Às vezes, os desenvolvedores precisam fazer uma escolha quando se trata de abordagens de recuperação de LLM. Eles podem usar uma incorporação esparsa tradicional ou uma incorporação densa. Embeddings esparsos funcionam muito bem para processos de correspondência de palavras-chave. Normalmente encontramos embeddings esparsos no processamento de linguagem natural (PNL), e esses embeddings de alta dimensão geralmente contêm valores zero. As dimensões nessas incorporações representam tokens em um (ou vários) idiomas. Ele usa valores diferentes de zero para mostrar a relevância de cada token para um documento específico.
Os embeddings densos, por outro lado, têm dimensões inferiores, mas não contêm nenhum valor zero. Como o nome sugere, os embeddings densos estão repletos de informações. Isso torna os embeddings densos ideais para tarefas de pesquisa semântica, tornando mais fácil combinar o “espírito” do significado em vez da string exata.
BGE-M3 é um modelo de aprendizado de máquina usado para criar um tipo avançado de incorporação denominado “incorporação esparsa aprendida”. O bom desses embeddings aprendidos é que eles combinam o melhor dos dois mundos: a precisão dos embeddings esparsos e a riqueza semântica dos embeddings densos. Este modelo utiliza os tokens numa incorporação esparsa para saber quais outros tokens podem ser relevantes ou relacionados, mesmo que não sejam explicitamente utilizados na cadeia de pesquisa original. Em última análise, isso produz uma incorporação rica em informações relevantes.
Conheça o BERT
Representações de codificadores bidirecionais de transformadores (ou BERT) são mais do que aparenta. É a arquitetura subjacente que permite modelos avançados de aprendizado de máquina como BGE-M3 e SPLADE.
O BERT aborda o texto de maneira diferente dos modelos tradicionais. Em vez de apenas ler uma sequência de texto sequencialmente, ele examina tudo de uma vez, levando em consideração o relacionamento entre todos os componentes. O BERT faz isso com uma abordagem dupla. Estas são tarefas de pré-treinamento separadas que o modelo implementa, mas seus resultados trabalham juntos para enriquecer o significado das entradas.
Modelagem de linguagem mascarada (MLM): primeiro, o BERT oculta aleatoriamente parte do token de entrada. Em seguida, ele usa o modelo para descobrir quais opções fazem sentido para as partes ocultas. Para fazer isso, precisa compreender a relação não apenas entre a ordem das palavras, mas como essa ordem afeta o significado.
Previsão da próxima frase (NSP): embora o MLM funcione principalmente no nível da frase, o NSP diminui ainda mais o zoom. Esta tarefa garante que as frases e parágrafos fluam logicamente, para que aprenda a prever o que faz sentido nestes contextos mais amplos.
Quando o modelo BERT analisa uma consulta, cada camada do codificador conduz sua análise independentemente das demais camadas. Isso permite que cada camada gere resultados únicos, livres da influência dos outros codificadores. O resultado disso é um conjunto de dados mais rico e robusto.
É importante entender as funções do BERT porque o BGE-M3 é baseado no BERT. O exemplo a seguir demonstra como funciona o BERT.
BERT em ação
Vamos fazer uma consulta básica e ver como o BERT cria uma incorporação a partir dela:
Milvus é um banco de dados vetorial construído para pesquisa escalonável de similaridade.
