As bibliotecas de UI estão morrendo: o que vem a seguir?
27 de março de 2024
10 maneiras pelas quais a observabilidade do Kubernetes aumenta a produtividade e reduz custos
27 de março de 2024
As empresas que pretendem maximizar os seus ativos de dados estão a adotar abordagens escaláveis, flexíveis e unificadas para o armazenamento e análise de dados. Essa tendência é impulsionada por arquitetos empresariais encarregados de criar infraestruturas que se alinhem com a evolução das demandas dos negócios. Uma arquitetura moderna de data lake atende a essa necessidade integrando a escalabilidade e a flexibilidade de um data lake com a estrutura e as otimizações de desempenho de um data warehouse. Esta postagem fornece uma arquitetura de referência para compreender e implementar um data lake moderno.
O que é um data lake moderno?
Um data lake moderno é metade data warehouse e metade data lake e usa armazenamento de objetos para tudo. Isso pode parecer um truque de marketing – colocar dois produtos em um pacote e chamá-lo de novo produto – mas o data warehouse apresentado neste artigo é melhor do que um data warehouse convencional. Ele usa armazenamento de objetos, portanto, oferece todos os benefícios do armazenamento de objetos em termos de escalabilidade e desempenho. As organizações que adotam essa abordagem pagam apenas pelo que precisam (facilitado pela escalabilidade do armazenamento de objetos) e obtêm desempenho equipando seu armazenamento de objetos subjacente com unidades NVMe conectadas por uma rede de ponta.
O uso do armazenamento de objetos dessa forma é possibilitado pelo surgimento de formatos de tabela abertos (OTFs), como Apache Iceberg, Apache Hudi e Delta Lake. Essas especificações, uma vez implementadas, facilitam o uso do armazenamento de objetos como solução de armazenamento subjacente para um data warehouse. Eles também fornecem recursos que podem não existir em um data warehouse convencional, incluindo instantâneos (também conhecidos como viagem no tempo), evolução de esquema, partições, evolução de partição e ramificação de cópia zero.
Mas o data lake moderno é mais do que apenas um data warehouse sofisticado, pois também contém um data lake para dados não estruturados. Os OTFs também fornecem integração com dados externos no data lake, o que permite que dados externos sejam usados como uma tabela SQL, se necessário. Ou os dados externos podem ser transformados e roteados para o data warehouse usando mecanismos de processamento de alta velocidade e comandos SQL familiares.
Portanto, o data lake moderno é mais do que apenas um data warehouse e um data lake em um pacote com um nome diferente. Coletivamente, eles fornecem mais valor do que o encontrado em um data warehouse convencional ou em um data lake independente.
Arquitetura Conceitual
A disposição em camadas é uma maneira conveniente de apresentar os componentes e serviços necessários ao data lake moderno. A disposição em camadas fornece uma maneira clara de agrupar serviços que fornecem funcionalidade semelhante. Também permite estabelecer uma hierarquia, com os consumidores no topo e as fontes de dados (com os seus dados brutos) na parte inferior. As camadas do data lake moderno, de cima para baixo, são:
- Camada de consumo: Contém as ferramentas usadas por usuários avançados para analisar dados. Também contém aplicativos e cargas de trabalho de IA/ML que acessarão programaticamente o data lake moderno.
- Camada semântica: Uma camada de metadados opcional para descoberta e governança de dados.
- Camada de processamento: Esta camada contém os clusters de computação necessários para consultar o data lake moderno. Ele também contém clusters de computação usados para treinamento de modelos distribuídos. Transformações complexas podem ocorrer na camada de processamento usando a integração da camada de armazenamento entre o data lake e o data warehouse.
- Camada de armazenamento: O armazenamento de objetos é o principal serviço de armazenamento para o data lake moderno; no entanto, as ferramentas de operações de aprendizado de máquina (MLOps) podem precisar de outros serviços de armazenamento, como bancos de dados relacionais. Se você estiver buscando IA generativa, precisará de um banco de dados vetorial.
- Camada de ingestão: Contém os serviços necessários para receber dados. A ingestão avançada pode recuperar dados com base em uma programação. O data lake moderno deve oferecer suporte a uma variedade de protocolos. Deve também suportar dados que chegam em fluxos e lotes. Transformações de dados simples e complexas podem ocorrer na camada de ingestão.
- Fontes de dados: A camada de fontes de dados tecnicamente não faz parte da solução moderna de data lake, mas está incluída neste artigo porque um data lake moderno bem construído deve suportar uma variedade de fontes de dados com capacidades variadas para envio de dados.
