
Instalação do oVirt com nó único hiperconvergente GlusterFS – mais ou menos
20 de maio de 2024
Apresentando o Kubernetes Automático e Gerenciado do AKS para Desenvolvedores
21 de maio de 2024
Com sua plataforma de ponta a ponta Fabric, a Microsoft tem trabalhado arduamente para eliminar o atrito de seus clientes em todos os aspectos da análise de dados.
Nessa busca, em sua conferência de desenvolvedores Build em Seattle hoje, a empresa anunciou a prévia pública de melhorias significativas nos recursos de processamento e análise de dados em tempo real do Fabric. Esses aprimoramentos incluem a fusão do Synapse Real-Time Analytics e do Data Activator no sistema unificado Real-Time Inteligência componente; conectividade com uma variedade de novas fontes de dados de streaming, incluindo aquelas na Amazon Web Services e Google Cloud; novos painéis em tempo real e a exploração visual de dados que os acompanham, e a introdução do hub em tempo real, que torna as fontes de dados de streaming mais detectáveis e facilita sua integração com Fabric Lakehouses para resolver a desconexão entre dados em movimento e dados em -descansar.
Um passo a frente
A carga de trabalho (módulo) Synapse Real-Time Analytics da Fabric já fez muito para tornar a análise em tempo real mais fácil e mais integrada com análise em lote, BI e aprendizado de máquina. A poderosa abstração de fluxo de eventos desse módulo, junto com o componente Data Activator do Fabric para monitoramento e alerta de dados, e seu banco de dados KQL (que foi gradualmente rebatizado como “Casa de eventos”) já havia criado uma solução bastante atraente. Mas cada um dos componentes do Fabric mencionados acima tem sido um tanto desconexo e usá-los juntos exigiu algum conhecimento e esforço por parte do cliente. Ironicamente, é exatamente esse tipo de fardo para o cliente que a Fabric pretende eliminar, então a situação tem sido um pouco anormal.
Em resposta, a equipe da Fabric trabalhou para melhorar cada um desses componentes e integrá-los de forma mais estreita, exigindo menos esforço e conhecimento do cliente para usá-los juntos. Como resultado, a plataforma Fabric como um todo é agora mais orientada a eventos e seus recursos em tempo real são mais acessíveis para usuários corporativos e analistas. A Microsoft fez melhorias nas áreas de ingestão e processamento de dados de streaming; descoberta; análise; visualização e exploração sem código; e gatilhos orientados a eventos. Seguem os destaques de cada área de melhoria e concluo com algumas reflexões sobre o que tudo isso significa para a posição competitiva da Microsoft na área de análise de dados.
Ingestão e processamento de dados de streaming
Já uma abstração poderosa, os fluxos de eventos do Fabric agora podem ingerir dados do Amazon Kinesis Data Streams, do Google Pub/Sub e até mesmo de tópicos do Kafka na plataforma Confluent Cloud, tudo isso além dos Hubs de Eventos do Azure e da conectividade do IoT Hub que eles já tinham. Os fluxos de eventos agora também podem ser ingeridos a partir de uma variedade de fontes de captura de dados de alteração (CDC) da Microsoft, incluindo o Banco de Dados SQL do Azure (a implementação na nuvem do SQL Server), o Azure Cosmos DB e as implementações do Azure dos bancos de dados MySQL e PostgreSQL de código aberto.
Por fim, os fluxos de eventos podem receber dados de eventos do Azure Blob Storage (bem como do Azure Data Lake Storage) e até mesmo do próprio Fabric. Embora o último desses recursos possa parecer um nicho, na verdade é bastante significativo. Responder a eventos do Fabric significa que toda a plataforma do Fabric pode se tornar orientada a eventos, permitindo cenários como a ingestão de dados no Lakehouse quando um novo arquivo chega ao armazenamento em nuvem ou o retreinamento de um modelo de aprendizado de máquina quando um Lakehouse é atualizado.
