
Implante o sistema de diretório LDAP em um servidor Ubuntu
13 de abril de 2024
Notícias dos desenvolvedores: Agente de codificação AI, Nue Glows e novo Android Beta
13 de abril de 2024
Um Grande Modelo de Linguagem representa um momento da história, congelado para sempre na época em que foi construído. Aproveitar um LLM que não inclui informações atuais ou inacessíveis é um problema que a maioria das aplicações sérias precisa resolver. Aqui, o termo “inacessível” pode significar informações privadas ou específicas de domínio. Sem ele, é mais provável que um LLM tenha alucinações.
Expliquei um pouco sobre bancos de dados vetoriais e mencionei Retrieval Augmented Generation (RAG) como um método para introduzir novos dados em um LLM sem treiná-los novamente. LlamaIndex é uma ferramenta que foca no ‘R’ (para recuperação) para ajudar a enriquecer um prompt com seus dados.
Agora, antes de continuarmos, vamos resumir brutalmente por que estamos fazendo o que estamos fazendo. Um transformador pré-treinado geral (ou GPT, e intimamente associado à marca OpenAI) descreve um ciclo de entrada, transformação e saída por meio de multiplicações de matrizes onde palavras (na verdade, tokens de texto, ou sons, ou imagens) são convertidas em vetores com dimensões suficientes para, esperançosamente, expressar significado. Para garantir que o contexto do texto recebido seja calculado, pagamos atenção para verbos próximos para aproximar os vetores de seu significado contextual (por exemplo, um “buraco negro” não é apenas um buraco escuro) por meio de mais blocos de multiplicação de matrizes:
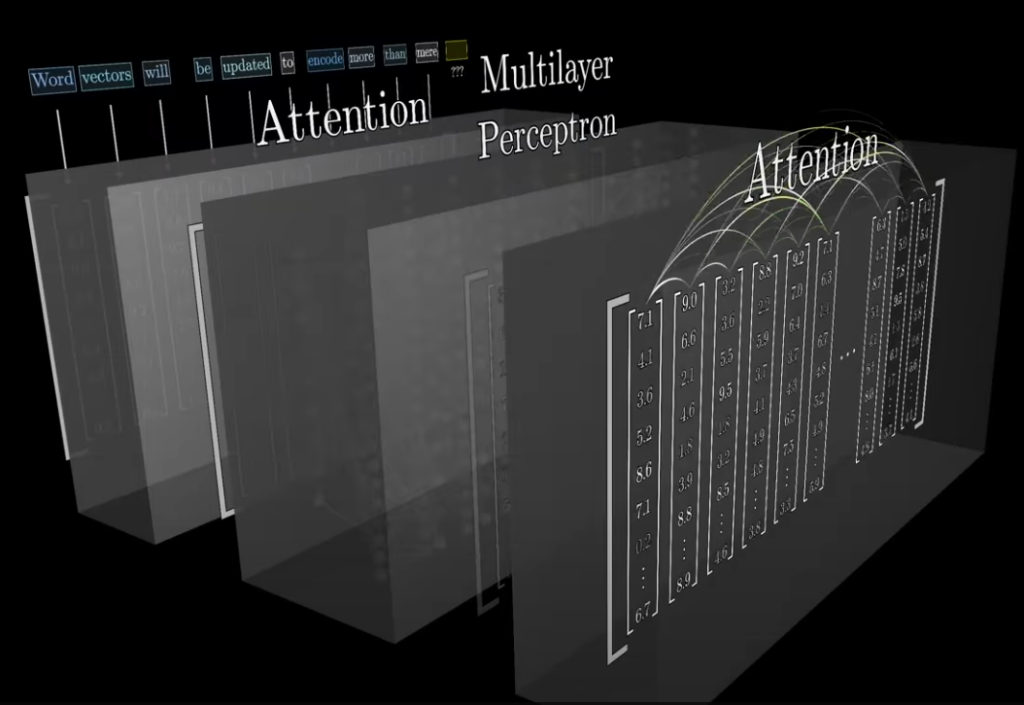
De Mas o que é um GPT? Por 3Blue1Brown
Esperamos que o produto final seja um ótimo palpite sobre a próxima palavra. Mas essas suposições são tão boas quanto o corpus do texto de entrada. E se quisermos perguntar ao ChatGPT sobre um texto que ele não aprendeu? Não podemos inserir grandes quantidades de texto na consulta, porque isso é limitado por uma janela. Por isso, viemos para RAG.
Primeiros passos com LlamaIndex
Vamos direto ao LlamaIndex. Felizmente, existe um início rápido que promete começar com “5 linhas de código”.
Agora fiz várias instalações locais do LLM, mas para esta postagem, usarei minha chave OpenAI e gravarei alguns créditos. Use-o Código do Visual Studio quando eu quiser executar o Python brevemente, o que adicionará um pouco de destroços à postagem, mas os mesmos pontos de contato serão abordados independentemente de como você entrar.
No meu Mac, vou apenas verificar a instalação do Python3 no Homebrew. Então, abrindo meu terminal Warp, começarei com:
>brew install python3
Após a conclusão do Homebrew, confirmo o que tenho:

Em seguida, inicio o VS nesta pasta vazia. Instalei a extensão Python, segui as boas práticas e fiz um projeto específico ambiente virtual na paleta de comandos, usando Python: Crie um ambiente. Eu então queimei Venv. Isso termina confirmando que estou usando o Python que acabei de instalar:

OK, agora é melhor voltar às instruções do LlamaIndex e usar pip para instalar o pacote lama-index conforme necessário, em meu ambiente virtual dentro do VS Code usando um terminal ativo (receio que não no Warp):


Precisarei informar ao meio ambiente sobre minha chave OpenAI. Dada a natureza do ambiente virtual executado em um IDE, é mais seguro manter isso no lançamento.json arquivo que o VS Code cria quando executa um projeto:
..
"configurations":
(
{
"name": "Python Debugger: Current File",
"type": "debugpy",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal",
"env":
{
"OPENAI_API_KEY": "XXXX"
}
}
)
..
(Talvez seja necessário criar uma conta OpenAI, é claro. Suspeito que a conta ‘XXXX’ já esteja esgotada!)
Seguindo o conselho do tutorial inicial do LlamaIndex, baixei uma mesa narrativa de Paul Graham em uma pasta chamada dados. É apenas uma longa biografia.
No VS Code, criei starter.py
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
O importante é que o pacote lhama_index foi resolvido. Felizmente, nada disso requer conhecimento profundo de Python. Você pode ver claramente que imprimiremos a resposta à nossa consulta.
Aqui está a resposta:

Para confirmar que eu realmente usei OpenAIaqui estão minhas estatísticas da atividade da minha conta:
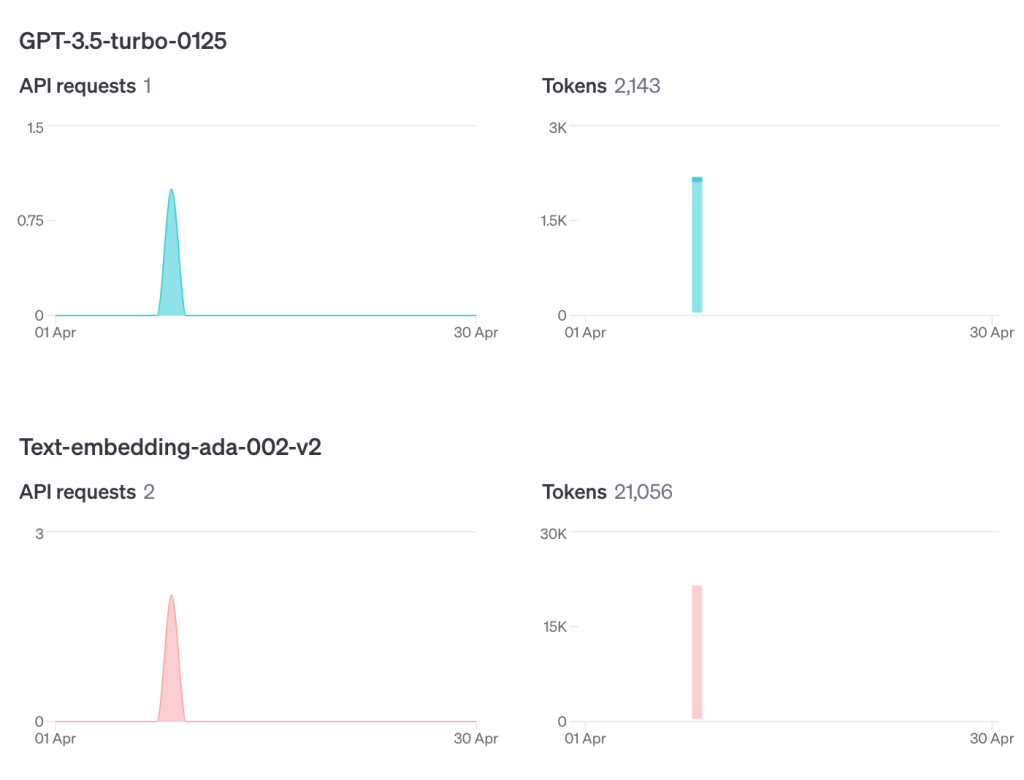
Então, o que esse código está fazendo? Ele incorporou o novo texto em um armazenamento de vetores e forneceu um índice (daí a chamada para VectorStoreIndex) e isso é recuperado no momento da consulta e adicionado à janela de contexto em inglês, pouco antes da chamada passar para o GPT-3.5. Daí o termo enriquecer vimos anteriormente.
Ao adicionar duas linhas de código de registro, consegui extrair muitas chamadas REST densas, mas também este detalhe útil do lhama_index pacotes:
DEBUG:llama_index.core.indices.utils:> Top 2 nodes: > (Node 167d0eb4-7dba-4b93-85ec-3f5779b32daa) (Similarity score: 0.819982) "What I Worked On February 2021 Before college the two main things I worked on, outside of school..." > (Node ee847bc2-d56a-4c26-afd7-c4bee9a3d116) (Similarity score: 0.811733) "I remember taking the boys to the coast on a sunny day in 2015 and figuring out how to deal with ..."
Isso dá uma dica do que está acontecendo nos bastidores.
Antes de concluirmos, adicionarei outro documento à pasta de dados, um que já usei antes: os sonetos de Shakespeare. Claro, é possível que estes sejam conhecidos pelo LLM, mas duvido. O que é mais importante é que um monte de poemas não constitui uma narrativa significativa.

