
A startup de redação automatizada de propostas AutogenAI arrecada US$ 39,5 milhões
15 de janeiro de 2024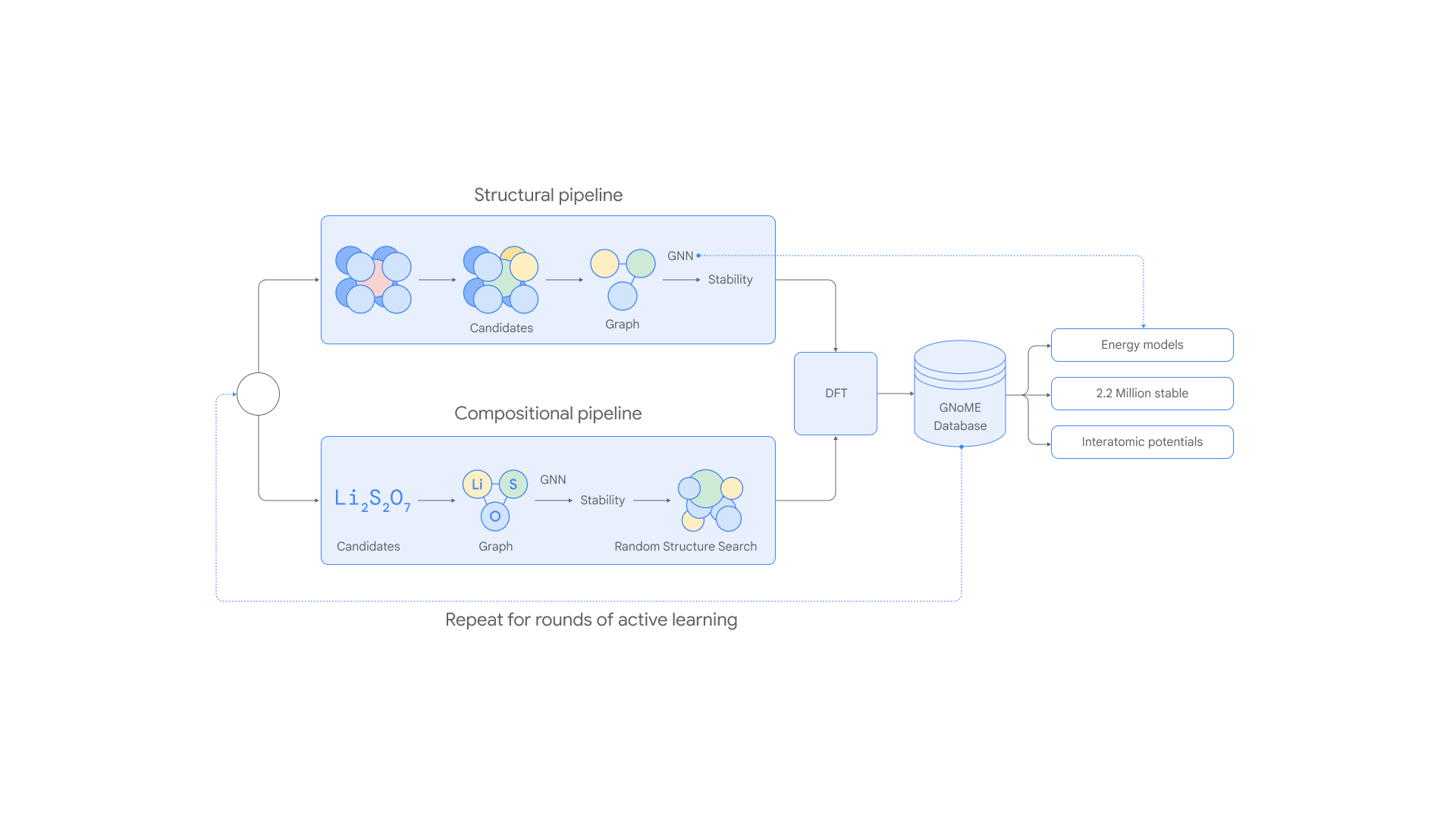
A IA de material do Google DeepMind já descobriu 2,2 milhões de novos cristais
16 de janeiro de 2024
Nos últimos anos, modelos de grande difusão, como DALL-E 2 e Stable Diffusion, ganharam reconhecimento por sua capacidade de gerar imagens fotorrealistas de alta qualidade e por sua capacidade de realizar diversas tarefas de síntese e edição de imagens.