A nova variedade de fontes de dados de streaming disponíveis na experiência “Get Events” do Fabric
A funcionalidade dos fluxos de eventos também foi aprimorada. Transformar os dados à medida que chegam é agora mais fácil; rotear dados com base em tais transformações, ou filtros, agora também é possível. E a criação de “fluxos derivados” com base na saída dessas transformações e filtros, para posterior consumo downstream, tornou-se trivial de implementar. Eventstreams agora também possuem modos distintos de edição e visualização. O modo Editar permite que o desenvolvimento ocorra de maneira quase off-line, garantindo que os fluxos de eventos em produção não serão interrompidos. Depois que tudo tiver sido suficientemente testado, o fluxo de eventos novo ou atualizado poderá ser publicado explicitamente.
Descoberta
A adição do novo hub Fabric Real-Time, juntamente com o hub de dados OneLake implementado anteriormente, torna as fontes de dados de streaming muito mais fáceis de descobrir, consumir e analisar. São fornecidas listas separadas para fluxos de dados, fontes da Microsoft e eventos do Fabric. A lista de fluxos de dados inclui fluxos padrão e derivados de fluxos de eventos, bem como tabelas em bancos de dados de eventos. Por padrão, essas listas incluem tudo o que o usuário tem acesso, mas é possível filtrá-las. Os fluxos de dados podem ser filtrados por espaço de trabalho, proprietário, tipo (fluxo ou tabela) ou item pai (fluxo de eventos ou banco de dados da casa de eventos) e a lista de fontes da Microsoft pode ser filtrada por tipo de fonte ou por assinatura do Azure, grupo de recursos ou região.
É importante mencionar que a capacidade de criar fluxos derivados e, em seguida, apresentá-los (e endossá-los como recomendados ou certificados) para usuários downstream no hub em tempo real, essencialmente os torna disponíveis como produtos de dados. Embora isso sempre tenha sido possível no Fabric com os dados mais estáticos em Data Lakehouses, essa forma de compartilhar dados de streaming que já foram limpos, transformados e curados é uma implementação poderosa da metodologia de malha de dados, especialmente quando combinada com a capacidade do Fabric de criar domínios organizacionais.
Análise
Embora a maior parte do que está sendo anunciado hoje esteja em pré-visualização privada, a tecnologia da casa de eventos da Fabric já está disponível ao público geral (GA). As casas de eventos são ao mesmo tempo uma reformulação da marca dos bancos de dados KQL, baseados na poderosa tecnologia de banco de dados de série temporal “Kusto” da Microsoft e, ao mesmo tempo, um aprimoramento de sua funcionalidade e ferramentas de gerenciamento. As casas de eventos permitem que vários bancos de dados KQL sejam usados e gerenciados juntos, permitindo que sejam federados e tratados como uma espécie de mecanismo de particionamento.
Isso é especialmente verdadeiro porque um único pool de computação pode servir todos os bancos de dados KQL individuais em uma casa de eventos. GA também é a capacidade dos bancos de dados Eventhouses/KQL de replicar seus dados no OneLake, permitindo que todos os outros mecanismos no Fabric, incluindo Fabric Data Warehouses, Apache Spark e Power BI, consultem e analisem os dados de streaming acumulados.
Visualização e exploração sem código
Mas se você são Para continuar com a tecnologia da Event House, você precisa de uma maneira de visualizar os dados, explorá-los e consultá-los de forma ad hoc. E dado que KQL é uma linguagem de consulta separada do SQL, pode haver impedimentos na curva de aprendizado. A Microsoft pretende superar esses impedimentos por meio de três novos recursos: painéis em tempo real, exploração visual interativa de dados e um Copilot especial que pode gerar KQL a partir de questões de linguagem natural.
Os dashboards são extremamente interessantes, pois lembram relatórios do Power BI, mas na verdade são baseados em tecnologias diferentes. Existem alguns motivos pelos quais isso faz sentido. Primeiro, os bancos de dados KQL (e seus precursores do pool Azure Data Explorer e Synapse Analytics Data Explorer) há muito tempo têm a capacidade de produzir suas próprias visualizações – fazer isso é um primitivo integrado do KQL. Faz sentido aproveitar esse recurso e estendê-lo para combinar várias visualizações lado a lado baseadas em consultas em painéis. Em segundo lugar, a análise de dados de séries temporais tem semântica própria e exige visualização especializada. Embora os gráficos básicos, como gráficos de barras, colunas, pizza, área e linhas, façam parte do mix, também o fazem tipos de visualização especializados, como gráficos de tempo, gráficos de anomalias e gráficos estatísticos/multiestatísticos. Enquanto isso, como seus equivalentes no Power BI, os painéis em tempo real suportam filtragem cruzada e detalhamento.
