
Dell apresenta novos produtos Edge, IA generativa, nuvem e Zero Trust
24 de janeiro de 2024
Dimensionando ambientes com OpenTelemetry e Service Mesh
24 de janeiro de 2024
A Microsoft está lançando hoje em versão prévia pública uma versão nova e totalmente renovada de seu moderno serviço de pilha de dados baseado em nuvem HDInsight (HDI). A nova versão, batizada de HDI no AKS (Azure Kubernetes Services), suportará inicialmente três tipos de cluster, baseados na plataforma de análise, engenharia de dados e aprendizado de máquina Apache Spark; a plataforma Apache Flink para streaming e processamento de dados em lote e o mecanismo de consulta Trino para data lake e análise de consulta federada. Confira: Data 2023 Outlook: repensando a pilha de dados moderna Como o próprio nome indica, o novo serviço tem como premissa tecnologias de contêiner baseadas em Kubernetes, em vez de máquinas virtuais. Isto significa que, uma vez criado um HDI no “pool de clusters” do AKS, o provisionamento e desprovisionamento de clusters individuais em execução nesse pool torna-se um processo muito mais simples e ágil do que para clusters na versão original do HDI.
O que há de errado com o antigo
Falando da versão original, um curso intensivo em análise de código aberto é necessário. No início da era do “big data”, o projeto de código aberto Apache Hadoop reinou supremo. Naquela época, a Microsoft lançou o HDInsight como seu serviço Hadoop baseado em nuvem. A oferta, construída em colaboração com a antiga Hortonworks, acabou se expandindo para incluir tipos de cluster otimizados para outros mecanismos de código aberto, incluindo Apache Spark, Kafka, HBase e Hive LLAP. Leia também: O Kubernetes afundará o navio Hadoop? O serviço HDI original ainda funciona hoje, mas perdeu relevância devido a uma série de fatores. Isso inclui o lançamento do Azure Databricks, do Azure Synapse Analytics e o recente lançamento público do Microsoft Fabric, todos aproveitando o Apache Spark (que é muito mais adequado para análises interativas do que o Hadoop) e que também oferece ferramentas mais sofisticadas e facilidade de uso. usar. Outra questão é que a fusão da Hortonworks com a Cloudera em 2019 levou à descontinuação de sua distribuição Hadoop da Hortonworks Data Platform (HDP). Embora a Microsoft tenha construído seu próprio clone dessa distribuição totalmente baseado em bits de código aberto Apache, a tecnologia ainda sofreu com o estigma da obsolescência. Histórico do Microsoft Fabric: Microsoft Fabric desfragmenta análise e entra na visualização pública Outro fator inclui a crescente popularidade de várias novas estruturas de código aberto, que a HDI nunca integrou. Isso inclui dois dos novos componentes do HDI: o mecanismo de consulta de data lake Trino, uma evolução do mecanismo de banco de dados Presto original desenvolvido no Facebook, e a plataforma de processamento de dados de streaming Apache Flink. Há também a questão de que, embora o HDI original ofereça um cluster Spark, ele ainda é amplamente baseado no gerenciador de recursos do Hadoop, conhecido como “YARN”. E, finalmente, a arquitetura baseada em máquinas virtuais do HDI original tornou a implantação de clusters lenta e complicada.
Coexistência Cooperativa, não Destruição Criativa
Apesar de ambas as versões do HDInsight oferecerem tipos de cluster Spark, os dois serviços são em grande parte complementares, pelo que a sua coexistência pode ser facilmente racionalizada. Além disso, a presença do Trino, que suporta conectividade e consultas federadas entre uma grande variedade de fontes de dados de back-end, significa que o HDI no AKS pode conectar-se e integrar uma série de outros serviços de dados do Azure. Estes incluem Banco de Dados SQL do Azure, Synapse Analytics e até Banco de Dados Azure para MySQL, PostgreSQL e MariaDB. E como o Power BI pode, por sua vez, conectar-se ao Trino, a história da integração ponta a ponta é boa. Embora a natureza complementar do IDH no AKS, em relação ao IDH original, seja tranquilizadora, a maior questão que permanece é como racionalizar a coexistência do novo serviço com o Synapse Analytics e, talvez mais importante, o emergente Microsoft Fabric. Se as mesmas cargas de trabalho puderem ser acomodadas em ambos, e a Microsoft estiver disponibilizando ambos, isso deixará em aberto para os clientes da Microsoft/Azure qual usar e quando.
