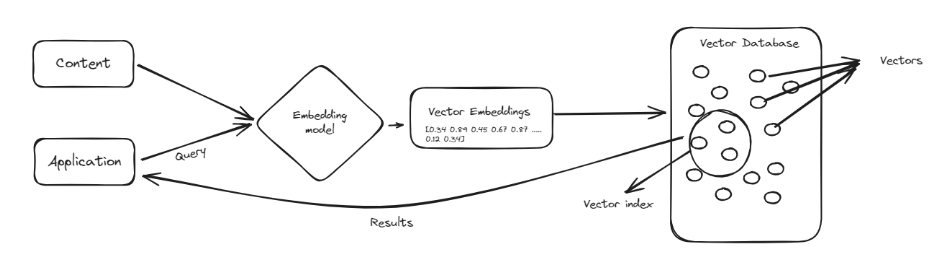
Com o surgimento da IA, os bancos de dados vetoriais ganharam atenção significativa devido à sua capacidade de armazenar, gerenciar e recuperar com eficiência dados em grande escala e de alta dimensão. Esta capacidade é crucial para aplicações de IA e IA generativa (GenAI) que lidam com dados não estruturados, como texto, imagens e vídeos.
A principal lógica por trás de um banco de dados vetorial é fornecer recursos de pesquisa por similaridade, em vez de pesquisa por palavras-chave, como os bancos de dados tradicionais fornecem. Este conceito foi amplamente adotado para impulsionar o desempenho de grandes modelos de linguagem (LLMs), principalmente após o lançamento do ChatGPT.
O maior problema dos LLMs é que eles exigem recursos, tempo e dados substanciais para o ajuste fino. O que torna muito difícil mantê-los atualizados. É por isso que quando você consulta LLMs sobre eventos recentes, eles geralmente fornecem respostas factualmente incorretas, sem sentido ou desconectadas do prompt de entrada, levando a “alucinações”.
Uma solução é a geração aumentada de recuperação (RAG), que amplia um LLM integrando informações atualizadas recuperadas de uma base de conhecimento externa. Bancos de dados vetoriais especializados são projetados para lidar com dados vetorizados de forma eficiente e fornecer recursos robustos de pesquisa semântica. Esses bancos de dados são otimizados para armazenar e recuperar vetores de alta dimensão, muito importantes para fazer buscas por similaridade. A velocidade e a eficiência dos bancos de dados vetoriais os tornaram parte integrante dos sistemas RAG.
O entusiasmo em torno dos bancos de dados vetoriais levou muitas pessoas a sugerir que os bancos de dados tradicionais poderiam ser substituídos por bancos de dados vetoriais. Em vez de armazenar dados em bancos de dados tradicionais (SQL ou NoSQL), você poderia armazenar todo o conjunto de dados de uma organização em um banco de dados vetorial e recuperá-los usando linguagem natural em vez de escrever consultas manuais?
Mas os bancos de dados vetoriais não funcionam como os bancos de dados tradicionais. Como escreveu Andrey Vasnetsov, CTO da Qdrant, “a maioria dos bancos de dados vetoriais não são bancos de dados nesse sentido. É mais correto chamá-los de motores de busca.” Isso ocorre porque seu objetivo principal é fornecer funcionalidades de pesquisa otimizadas e não foram projetados para oferecer suporte a recursos básicos, como pesquisa por palavra-chave ou consultas SQL.
Limitações de bancos de dados de vetores especializados
À medida que os casos de uso cresceram e as pessoas se concentraram na escalabilidade das suas aplicações, as limitações dos bancos de dados vetoriais tornaram-se mais visíveis. Os desenvolvedores logo perceberam que ainda precisavam dos recursos de um mecanismo de pesquisa de texto completo junto com a pesquisa vetorial. Por exemplo, filtrar resultados de pesquisa com base em critérios específicos é muito difícil em bancos de dados vetoriais. Esses bancos de dados também carecem de correspondências diretas para frases exatas, que são cruciais para muitas tarefas.
Suporte limitado para consultas complexas
Consultas complexas geralmente envolvem múltiplas condições, junções e agregações, o que as torna um desafio para bancos de dados de vetores especializados. Esses bancos de dados fornecem suporte limitado para consultas complexas por meio de filtragem de metadados. No entanto, o armazenamento de metadados é muito limitado em bancos de dados vetoriais, o que restringe a capacidade dos usuários de realizar uma ampla gama de consultas complexas.
Por outro lado, os bancos de dados SQL são projetados para lidar com armazenamento e processamento extensivos, permitindo a execução eficiente de consultas complexas que envolvem múltiplas condições, junções e agregações. Isso torna os bancos de dados SQL muito mais versáteis e capazes quando se trata de lidar com tarefas complexas de recuperação e manipulação de dados.
Limitações de tipo de dados
Bancos de dados de vetores especializados também enfrentam limitações de tipo de dados. Eles são projetados para armazenar vetores e metadados mínimos, o que restringe sua flexibilidade. Esse foco em vetores significa que eles não podem lidar com a grande variedade de tipos de dados que os bancos de dados SQL podem, como inteiros, strings e datas, o que permite operações de dados mais complexas e variadas.