O diagrama abaixo descreve visualmente essas camadas e os recursos que podem ser necessários para implementá-las. Esta é uma arquitetura ponta a ponta onde o coração da plataforma é um data lake moderno. Este diagrama também mostra os componentes necessários para ingerir, transformar, descobrir, governar e consumir dados. Ele também descreve as ferramentas necessárias para dar suporte a casos de uso importantes que dependem de um data lake moderno, como armazenamento MLOps, bancos de dados vetoriais e clusters de aprendizado de máquina.
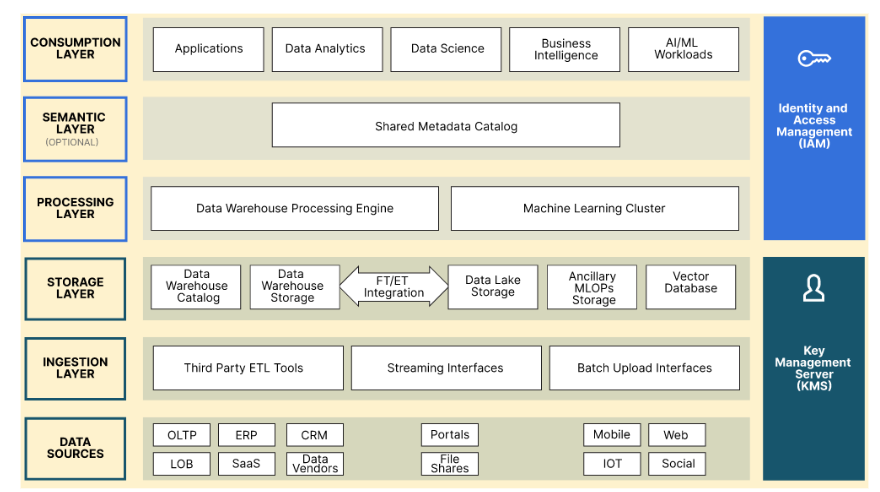
Fonte: Arquitetura de referência moderna do Data Lake
A camada de armazenamento e a camada de processamento estão no centro de um data lake moderno. Estas duas camadas também contêm as tecnologias de evolução mais rápida para a construção de uma infra-estrutura de dados: armazéns de dados construídos com formatos de tabelas abertos, armazenamento de objectos de alta velocidade e bases de dados vectoriais.
A camada de armazenamento
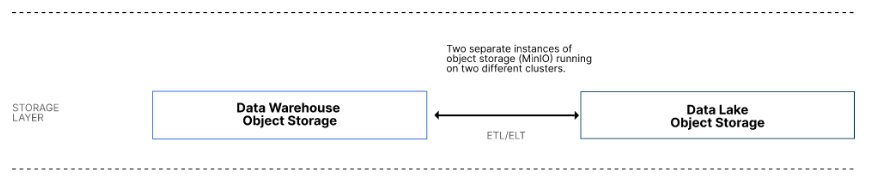
Fonte: Arquitetura de referência moderna do Data Lake
A camada de armazenamento de dados é a base da qual todas as outras camadas dependem. Seu objetivo é armazenar dados de maneira confiável e atendê-los com eficiência. Ele contém serviços de armazenamento de objetos separados para o data lake e para o lado do data warehouse do data lake moderno.
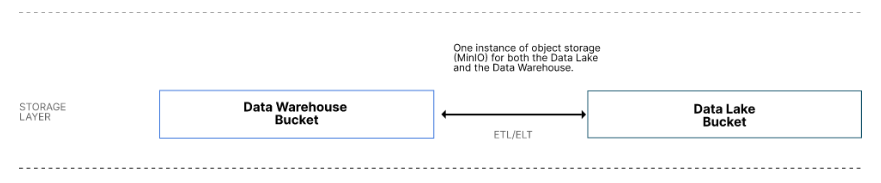
Fonte: Arquitetura de referência moderna do Datalake
Esses dois serviços de armazenamento de objetos podem ser combinados em uma instância física de um armazenamento de objetos, se necessário, usando buckets para manter o armazenamento do data warehouse separado do armazenamento do data lake. No entanto, se a sua camada de consumo e os pipelines de dados colocarem cargas de trabalho diferentes nesses dois serviços de armazenamento, considere mantê-los separados e instalá-los em hardware diferente.
Por exemplo, um fluxo de dados comum é fazer com que todos os novos dados cheguem ao data lake. Em seguida, ele pode ser transformado e ingerido no data warehouse, onde pode ser consumido por outros aplicativos e usado para ciência e análise de dados. Neste fluxo de dados, o data lake moderno coloca mais carga em seu data warehouse, então você desejará executá-lo em hardware de última geração (dispositivos de armazenamento, clusters de armazenamento e rede).
