou-se uma ferramenta importante para empresas que buscam adaptar os recursos de IA a tarefas de nicho e experiências de usuário personalizadas. Mas o ajuste fino geralmente acarreta grandes despesas computacionais e financeiras, mantendo seu uso limitado para empresas com recursos limitados.
Para resolver esses desafios, os pesquisadores criaram algoritmos e técnicas que reduzem o custo do ajuste fino de LLMs e da execução de modelos ajustados. A mais recente dessas técnicas é o S-LoRA, um esforço colaborativo entre pesquisadores da Universidade de Stanford e da Universidade da Califórnia-Berkeley (UC Berkeley).
S-LoRA reduz drasticamente os custos associados à implantação de LLMs ajustados, o que permite às empresas executar centenas ou até milhares de modelos em uma única unidade de processamento gráfico (GPU). Isso pode ajudar a desbloquear muitos novos aplicativos LLM que anteriormente seriam muito caros ou exigiriam grandes investimentos em recursos computacionais.
Adaptação de baixo escalão
A abordagem clássica para o ajuste fino de LLMs envolve o retreinamento de um modelo pré-treinado com novos exemplos adaptados a uma tarefa downstream específica e o ajuste de todos os parâmetros do modelo. Dado que os LLMs normalmente possuem bilhões de parâmetros, este método exige recursos computacionais substanciais.
As técnicas de ajuste fino com eficiência de parâmetros (PEFT) contornam esses custos, evitando o ajuste de todos os pesos durante o ajuste fino. Um método PEFT notável é a adaptação de baixa classificação (LoRA), uma técnica desenvolvida pela Microsoft, que identifica um subconjunto mínimo de parâmetros dentro do LLM fundamental que são adequados para o ajuste fino para a nova tarefa.
Notavelmente, o LoRA pode reduzir o número de parâmetros treináveis em várias ordens de magnitude, ao mesmo tempo que mantém níveis de precisão equivalentes aos alcançados por meio do ajuste fino de todos os parâmetros. Isso reduz consideravelmente a memória e a computação necessárias para personalizar o modelo.
A eficiência e eficácia do LoRA levaram à sua ampla adoção na comunidade de IA. Numerosos adaptadores LoRA foram criados para LLMs pré-treinados e modelos de difusão.
Você pode mesclar os pesos LoRA com o LLM base após o ajuste fino. No entanto, uma prática alternativa envolve manter os pesos LoRA como componentes separados que são inseridos no modelo principal durante a inferência. Essa abordagem modular permite que as empresas mantenham vários adaptadores LoRA, cada um representando uma variante de modelo ajustada, enquanto ocupam coletivamente apenas uma fração do consumo de memória do modelo principal.
As aplicações potenciais deste método são vastas, desde a criação de conteúdo até ao atendimento ao cliente, tornando possível às empresas fornecer serviços personalizados orientados por LLM sem incorrer em custos proibitivos. Por exemplo, uma plataforma de blog poderia aproveitar essa técnica para oferecer LLMs aprimorados que podem criar conteúdo com o estilo de escrita de cada autor com um custo mínimo.
O que S-LoRA oferece
Embora a implantação de vários modelos LoRA em um único LLM de parâmetros completos seja um conceito atraente, ela apresenta vários desafios técnicos na prática. A principal preocupação é o gerenciamento de memória; As GPUs têm memória finita e apenas um número selecionado de adaptadores pode ser carregado junto com o modelo básico a qualquer momento. Isso requer um sistema de gerenciamento de memória altamente eficiente para garantir uma operação suave.
Outro obstáculo é o processo em lote usado pelos servidores LLM para melhorar o rendimento ao lidar com várias solicitações simultaneamente. Os tamanhos variados dos adaptadores LoRA e sua computação separada do modelo básico introduzem complexidade, potencialmente levando a gargalos de memória e computacionais que impedem a velocidade de inferência.
Além disso, as complexidades se multiplicam com LLMs maiores que exigem processamento paralelo multi-GPU. A integração de pesos e cálculos adicionais dos adaptadores LoRA complica a estrutura de processamento paralelo, exigindo soluções inovadoras para manter a eficiência.