Faça você mesmo vs. EU IA
A resposta está nas modalidades de uso: se você quiser trabalhar com HDI no AKS, precisará se preparar para trabalhar com código, interfaces de linha de comando (CLIs) e ferramentas externas. Por exemplo, se você construir um cluster Trino, precisará fazer uma das três coisas para trabalhar com ele: (1) baixar a CLI do Trino para seu próprio computador; (2) estabelecer uma sessão Secure Shell (SSH) com o cluster e executar a CLI a partir daí (conforme mostrado abaixo, você pode fazer isso em um navegador da web, no Portal do Azure); ou (3) conectar-se ao Trino a partir de uma ferramenta de consulta externa (por exemplo, DBeaver) usando um driver JDBC projetado especificamente para Trino em HDI para AKS.
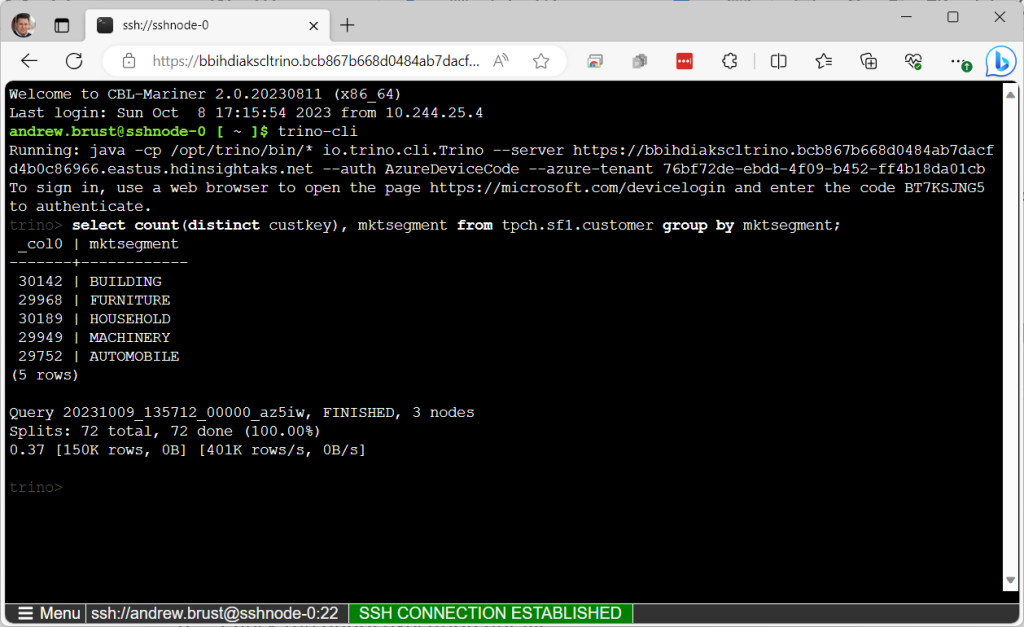
Uma sessão Trino CLI via SSH no portal do Azure. Uma consulta SQL e seu conjunto de resultados são mostrados.
Flink também possui um cliente SQL acessível via SSH. Os clusters Spark são mais flexíveis, pois podem ser acessados no código dos notebooks Jupyter disponíveis diretamente na folha Visão geral do cluster no Portal do Azure ou em várias ferramentas externas. Embora Trino, Flink e Spark tenham suas próprias interfaces de usuário, todas facilmente acessadas a partir do Portal do Azure, essas UIs servem como ferramentas de gerenciamento para a infraestrutura do cluster e monitoram trabalhos ou consultas (conforme mostrado abaixo, para Flink), em vez de do que desenvolvê-los e submetê-los.