No geral, os bancos de dados de vetores especializados têm um foco muito restrito. Sua arquitetura é otimizada principalmente para pesquisa semântica, e não para necessidades mais amplas de gerenciamento de dados. Isso restringe sua funcionalidade para executar uma ampla gama de tarefas que são facilmente executadas por sistemas mais versáteis, como bancos de dados SQL. Além disso, sua incapacidade de armazenar e gerenciar diferentes tipos de dados além dos vetores os torna menos adequados para tarefas de banco de dados de uso geral. Os bancos de dados vetoriais funcionam bem para aplicações RAG, mas não são versáteis o suficiente para casos de uso mais amplos.
Desafios de integração
A integração de bancos de dados de vetores especializados em infraestruturas de TI existentes está repleta de desafios. Muitas vezes surgem problemas de compatibilidade devido às diferenças inerentes entre bancos de dados de vetores especializados e sistemas existentes, necessitando de transformação significativa de dados e potencial perda ou corrupção de dados. Garantir a interoperabilidade com sistemas legados e manter a consistência e integridade dos dados também são tarefas complexas. Além disso, o processo de integração requer conjuntos de competências especializadas, que podem não estar prontamente disponíveis numa organização, conduzindo a elevados custos de formação e a uma curva de aprendizagem acentuada.
Além disso, as implicações financeiras da integração são substanciais. Os custos incluem licenciamento de software, atualizações de hardware, treinamento de pessoal e manutenção contínua. Além disso, os aplicativos existentes podem precisar ser modificados ou reescritos para interagir com o banco de dados vetorial, o que é um processo caro e arriscado, com potencial para introduzir novos bugs ou problemas de desempenho. A necessidade de apoio contínuo e de atualizações da base de dados especializada de vetores também pode levar a compromissos financeiros a longo prazo.
O processamento de dados requer uma abordagem híbrida
As bases de um banco de dados vetorial especializado são o armazenamento e a pesquisa de vetores, principalmente para aplicações RAG. No entanto, os bancos de dados tradicionais também devem ser capazes de lidar com vetores, e a pesquisa vetorial é uma abordagem de processamento de consultas, e não uma base para uma nova forma de processamento de dados.
RAG é uma técnica popular de IA que se beneficia de bancos de dados vetoriais. Embora os bancos de dados vetoriais sejam ótimos para pesquisas semânticas e para lidar com dados de alta dimensão, seus recursos focados geralmente ignoram as necessidades operacionais e funcionais de uma organização. Isto pode limitar a sua utilização em aplicações mais amplas com diversos requisitos operacionais e funcionais.
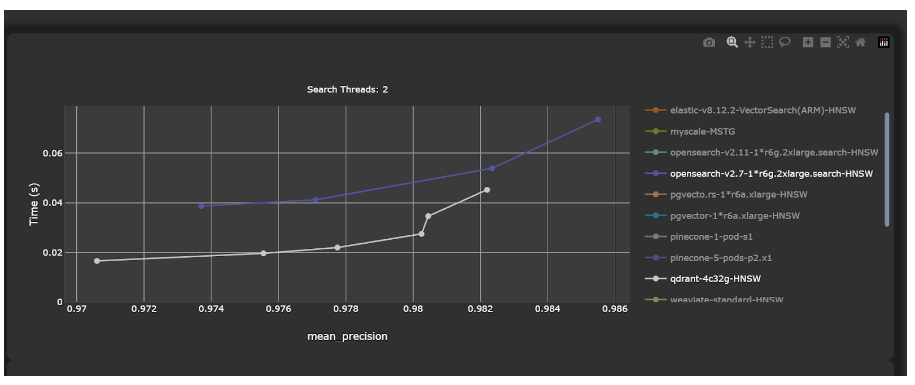
Da mesma forma, os bancos de dados tradicionais tentaram incorporar recursos de armazenamento e pesquisa de vetores para oferecer uma solução eficiente para processamento em larga escala de tipos de dados complexos. Por exemplo, PostgreSQL e Elasticsearch introduziram recursos de pesquisa vetorial. No entanto, seu desempenho de pesquisa vetorial não é tão bom e fica atrás de bancos de dados vetoriais especializados, como Pinecone e Qdrant. Por exemplo, o Qdrant atinge uma latência média de apenas 45,23 ms com uma taxa de precisão de 0,9822. Em comparação, embora robusto, o OpenSearch registra uma latência maior de 53,89ms e uma precisão um pouco menor de 0,9823. Benchmarks completos estão disponíveis no GitHub.
A arquitetura de bancos de dados vetoriais especializados é projetada especificamente para lidar com dados vetoriais de alta dimensão de forma eficiente, mas os bancos de dados tradicionais são construídos principalmente para dados relacionais e não suportam naturalmente as necessidades específicas de pesquisa vetorial.
Outra opção é adicionar extensões vetoriais ao seu banco de dados ou mecanismo de pesquisa atual. Essa abordagem atende diretamente às necessidades dos negócios, mesclando os pontos fortes e a flexibilidade dos bancos de dados tradicionais com os recursos avançados das pesquisas vetoriais modernas.