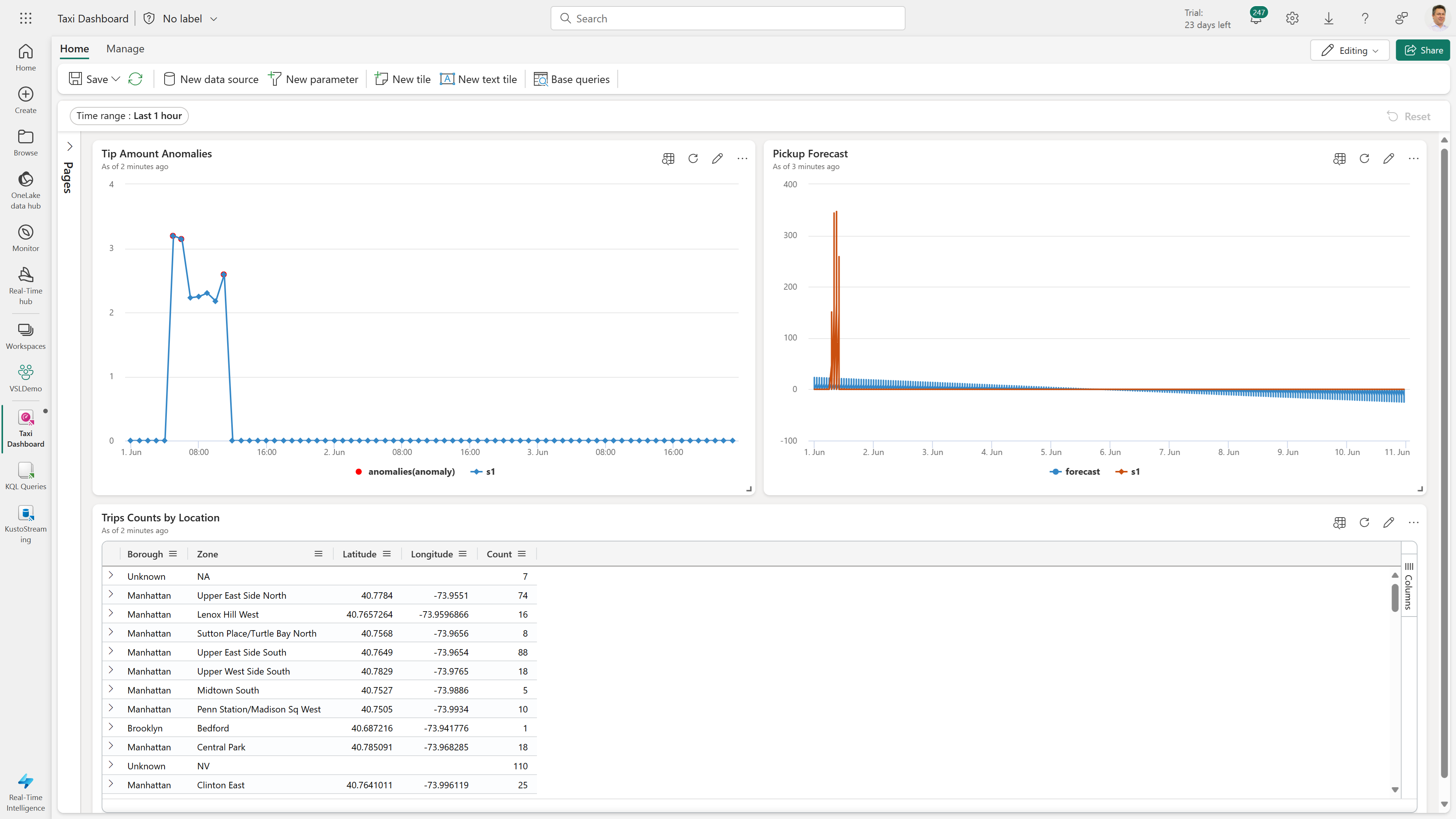
Um painel em tempo real do Fabric, com visualizações KQL lado a lado
Além disso, como cada visualização em um painel em tempo real é baseada em uma consulta KQL distinta, fica mais fácil pegar qualquer uma delas isoladamente e abri-la para ajustes e modificações iterativas (incluindo a adição de filtros, criação de agregações, e troca de tipos de visualização) sem editar as consultas subjacentes. Isso forma a base da exploração visual de dados do Fabric Real-Time Intelligence. Os usuários podem fazer esses ajustes por meio de uma interface de usuário, e cada modificação se manifesta como uma alteração correspondente à consulta KQL subjacente. Essa abordagem específica de análise de série temporal simplesmente não seria possível no Power BI atual, que é mais focado na agregação dimensional e no detalhamento de dados tabulares.