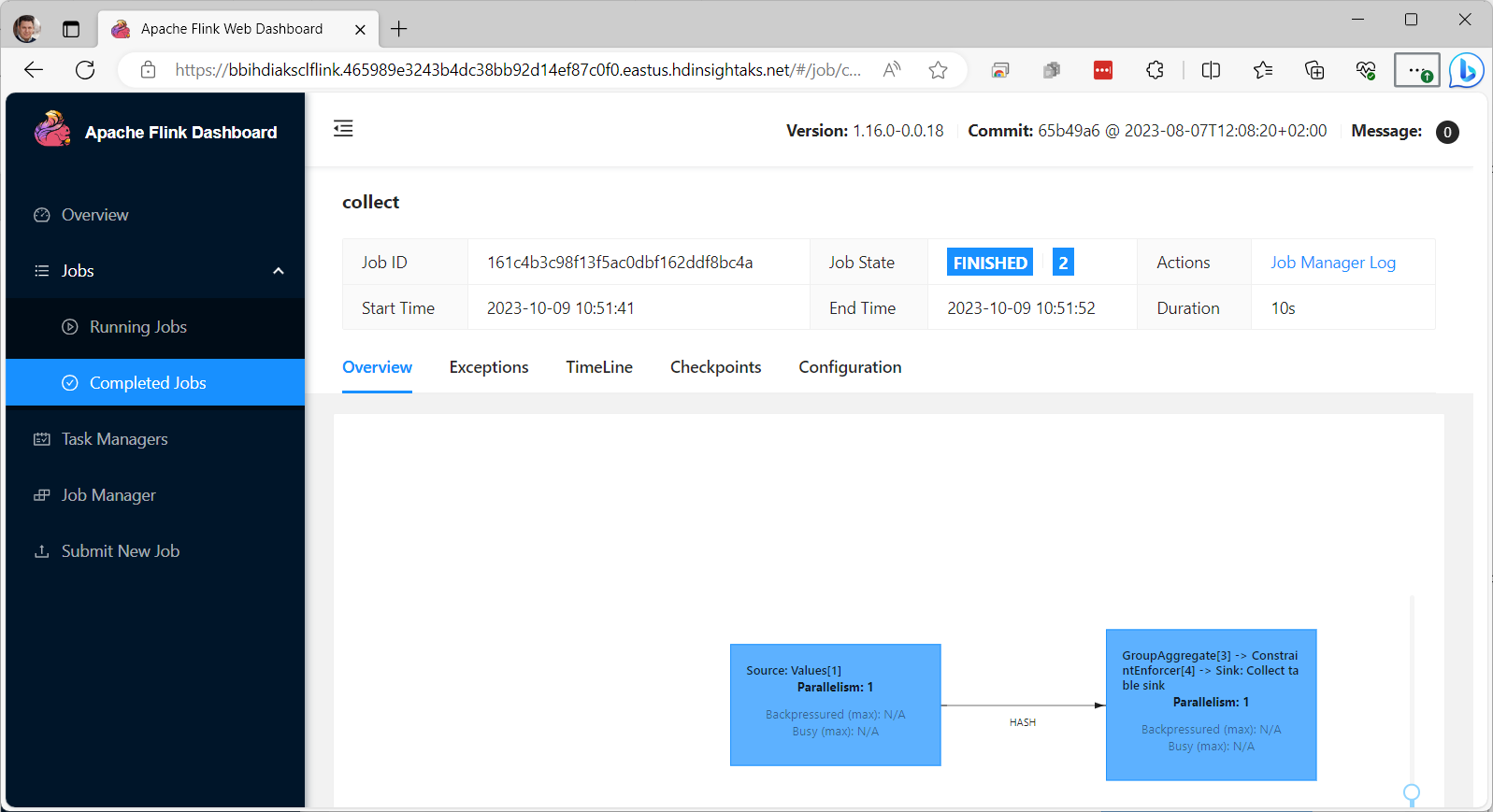
Um painel do Flink mostrando os detalhes de um trabalho de consulta SQL concluído. Este painel pode ser acessado diretamente na página Visão geral do cluster Flink no portal do Azure.