Um modelo híbrido pode se alinhar mais estreitamente com os diversos requisitos de manipulação de dados de uma empresa e simplificar sua infraestrutura de dados. Isso pode reduzir os custos operacionais e a complexidade, levando, em última análise, a uma solução mais escalável e eficiente que atenda às necessidades abrangentes de processamento de dados da organização.
Bancos de dados vetoriais SQL preenchem a lacuna
SQL tem sido a espinha dorsal de aplicações escaláveis há meio século, e sua integração com recursos de pesquisa vetorial está preparada para preencher a lacuna entre as necessidades de processamento de dados tradicionais e modernas. A integração do SQL com vetores melhorará a flexibilidade da modelagem de dados e facilitará o desenvolvimento. Isso permitirá que o sistema lide com consultas complexas envolvendo dados estruturados, dados vetoriais, pesquisas por palavras-chave e consultas unidas em várias tabelas.
Embora os bancos de dados vetoriais especializados sejam excelentes no tratamento de dados de alta dimensão com precisão e velocidade, a integração da pesquisa vetorial em bancos de dados SQL apresenta uma alternativa atraente. Oferece um equilíbrio entre a eficiência necessária para o processamento complexo de tipos de dados em escala e a conveniência de trabalhar dentro de uma estrutura familiar e amplamente adotada. Essa integração resolve muitos desafios enfrentados pelos bancos de dados vetoriais especializados, como iteração lenta, consultas ineficientes e altos custos de gerenciamento de um banco de dados separado. Ao adotar bancos de dados vetoriais SQL, as empresas podem aproveitar o poder da comprovada escalabilidade e confiabilidade do SQL, ao mesmo tempo em que obtêm os recursos avançados necessários para enfrentar os desafios multifacetados do processamento de dados moderno.
Conclusão
Depender inteiramente de um banco de dados vetorial especializado que processa apenas vetores limita a flexibilidade da sua estratégia de gerenciamento de dados. Um banco de dados vetorial multifuncional ou integrado oferece uma solução mais promissora.
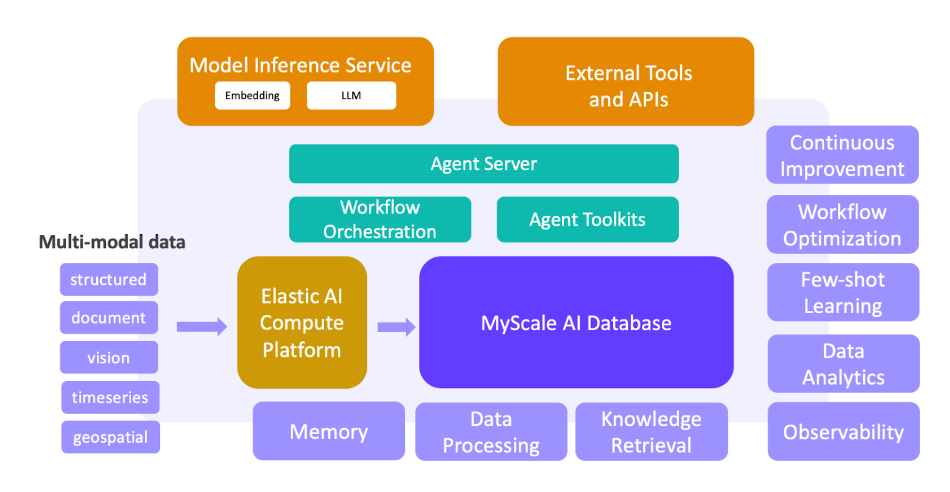
MyScaleDB, um banco de dados vetorial SQL de código aberto, não apenas gerencia vetores com eficiência, mas também funciona como um banco de dados tradicional, tornando-o adequado para uma ampla gama de aplicações.
Construído no ClickHouse, o MyScale combina os pontos fortes dos bancos de dados SQL tradicionais com os recursos dos bancos de dados vetoriais, armazenando e gerenciando com eficiência vetores de alta dimensão usando SQL para aplicativos GenAI. É também o primeiro banco de dados vetorial SQL a superar os bancos de dados vetoriais especializados em desempenho e custo-benefício, desmascarando o mito de que bancos de dados vetoriais integrados são inerentemente menos eficientes que os alternativos.
Ter um banco de dados que possa gerenciar dados tradicionais e vetoriais é crucial no mundo atual da tecnologia de IA. Essa abordagem garante escalabilidade, flexibilidade e economia, eliminando a necessidade de gerenciar vários sistemas. Ao optar por um banco de dados versátil, você pode preparar sua infraestrutura de dados para o futuro e atender aos crescentes requisitos dos aplicativos modernos.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Usama Jamil, defensor do desenvolvedor na MyScale, traz consigo uma vasta experiência e um profundo interesse em ciência de dados. Com paixão por explorar novas tendências no domínio de IA/ML, Usama se esforça para tornar conceitos complexos acessíveis a…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.







{kind=link}
{kind=link}
{kind=link}