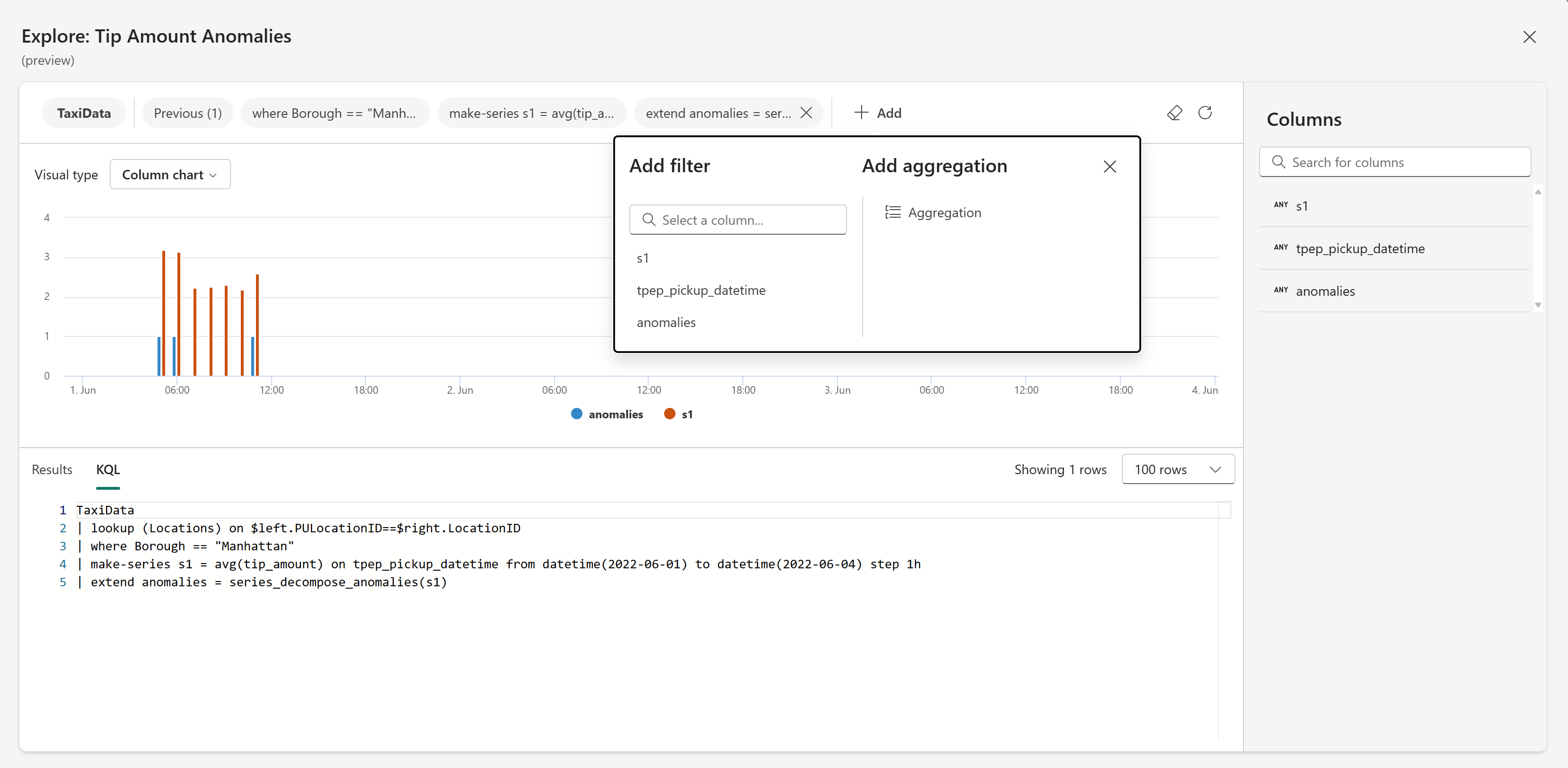
Experiência de exploração de dados em tempo real do Fabric, permitindo modificação sem código de consultas KQL
Se isso ainda não for bom o suficiente, a Microsoft está lançando um Copilot for Real-Time Intelligence, que é inteligente o suficiente para responder perguntas em linguagem natural (“inglês simples”) e produzir consultas KQL a partir delas que podem ser coladas em um editor KQL Queryset e executadas. . Essa abordagem de geração de consultas tem o efeito colateral de ensinar KQL por exemplo para usuários menos técnicos, permitindo que os usuários avançados aprendam a linguagem e, eventualmente, escrevam essas consultas do zero, caso se sintam interessados e capazes.
Gatilhos
A última peça do quebra-cabeça do Fabric Real-Time Intelligence é a capacidade de criar gatilhos e alertas baseados em dados com muito mais facilidade do que antes. Em vez de precisar acessar a interface do usuário do Data Activator, os usuários do Fabric podem criar gatilhos e alertas no contexto, enquanto editam fluxos e blocos do painel ou enquanto estão no hub Real-Time. Cada ação criará um novo objeto Fabric Reflex na área de trabalho, e esses objetos podem fazer mais do que antes. Além da capacidade pré-existente de enviar alertas como e-mails ou mensagens no Teams, os gatilhos agora podem iniciar verdadeiras unidades de trabalho, incluindo pipelines de dados, notebooks e definições de trabalho do Spark. Isso significa que todos esses pacotes executáveis passam de apenas execução sob demanda ou de forma programada para serem executados também com base em eventos.
Conclusão