Esta é uma experiência muito diferente de trabalhar com o Azure Synapse ou o Microsoft Fabric, cada um com sua própria interface de usuário baseada na Web, e cada um deles também pode ser acessado a partir de ferramentas populares do ecossistema da Microsoft, como SQL Server Management Studio, Azure Data Studio e Código do Visual Studio. As equipes de análise que não querem mexer com a TI preferirão essa abordagem. As equipes de TI que não trabalham com análises, mas desejam gerenciar serviços para aqueles que o fazem, podem preferir ter menos camadas entre elas e o software.
Stick Shift ou Automático?
Da mesma forma, os próprios serviços HDI e Fabric — mesmo que tenham amplas capacidades e certas tecnologias em comum — são muito diferentes. HDI on AKS é uma oferta de plataforma como serviço (PaaS) que fornece controle muito refinado sobre cada um de seus componentes, para clientes que desejam esse controle e possuem o talento e os conjuntos de habilidades necessários para gerenciá-lo. Esses são os clientes que podem executar o mesmo software completamente por conta própria, mas desejam fazê-lo na nuvem e não precisam se preocupar com o hardware ou a infraestrutura da máquina virtual, ou com o cuidado e a alimentação dos pods e clusters subjacentes do Kubernetes. e nós. Enquanto isso, o Fabric é uma oferta de software como serviço (SaaS), baseada em um modelo unificado de capacidade de computação e que fornece uma interface de usuário e uma camada de abstração sobre as tecnologias subjacentes. Os recursos são provisionados e desprovisionados de forma automática e elástica, sem que o cliente precise microgerenciar esses detalhes. É um serviço muito mais completo que permite aos clientes concentrarem-se nos requisitos de negócio aos quais a tecnologia está a ser aplicada, em vez de na gestão e configuração da infra-estrutura. Delegar essa responsabilidade ao serviço será uma grande comodidade para alguns clientes, mas pode ser um obstáculo ou impedimento para outros. É por isso que faz sentido oferecer ambos os serviços, já que a Microsoft pode acomodar a variedade de preferências dos clientes, talentos internos e abordagem ao gerenciamento de custos da nuvem. Alguns desejarão uma plataforma refinada e de alta engenharia, enquanto outros preferirão a capacidade de trabalhar com tecnologias de análise e dados de código aberto “commodities” e agregar seu próprio valor de engenharia a elas.
Hands-on, com mangas arregaçadas
Quer trabalhar com Trino, Flink e/ou Spark? Se você estiver disposto a colocar a mão na massa e ler alguma documentação para chegar à curva de aprendizado, o HDI no AKS é uma ótima maneira de realizar seu trabalho analítico. Embora eu tivesse algum suporte direto da equipe de produto, consegui trabalhar de forma produtiva com o HDI no AKS, enquanto o serviço ainda estava em versão prévia privada e a documentação ainda era bastante austera. (Ambas as capturas de tela nesta postagem vieram de meu próprio trabalho com o serviço.) Se eu posso fazer isso, qualquer bom engenheiro de dados ou profissional de análise com experiência em serviços de nuvem também pode. E com o HDI no AKS agora em versão prévia, faz sentido que esses usuários dêem uma olhada, testem-no e considerem como ele pode se encaixar com o restante dos componentes e ferramentas modernas da pilha de dados de sua organização. Os clientes que gostariam de experimentar o HDI no AKS podem criar um novo cluster em https://aka.ms/starthdionaks e ler a documentação em https://aka.ms/hdionaks-docs. Os pré-requisitos de assinatura e as etapas de configuração únicas podem ser encontrados em https://learn.microsoft.com/azure/hdinsight-aks/prerequisites-subscription.
A postagem Microsoft renova o HDInsight, seu robusto serviço de Big Data apareceu pela primeira vez em The New Stack.


{kind=link}
{kind=link}
{kind=link}