Mas surgem preocupações sobre a potencial utilização indevida de modelos de IA generativos de fácil utilização, que podem permitir a criação de conteúdos digitais inadequados ou prejudiciais. Por exemplo, atores mal-intencionados podem explorar fotos de indivíduos compartilhadas publicamente, utilizando um modelo de difusão pronto para uso para editá-las com intenções prejudiciais.
Para enfrentar os crescentes desafios que cercam a manipulação não autorizada de imagens, pesquisadores do Laboratório de Ciência da Computação e Inteligência Artificial do MIT (CSAIL) introduziram o “PhotoGuard”, uma ferramenta de IA projetada para combater modelos avançados de IA de geração, como DALL-E e Midjourney.
Fortificando imagens antes de enviar
No artigo de pesquisa “Aumentando o custo da edição maliciosa de imagens com tecnologia de IA”, os pesquisadores afirmam que o PhotoGuard pode detectar “perturbações” imperceptíveis (perturbações ou irregularidades) nos valores dos pixels, que são invisíveis ao olho humano, mas detectáveis por modelos de computador.
“Nossa ferramenta visa ‘fortalecer’ as imagens antes de carregá-las na Internet, garantindo resistência contra tentativas de manipulação alimentadas por IA”, disse Hadi Salman, estudante de doutorado do MIT CSAIL e principal autor do artigo, ao VentureBeat. “Em nosso documento de prova de conceito, nos concentramos na manipulação usando a classe mais popular de modelos de IA atualmente empregados para alteração de imagens. Essa resiliência é estabelecida pela incorporação de perturbações imperceptíveis e sutilmente elaboradas nos pixels da imagem a ser protegida. Essas perturbações são criadas para interromper o funcionamento do modelo de IA que conduz a tentativa de manipulação.”
De acordo com pesquisadores do MIT CSAIL, a IA emprega dois métodos distintos de “ataque” para criar perturbações: codificador e difusão.
O ataque do “codificador” concentra-se na representação latente da imagem dentro do modelo de IA, fazendo com que o modelo perceba a imagem como aleatória e tornando a manipulação da imagem quase impossível. Da mesma forma, o ataque de “difusão” é uma abordagem mais sofisticada e envolve a determinação de uma imagem alvo e a otimização de perturbações para fazer com que a imagem gerada se assemelhe ao alvo.
Perturbações adversárias
Salman explicou que o principal mecanismo empregado em sua IA são as “perturbações adversárias”.
“Tais perturbações são modificações imperceptíveis dos pixels da imagem que provaram ser excepcionalmente eficazes na manipulação do comportamento de modelos de aprendizado de máquina”, disse ele. “O PhotoGuard usa essas perturbações para manipular o modelo de IA que processa a imagem protegida para produzir edições irrealistas ou sem sentido.”
Uma equipe de estudantes de pós-graduação e autores principais do MIT CSAIL – incluindo Alaa Khaddaj, Guillaume Leclerc e Andrew Ilyas – contribuiu para o artigo de pesquisa ao lado de Salman.
O trabalho também foi apresentado na Conferência Internacional sobre Aprendizado de Máquina em julho e foi parcialmente apoiado por doações da National Science Foundation na Open Philanthropy and Defense Advanced Research Projects Agency.
Usando IA como defesa contra manipulação de imagens baseada em IA
Salman disse que embora modelos generativos alimentados por IA, como DALL-E e Midjourney, tenham ganhado destaque devido à sua capacidade de criar imagens hiper-realistas a partir de descrições de texto simples, os riscos crescentes de uso indevido também se tornaram evidentes.