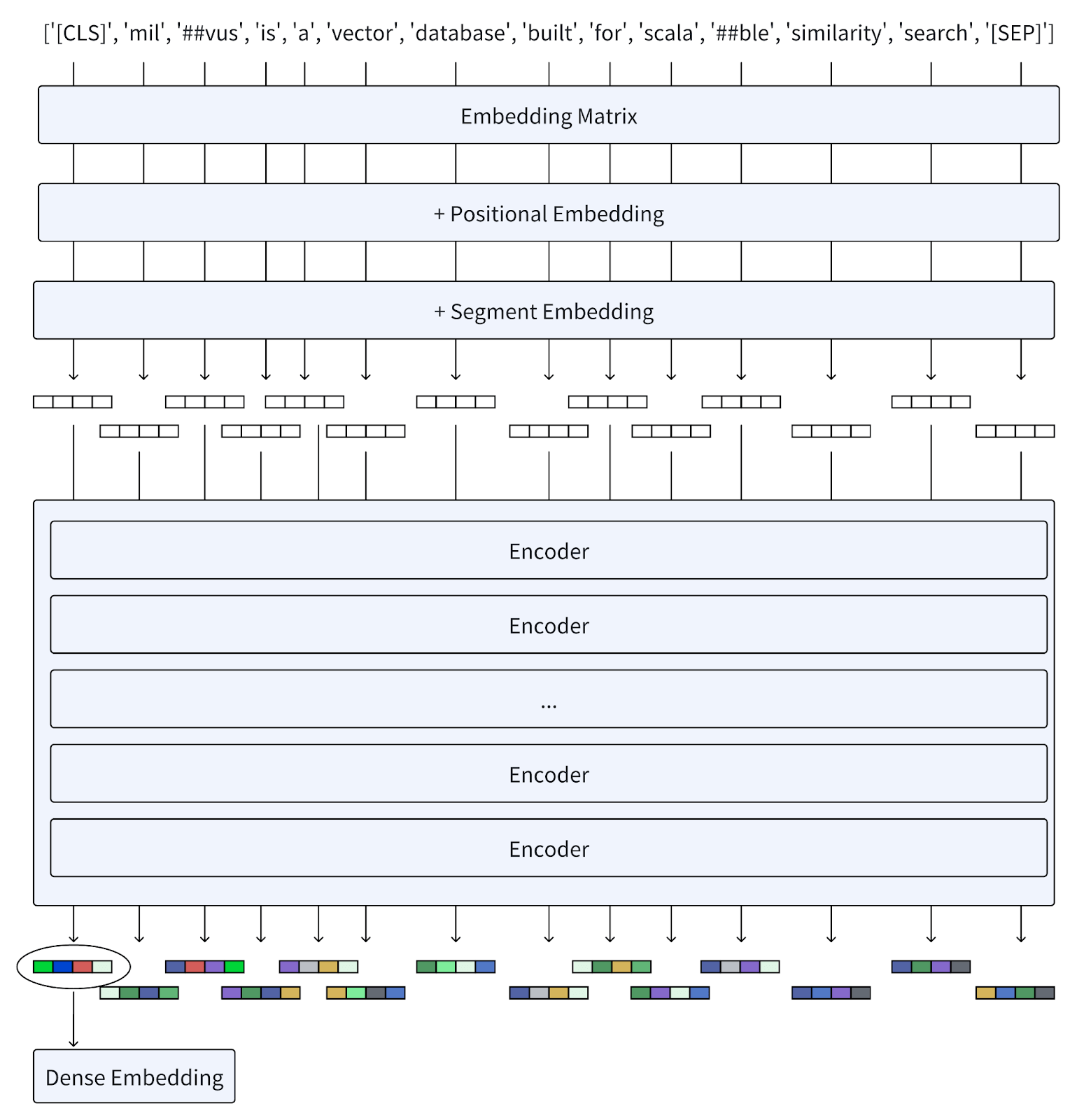
A primeira etapa é converter as palavras da string de consulta em tokens.
Você notará que o modelo adicionou (CLS) ao início e (SEP) ao final do token. Esses componentes simplesmente indicam o início e o fim de uma frase, respectivamente, no nível da frase.
Em seguida, é necessário converter os tokens em uma incorporação.
A primeira parte deste processo é a incorporação. Aqui, uma matriz de incorporação converte cada token em um vetor. Em seguida, o BERT adiciona incorporações posicionais porque a ordem das palavras é importante e essa incorporação mantém essas posições relativas intactas. Finalmente, a incorporação de segmentos simplesmente rastreia as quebras entre as frases.