A funcionalidade de tabela externa permite que data warehouses e mecanismos de processamento leiam objetos no data lake como se fossem tabelas SQL. Se o data lake for usado como zona de destino para dados brutos, esse recurso, juntamente com os recursos SQL do data warehouse, poderá ser usado para transformar dados brutos antes de inseri-los no data warehouse. Como alternativa, a tabela externa poderia ser usada “no estado em que se encontra” e unida a outras tabelas e recursos dentro do data warehouse, sem nunca sair do data lake. Este padrão pode ajudar a poupar nos custos de migração e a superar algumas preocupações de segurança de dados, mantendo os dados num só local e, ao mesmo tempo, disponibilizando-os a serviços externos.
Você também pode buscar uma estratégia de IA/ML com essa arquitetura de referência, mas isso está além do escopo deste artigo. Nossa arquitetura de referência para um data lake moderno de IA/ML fornece informações sobre a construção de uma infraestrutura de dados de IA.
A camada de processamento
A camada de processamento contém a computação necessária para todas as cargas de trabalho suportadas pelo data lake moderno. Em alto nível, a computação vem em duas variedades: mecanismos de processamento para o data warehouse e clusters para aprendizado de máquina distribuído.

Fonte: Arquitetura de referência moderna do Data Lake
O mecanismo de processamento do data warehouse oferece suporte à execução distribuída de comandos SQL nos dados no armazenamento do data warehouse. As transformações que fazem parte do processo de ingestão também podem precisar do poder computacional da camada de processamento. Por exemplo, em alguns data warehouses, você pode desejar usar uma arquitetura medalhão; em outros, você pode escolher um esquema em estrela com tabelas dimensionais. Esses designs geralmente exigem extração, transformação e carregamento (ETL) substanciais em relação aos dados brutos durante a ingestão.
O data warehouse em um data lake moderno desagrega a computação do armazenamento. Portanto, se necessário, podem existir vários mecanismos de processamento para um único armazenamento de dados de data warehouse. (Isso difere de um banco de dados relacional convencional, onde a computação e o armazenamento estão fortemente acoplados e há um recurso de computação para cada dispositivo de armazenamento.)
Um possível projeto de camada de processamento é configurar um mecanismo de processamento para cada entidade na camada de consumo. Por exemplo, usando um cluster de processamento para business intelligence (BI), um cluster separado para análise de dados e outro para ciência de dados. Cada mecanismo de processamento consultaria o mesmo serviço de armazenamento de data warehouse; no entanto, como cada equipe tem seu próprio cluster dedicado, eles não competirão entre si pela computação. Se a equipe de BI estiver executando relatórios de final de mês com uso intensivo de computação, eles não interferirão na execução de relatórios diários por outra equipe.
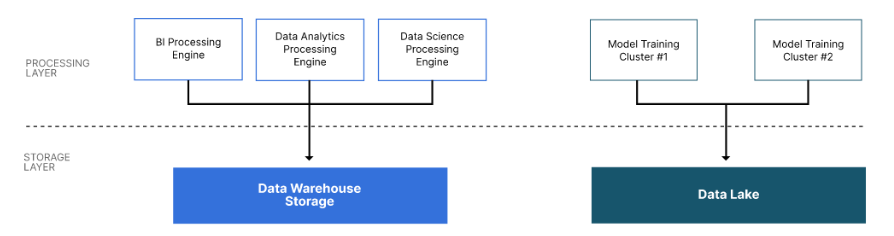
Fonte: Arquitetura de referência moderna do Data Lake
Modelos de aprendizado de máquina, especialmente modelos de linguagem grandes, podem ser treinados mais rapidamente se o treinamento for feito de forma distribuída. O cluster de aprendizado de máquina oferece suporte ao treinamento distribuído. O treinamento distribuído deve ser integrado a uma ferramenta MLOps para rastreamento e checkpoint de experimentos.
Resumo
Este artigo apresenta uma arquitetura de referência de alto nível para um data lake moderno e explora seus componentes principais. O objetivo é fornecer às organizações um plano estratégico para construir uma plataforma que gerencie e extraia valor de forma eficiente de seus vastos e diversificados conjuntos de dados.
O data lake moderno combina os pontos fortes de um data warehouse baseado em OTF e um data lake flexível, oferecendo uma solução unificada e escalonável para armazenamento, processamento e análise de dados. Se você quiser se aprofundar nesses conceitos, entre em contato com a equipe Min.io em hello@min.io.
A postagem O Guia do Arquiteto: Uma Arquitetura Moderna de Referência de Data Lake apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}
{kind=link}