Há anos venho dizendo que trabalhar com dados de eventos de streaming em tempo real tem sido uma especialidade segregada na análise. A análise em tempo real exigiu suas próprias plataformas e conjuntos de habilidades, exigindo muitas vezes pessoal distinto para trabalhar com ela. Isto tornou a noção de “análise de 360 graus”, seja para a experiência do cliente, manutenção preditiva ou análise do mercado financeiro, um desafio e muitas vezes propenso ao fracasso. Isso sempre foi frustrante, mas na era da IA tornou-se inaceitável.
A Microsoft está trabalhando arduamente para preencher essa lacuna. Se este lançamento realmente faz isso está em debate. Acontece que acho que há muito mais trabalho a fazer e que a integração das tecnologias Eventstream, Data Activator/Reflex e Eventhouse tem mais distância a percorrer. Também estou preocupado que a divergência dos painéis em tempo real do Power BI possa ser perigosa.
Mas acredito que a Microsoft está pensando mais seriamente do que a maioria de seus concorrentes sobre como reunir dados de eventos de streaming e dados em repouso, de uma forma que seja utilizável e intuitiva, para engenheiros, analistas e usuários corporativos. E isso não é apenas uma estratégia abstrata — a empresa está construindo e enviando coisas, e esse conjunto de melhorias no Fabric prova isso.
Divulgação: O autor da postagem, Andrew Brust, é MVP da Microsoft Data Platform e membro do Programa de Diretores Regionais da Microsoft para influenciadores independentes. Sua empresa, Blue Badge Insights (www.bluebadgeinsights.com), trabalhou para a Microsoft, inclusive para partes da equipe Fabric.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER



{kind=link}
{kind=link}
{kind=link}