Analisei a geração de persistência regex e JSON com LLMs, mas é a Linguagem de Consulta Estruturada (SQL) que muitos acreditam ser bem tratada pela IA. Para ajudar a comemorar o 50º aniversário do SQL, vamos falar sobre tabelas, apresentando a terminologia técnica conforme necessário. No entanto, não quero simplesmente testar consultas em tabelas existentes. O mundo de bancos de dados relacionais começa com o esquema.
Um esquema descreve um grupo de tabelas que interagem para permitir que consultas SQL respondam a perguntas sobre modelos de sistemas do mundo real. Usamos vários restrições para controlar como as tabelas se relacionam entre si. Neste exemplo, desenvolverei um esquema sobre livros, autores e editoras. Depois veremos se um LLM consegue reproduzir o trabalho.
Começamos com o relações entre nossas coisas. Um livro é escrito por um autor e publicado por uma editora. Na verdade, a publicação de um livro define a relação entre autor e editor.
Então, em termos concretos, queremos produzir um resultado como este:
Isso é agradável de ler (voltaremos a isso mais tarde), mas a tabela em si seria uma maneira ruim de manter mais informações.
Se o nome do editor for apenas uma string, pode ser necessário digitá-lo várias vezes, o que é ineficiente e propenso a erros. O mesmo para o autor. Aqueles com inclinação literária saberão que o autor (Iain Banks) é o mesmo para ambos os livros, mas ele usou um pseudônimo ligeiramente alterado ao escrever ficção científica.
E se o livro fosse lançado novamente mais tarde por uma editora diferente? Para ter certeza de distinguir entre os dois eventos de publicação, precisaríamos dos títulos dos livros e da data de lançamento – portanto, nosso chave primária ou identificação única deve incluir ambos. Queremos que o sistema rejeite qualquer tentativa de inscrição de dois livros com o mesmo título e data de publicação.
Em vez de usar uma tabela grande, vamos usar três tabelas e referências a elas quando necessário. Um para autores, um para editoras e outro para livros. Escrevemos os detalhes do autor na tabela Autores e depois os referenciamos na tabela Livros usando um chave estrangeira.
Então aqui estão as tabelas de esquema escritas em linguagem de definição de dados (DDL). Estou usando a variante MySQL – irritantemente, todos os fornecedores ainda mantêm dialetos ligeiramente diferentes.
Primeiro, a tabela de autores. Adicionamos um índice de coluna de ID automático como chave primária. Na verdade, não resolvemos o problema do pseudônimo (deixarei isso para os leitores):
CRIARMESAAutores (
EU IAinternoNÃONULOINCREMENTO AUTOMÁTICO,
O meu nomevarchar(255)nãonulo,
Aniversáriodatanãonulo,
PRIMÁRIOCHAVE(EU IA)
);
A tabela de editores segue o mesmo padrão. O “NOT NULL” é outra restrição para evitar que dados sejam adicionados sem conteúdo.
CRIARMESAEditores (
EU IAinternoNÃONULOINCREMENTO AUTOMÁTICO,
O meu nomevarchar(255)nãonulo,
Endereçovarchar(255)nãonulo,
PRIMÁRIOCHAVE(EU IA)
);
A tabela Books fará referência às chaves estrangeiras, o que a deixa lógica, mas um pouco ilegível. Observe que respeitamos que o título do livro juntamente com a data de publicação constituem a chave primária.
CRIARMESALivros (
O meu nomevarchar(255)NÃONULO,
ID do autorinterno,ID do editorinterno,
Data de publicaçãodataNÃONULO,
PRIMÁRIOCHAVE(O meu nome,Data de publicação),
ESTRANGEIROCHAVE(ID do autor)REFERÊNCIASAutores(EU IA),
ESTRANGEIROCHAVE(ID do editor)REFERÊNCIASEditores(EU IA)
);
Para ver uma mesa organizada como a que está no topo, precisamos de um visualizar. Esta é apenas uma forma de unir tabelas para que possamos selecionar as informações que precisamos exibir, deixando o esquema intacto. Agora que temos o esquema escrito, podemos construir nossa visão:
CRIARVISUALIZARLivros visíveisCOMO
SELECIONARLivros.O meu nome‘livro’,Autores.O meu nome‘Autor’,Editores.O meu nome‘editor’,Livros.Data de publicação‘Data’
DELivros,Editores,Autores
ONDELivros.ID do autor=Autores.EU IA
ELivros.ID do editor=Editores.EU IA;
Vamos ver se conseguimos produzir nosso esquema em um playground on-line para não precisarmos instalar um banco de dados. DB Fiddle deve fazer o trabalho.