Podemos ver que a saída de incorporação neste ponto é monocromática para representar incorporações esparsas. Para obter maior densidade, esses embeddings passam por vários codificadores. Assim como as tarefas de pré-treinamento identificadas acima, que funcionam independentemente umas das outras, esses codificadores fazem o mesmo. Os embeddings passam por revisão contínua à medida que funcionam através dos codificadores. Os tokens na sequência fornecem um contexto crítico para refinar a representação gerada por cada codificador.
Assim que esse processo terminar, a saída final será uma incorporação mais densa do que a saída do pré-codificador. Isto é especialmente verdadeiro ao usar tokens individuais para processamento adicional ou tarefas que resultam em uma representação singular e densa.
BGE-M3 entra no bate-papo
O BERT nos proporcionou embeddings densos, mas o objetivo aqui é gerar embeddings esparsos aprendidos. Agora finalmente chegamos ao modelo BGE-M3.
BGE-M3 é basicamente um modelo avançado de aprendizado de máquina que leva o BERT ainda mais, concentrando-se no aprimoramento da representação de texto por meio de multifuncionalidade, multilinguística e multigranularidade. Tudo isso quer dizer que ele faz mais do que criar embeddings densos, gerando embeddings esparsos aprendidos que fornecem o melhor dos dois mundos: significado das palavras e escolhas precisas de palavras.
BGE-M3 em ação
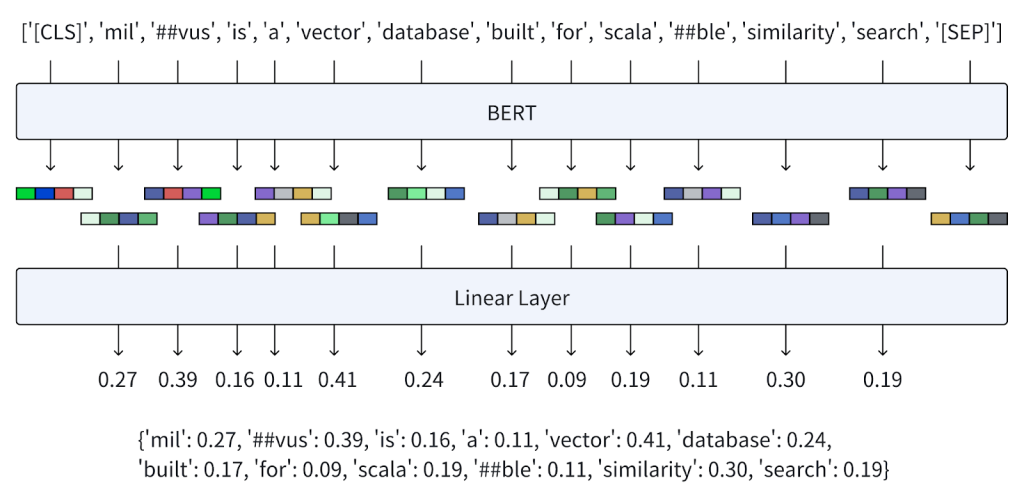
Vamos começar com a mesma consulta que usamos para entender o BERT. A execução da consulta gera a mesma sequência de embeddings contextualizados que vimos acima. Podemos chamar essa saída ( Q ).
O modelo BGE-M3 se aprofunda nessas incorporações e tenta compreender o significado de cada token em um nível mais granular. Existem vários aspectos disso.
Estimativa de importância do token: BGE-M3 não aceita a representação do token (CLS) Q(0) como a única representação possível. Também avalia a incorporação contextualizada de cada token Q(i) dentro da sequência.
Transformação linear: O modelo também pega a saída do BERT e, usando uma camada linear, cria uma ponderação de importância para cada token. Podemos chamar o conjunto de pesos que o BGE-M3 produz W_{lex}.