Esses modelos permitem aos usuários gerar imagens altamente detalhadas e realistas, abrindo possibilidades para aplicações inocentes e maliciosas.
Salman alertou que a manipulação fraudulenta de imagens pode influenciar as tendências do mercado e o sentimento público, além de representar riscos para as imagens pessoais. Imagens alteradas de forma inadequada podem ser exploradas para chantagem, levando a implicações financeiras substanciais em maior escala.
Embora a marca d’água tenha se mostrado uma solução promissora, Salman enfatizou que a necessidade de uma medida preventiva para prevenir proativamente o uso indevido continua crítica.
“Em alto nível, pode-se pensar nesta abordagem como uma ‘imunização’ que reduz o risco de essas imagens serem manipuladas maliciosamente usando IA – uma estratégia que pode ser considerada uma estratégia complementar às técnicas de detecção ou marca d’água”, explicou Salman. “É importante ressaltar que estas últimas técnicas são projetadas para identificar imagens falsificadas, uma vez que já tenham sido criadas. No entanto, o PhotoGuard visa evitar tal alteração para começar.”
Mudanças imperceptíveis para os humanos
O PhotoGuard altera os pixels selecionados em uma imagem para permitir que a IA entenda a imagem, explicou ele.
Os modelos de IA percebem as imagens como pontos de dados matemáticos complexos que representam a cor e a posição de cada pixel. Ao introduzir alterações imperceptíveis nesta representação matemática, o PhotoGuard garante que a imagem permaneça visualmente inalterada para os observadores humanos, ao mesmo tempo que a protege de manipulação não autorizada por modelos de IA.
O método de ataque do “codificador” introduz esses artefatos visando a representação latente da imagem alvo do modelo algorítmico – a descrição matemática complexa da posição e cor de cada pixel na imagem. Como resultado, a IA fica essencialmente impedida de compreender o conteúdo.
Por outro lado, o método de ataque de “difusão” mais avançado e computacionalmente intensivo disfarça uma imagem como diferente aos olhos da IA. Ele identifica uma imagem alvo e otimiza suas perturbações para se assemelhar ao alvo. Consequentemente, quaisquer edições que a IA tente aplicar a essas imagens “imunizadas” serão aplicadas erroneamente às imagens “alvo” falsas, gerando imagens de aparência irreal.
“O objetivo é enganar todo o processo de edição, garantindo que a edição final divirja significativamente do resultado pretendido”, disse Salman. “Ao explorar o comportamento do modelo de difusão, este ataque leva a edições que podem ser marcadamente diferentes e potencialmente absurdas em comparação com as alterações pretendidas pelo usuário.”
Simplificando o ataque de difusão com menos etapas
A equipe de pesquisa do MIT CSAIL descobriu que simplificar o ataque de difusão com menos etapas aumenta sua praticidade, embora continue computacionalmente intensivo. Além disso, a equipe disse que está integrando perturbações robustas adicionais para reforçar a proteção do modelo de IA contra manipulações comuns de imagens.
Embora os investigadores reconheçam a promessa do PhotoGuard, também alertaram que não é uma solução infalível. Indivíduos mal-intencionados podem tentar fazer engenharia reversa de medidas de proteção aplicando ruído, cortando ou girando a imagem.
Como uma demonstração de prova de conceito de pesquisa, o modelo de IA não está pronto para implantação no momento, e a equipe de pesquisa desaconselha seu uso para imunizar fotos neste estágio.
“Tornar o PhotoGuard uma ferramenta totalmente eficaz e robusta exigiria o desenvolvimento de versões do nosso modelo de IA adaptados a modelos específicos de geração de IA que estão presentes agora e surgiriam no futuro”, disse Salman. “Isso, é claro, exigiria a cooperação dos desenvolvedores destes modelos, e garantir uma cooperação tão ampla poderia exigir alguma ação política.”
A missão da VentureBeat é ser uma praça digital para os tomadores de decisões técnicas obterem conhecimento sobre tecnologia empresarial transformadora e realizarem transações. Conheça nossos Briefings.



{kind=link}
{kind=link}
{kind=link}