Portanto, executaremos esta consulta extra, com esta pergunta adicional propositalmente vaga:
..
response = query_engine.query("Who is Blessed?")
print(response)
E a resposta curta que obtemos é:
Adonis is Blessed.
Interessante. Vamos pegar a única área dos sonetos onde Adônis é mencionado:
“Bem-aventurado você cujo mérito dá espaço, Ser teve que triunfar, faltando esperança. Qual é a sua substância, da qual você é feito, Que milhões de sombras estranhas sobre você tendem? Já que cada um tem uma sombra, E você, apenas uma, pode emprestar cada sombra: Descreva Adônis e a falsificação, É mal imitado depois de você, Na bochecha de Helen toda a arte da beleza é colocada, E você em pneus gregos é pintado de novo : Fale da primavera e do final do ano, Um mostra a sombra de sua beleza, O outro como sua generosidade aparece, E você em todas as formas abençoadas que conhecemos.
Isso é confirmado observando os nós de log, como os que vimos anteriormente:
DEBUG:llama_index.core.indices.utils:> Top 2 nodes: > (Node 38e29f53-3656-4b55-ab6b-08acf898f122) (Similarity score: 0.766188) "Blessed are you whose worthiness gives scope, Being had to triumph, being lacked to hope. What i..." > (Node 16d55fda-34ac-42cf-9b08-66d2c6944302) (Similarity score: 0.730936) "And other strains of woe, which now seem woe, Compared with loss of thee, will not seem so. Some..."
A maior parte disso é o Soneto 53. E o termo “abençoado” aparece perto de “Adônis”. Claro, um LLM sempre lhe dará uma resposta e parecerá definitivo!
No entanto, nada disso é um problema para o LlamaIndex, que teve um desempenho bastante bom. Acabei de usar as primeiras etapas para construir um pipeline e o LlamaIndex oferece mais maneiras de trabalhar com documentos dessa maneira.
Embora seja verdade que ainda não temos uma linguagem abrangente para descrever o que está acontecendo internamente, usar RAG via LlamaIndex é uma maneira sólida de aprimorar um LLM com informações específicas do domínio, bem como garantir que o conhecimento verificável seja processado. Tudo isso ajuda a reduzir as chances de respostas erradas – o único problema que ainda persegue a IA hoje.
A postagem Guia do desenvolvedor para começar a usar o LlamaIndex apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}
{kind=link}