Função de ativação: BGE-M3 então aplica uma função de ativação de unidade linear retificada (ReLU) ao produto de W_{lex} e Q(i) para calcular o peso do termo w_{t} para cada token. O uso do ReLU garante que o termo peso não seja negativo, contribuindo para a dispersão da incorporação.
Incorporação esparsa aprendida: o resultado final da saída é uma incorporação esparsa onde cada token tem um valor ponderado que indica o quão importante ele é para a string de entrada original.
BGE-M3 no mundo real
A aplicação do modelo BGE-M3 a casos de uso do mundo real pode ajudar a demonstrar o valor deste modelo de aprendizado de máquina. Estas são áreas onde as organizações podem beneficiar da capacidade do modelo de compreender nuances linguísticas em grandes quantidades de dados textuais.
Automação de suporte ao cliente – Chatbots e assistentes virtuais
Você pode usar o BGE-M3 para potencializar chatbots e assistentes virtuais, melhorando significativamente os serviços de suporte ao cliente. Esses chatbots podem lidar com uma ampla variedade de dúvidas dos clientes, fornecendo respostas instantâneas e compreendendo questões complexas e informações contextuais. Eles também podem aprender com as interações para melhorar com o tempo.
Benefícios:
Disponibilidade 24 horas por dia, 7 dias por semana: Fornece suporte 24 horas por dia aos clientes.
Eficiência de custos: Reduz a necessidade de uma grande equipe de suporte ao cliente.
Melhor experiência do cliente: Respostas rápidas e precisas melhoram a satisfação do cliente.
Escalabilidade: pode lidar com diversas consultas simultaneamente, garantindo um serviço consistente durante horários de pico.
Geração e gerenciamento de conteúdo para marketing e mídia
Você pode aproveitar o BGE-M3 para gerar conteúdo de alta qualidade para blogs, mídias sociais, anúncios e muito mais. Ele pode criar artigos, postagens em mídias sociais e até relatórios completos com base no tom, estilo e contexto desejados. Você também pode usar este modelo para resumir documentos longos, criar resumos e gerar descrições de produtos.
Benefícios:
Eficiência: Produz grandes volumes de conteúdo rapidamente.
Consistência: mantém um tom e estilo consistentes em diferentes partes do conteúdo.
Redução de custos: Reduz a necessidade de grandes equipes de criação de conteúdo.
Criatividade: ajuda a debater e gerar ideias de conteúdo criativo.
Análise de Dados Médicos – Documentação e Análise Clínica
Os desenvolvedores do setor de saúde podem usar o BGE-M3 para analisar documentos clínicos e registros de pacientes, extrair informações relevantes e auxiliar na geração de relatórios médicos abrangentes. Também pode ajudar a identificar tendências e insights a partir de grandes quantidades de dados médicos, apoiando melhores cuidados e pesquisas com os pacientes.
Benefícios:
Economia de tempo: Reduz o tempo que os profissionais de saúde gastam com documentação.
Precisão: Melhora a precisão dos registros e relatórios médicos.
Geração de insights: identifica padrões e tendências que podem informar melhores decisões clínicas.
Conformidade: ajuda a garantir que a documentação esteja em conformidade com os padrões regulatórios.
Conclusão
O modelo BGE-M3 oferece um grau significativo de versatilidade e recursos avançados de processamento de linguagem natural que têm aplicações em todos os setores e indústrias e podem fornecer melhorias significativas na eficiência operacional e na qualidade do serviço.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Stephen Batifol é um defensor do desenvolvedor na Zilliz. Anteriormente, ele trabalhou como engenheiro de aprendizado de máquina na Wolt, onde criou e trabalhou na plataforma de ML, e anteriormente como cientista de dados na Brevo. Stephen estudou ciência da computação e…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.







{kind=link}
{kind=link}
{kind=link}