Se você inserir o DDL e depois adicionar os dados reais:
INSERIREMAutores (O meu nome,Aniversário)
VALORES(‘Bancos Iain’,’16/02/1954′);
INSERIREMAutores (O meu nome,Aniversário)
VALORES(‘Iain M Bancos’,’16/02/1954′);
INSERIREMEditores (O meu nome,Endereço)
VALORES(‘Ábaco’,‘Londres’);
INSERIREMEditores (O meu nome,Endereço)
VALORES(‘Órbita’,‘Nova Iorque’);
Os resultados da visualização são mostrados abaixo como ‘Consulta 3’ no DB Fiddle, e são os dados que queríamos ver o tempo todo:
Um LLM também pode criar esquemas?
OK, agora queremos perguntar a um LLM sobre a criação de esquemas. Para resumir como queremos orientar o LLM:
Quando solicitado em inglês por um esquema, queremos que ele gere o DDL para três tabelas, com índices e restrições.
Também podemos sugerir a necessidade de restrições (chaves primárias, chaves estrangeiras, etc.), se necessário.
Podemos pedir uma vista.
Podemos ajustá-lo à sintaxe do MySQL, se necessário.
Usarei o Llama 3, mas também dei uma olhada nos LLMs da OpenAI e obtive praticamente os mesmos resultados.
Nossa primeira consulta: “Crie um esquema de banco de dados relacional para descrever livros, editoras e autores”.
E os resultados:
Até agora tudo bem. Não criou o DDL, mas podemos perguntar isso separadamente. De certa forma, ele se saiu melhor ao descrever o esquema em inglês. Vejamos o resto da resposta:
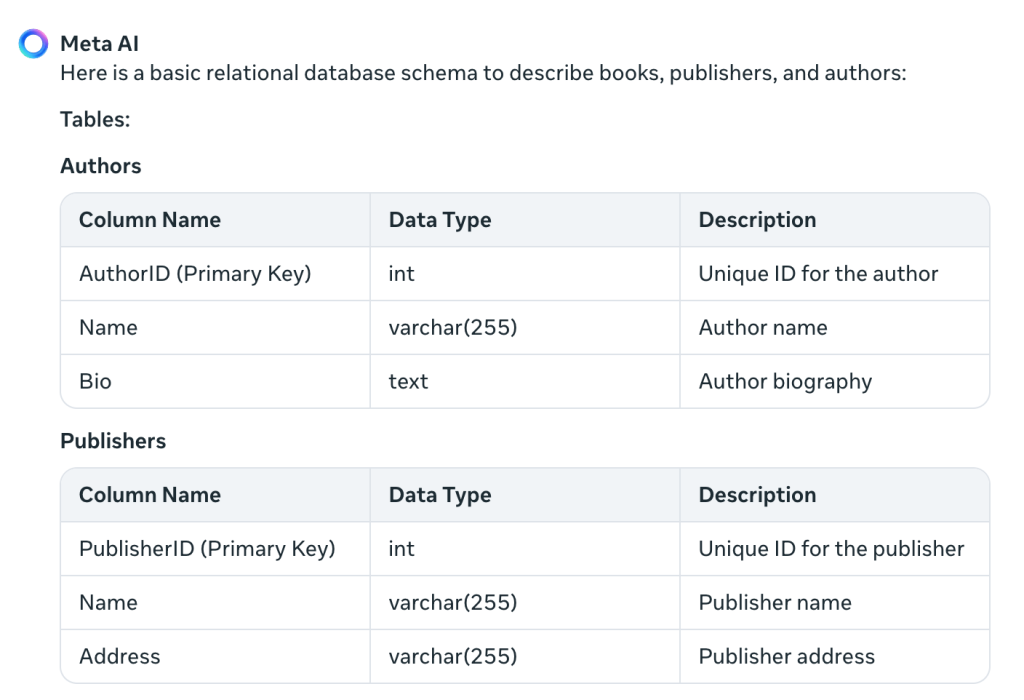
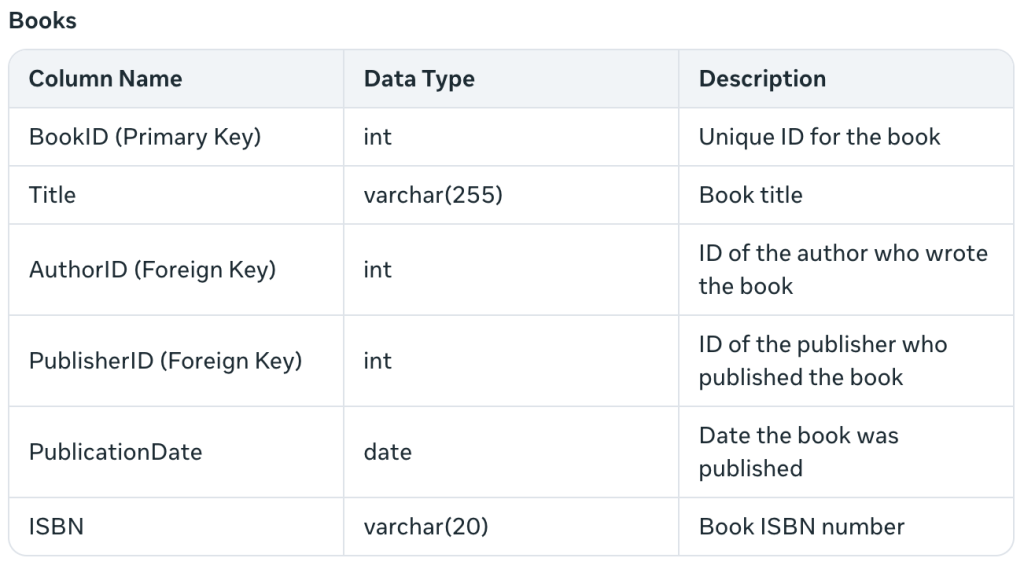
Descreveu restrições de chave estrangeira e adicionou o ISBN, no qual não pensei. Além disso, “PublicationDate” é melhor em inglês do que meu “PublishedDate”. E fez mais uma mesa:
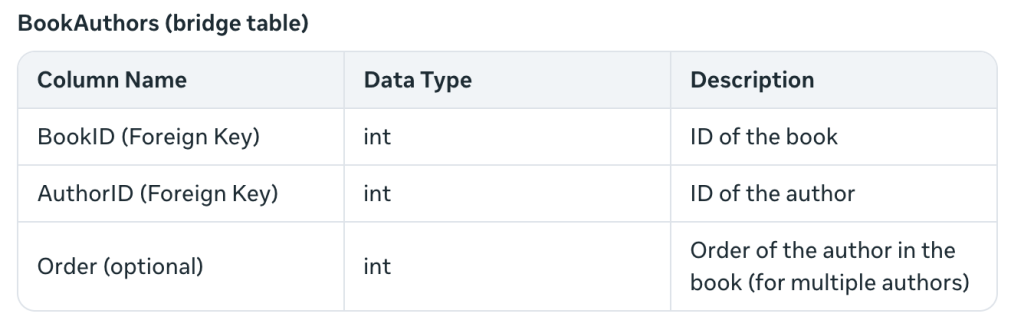
Isso resolve o problema de vários autores em um livro – não é um problema no qual eu estava pensando. O termo mesa de ponte indica a união das duas tabelas (livros e autores) via chaves estrangeiras.