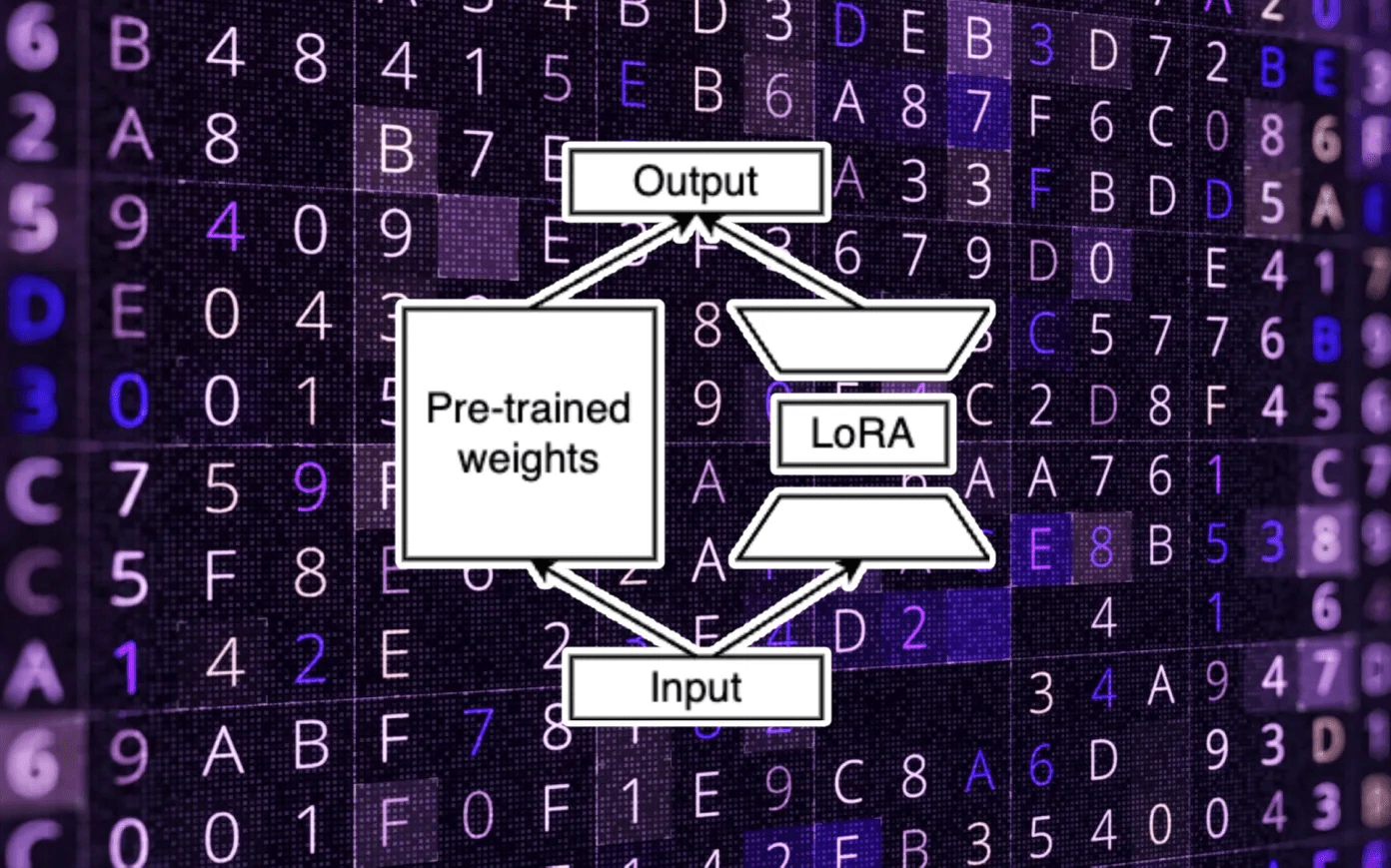
S-LoRA usa gerenciamento dinâmico de memória para trocar adaptadores LoRA entre memória principal e GPU
A nova técnica S-LoRA resolve esses desafios através de uma estrutura projetada para atender a vários modelos LoRA. S-LoRA possui um sistema de gerenciamento de memória dinâmico que carrega pesos LoRA na memória principal e os transfere automaticamente entre GPU e memória RAM à medida que recebe e agrupa solicitações.
O sistema também introduz um mecanismo de “Paginação Unificada” que lida perfeitamente com caches de modelos de consulta e pesos de adaptadores. Essa inovação permite que o servidor processe centenas ou até milhares de consultas em lote sem causar problemas de fragmentação de memória que podem aumentar o tempo de resposta.
S-LoRA incorpora um sistema de “paralelismo de tensor” de última geração, feito sob medida para manter os adaptadores LoRA compatíveis com grandes modelos de transformadores que rodam em múltiplas GPUs.
Juntos, esses avanços permitem que o S-LoRA atenda a muitos adaptadores LoRA em uma única GPU ou em várias GPUs.
Servindo milhares de LLMs
Os pesquisadores avaliaram o S-LoRA servindo diversas variantes do modelo Llama de código aberto da Meta em diferentes configurações de GPU. Os resultados mostraram que o S-LoRA poderia manter o rendimento e a eficiência da memória em escala.
Comparando com a biblioteca líder de ajuste fino com eficiência de parâmetros, Hugging Face PEFT, S-LoRA apresentou um notável aumento de desempenho, melhorando o rendimento em até 30 vezes. Comparado ao vLLM, um sistema de serviço de alto rendimento com suporte básico LoRA, o S-LoRA não apenas quadruplicou o rendimento, mas também expandiu o número de adaptadores que poderiam ser servidos em paralelo em várias ordens de magnitude.
Uma das conquistas mais notáveis do S-LoRA é sua capacidade de atender simultaneamente 2.000 adaptadores, ao mesmo tempo em que incorre em um aumento insignificante na sobrecarga computacional para processamento LoRA adicional.
“O S-LoRA é motivado principalmente por LLMs personalizados”, disse Ying Sheng, estudante de doutorado em Stanford e coautor do artigo, ao VentureBeat. “Um provedor de serviços pode querer atender usuários com o mesmo modelo básico, mas com adaptadores diferentes para cada um. Os adaptadores poderiam ser ajustados com os dados históricos dos usuários, por exemplo.”
A versatilidade do S-LoRA se estende à sua compatibilidade com a aprendizagem contextual. Ele permite que um usuário receba um adaptador personalizado enquanto aprimora a resposta do LLM adicionando dados recentes como contexto.
“Isso pode ser mais eficaz e eficiente do que a solicitação pura no contexto”, acrescentou Sheng. “O LoRA tem cada vez mais adaptação nas indústrias porque é barato. Ou mesmo para um usuário, eles podem conter muitas variantes, mas com o custo de manter apenas um modelo.”
O código S-LoRA agora está acessível no GitHub. Os pesquisadores planejam integrá-lo a estruturas populares de serviço LLM para permitir que as empresas incorporem prontamente o S-LoRA em suas aplicações.
A missão da VentureBeat é ser uma praça digital para os tomadores de decisões técnicas obterem conhecimento sobre tecnologia empresarial transformadora e realizarem transações. Conheça nossos Briefings.



{kind=link}
{kind=link}
{kind=link}