Vamos solicitar o DDL: “Mostre-me a linguagem de definição de dados para este esquema.”
Eles retornaram corretamente, incluindo NOT NULLs para garantir que não haja entradas vazias. Ele também observou que o DDL era, de certa forma, “genérico” devido às diferenças entre os SQLs dos fornecedores no mundo real.
Por fim, vamos pedir uma vista:
Esta é uma versão muito mais complicada que a minha; no entanto, quando adaptado para a nomenclatura do meu esquema, funciona perfeitamente no DB Fiddle. A mesa apelido a nomenclatura vista aqui realmente não ajuda na compreensão.
Conclusão: LLMs podem realmente fazer esquemas
Eu diria que isso foi uma grande vitória para os LLMs, pois eles transformaram minha descrição em inglês em um esquema bem restrito e, em seguida, em DDL executável, ao mesmo tempo em que forneceram explicações (embora elas tenham entrado em detalhes mais técnicos de relacionamento). Eu nem usei um LLM ou serviço especializado, então funcionou bem.
Até certo ponto, este é um mapeamento de um domínio (o mundo editorial) para outro (a linguagem SQL específica do domínio), e isso funciona fortemente para os pontos fortes de um LLM. Cada domínio é bem definido e profundo em detalhes.
Então, feliz aniversário, SQL, e espero que os LLMs mantenham você relevante por mais algumas décadas!
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
David é desenvolvedor de software profissional baseado em Londres na Oracle Corp. e British Telecom, além de um consultor que auxilia as equipes a trabalhar de forma mais ágil. Ele escreveu um livro sobre UI design e tem escrito artigos técnicos desde então….
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.








{kind=link}
{kind=link}
{kind=link}