
Não construa seu futuro em bancos de dados de vetores especializados
3 de junho de 2024
Snowflake Polaris visa interoperabilidade do mecanismo multiconsulta
4 de junho de 2024
Escrevi anteriormente sobre a moderna arquitetura de referência de data lake, abordando os desafios de cada empresa — mais dados, ferramentas antigas do Hadoop (especificamente HDFS) e maiores demandas por APIs RESTful (S3) e desempenho — mas quero preencher algumas lacunas.
O data lake moderno, às vezes chamado de data lakehouse, é metade data lake e metade data warehouse baseado em Open Table Format Specification (OTF). Ambos são baseados em armazenamento de objetos moderno.
Ao mesmo tempo, pensamos profundamente sobre como as organizações podem construir uma infraestrutura de dados de IA que possa dar suporte a todas as suas necessidades de IA/ML — não apenas o armazenamento bruto de seus conjuntos de treinamento, conjuntos de validação e conjuntos de testes. Em outras palavras, deve conter a computação necessária para treinar grandes modelos de linguagem, ferramentas MLOps, treinamento distribuído e muito mais.
Como resultado dessa linha de pensamento, elaboramos outro artigo sobre como usar a moderna arquitetura de referência de data lake para dar suporte às suas necessidades de IA/ML. O gráfico abaixo ilustra a arquitetura moderna de referência do data lake com destaque para os recursos necessários para IA generativa.
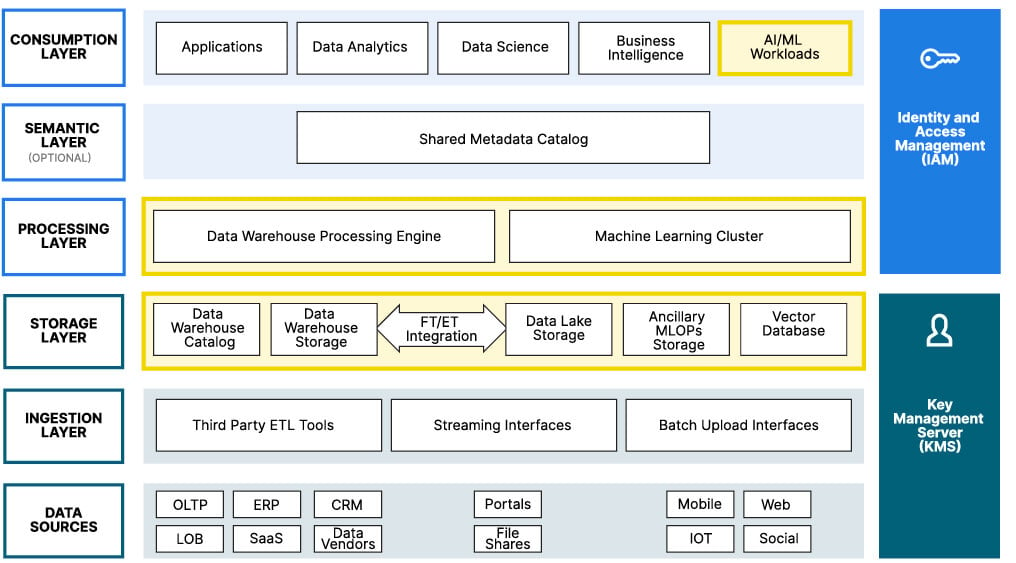
Fonte: AI/ML em um data lake moderno
Ambos os documentos não mencionam fornecedores ou ferramentas específicas. Agora quero discutir fornecedores e ferramentas necessárias para construir o data lake moderno. Nesta lista dos 10 primeiros, cada entrada é um recurso necessário para oferecer suporte à IA generativa.
1. Lago de dados
Os data lakes corporativos são baseados no armazenamento de objetos. Não o armazenamento de objetos antigo baseado em dispositivo que atendia a casos de uso de arquivamento profundo e barato, mas armazenamentos de objetos modernos, de alto desempenho, definidos por software e nativos do Kubernetes, os pilares da pilha GenAI moderna. Eles estão disponíveis como serviço (AWS, Google Cloud Platform (GCP), Microsoft Azure) ou localmente ou híbrido/ambos, como MinIO.
Esses data lakes precisam suportar cargas de trabalho de streaming, devem ter criptografia altamente eficiente e codificação de eliminação, precisam armazenar metadados atomicamente com o objeto e suportar tecnologias como computação Lambda. Dado que essas alternativas modernas são nativas da nuvem, elas se integrarão com toda a pilha de outras tecnologias nativas da nuvem — desde firewalls até a observabilidade e o gerenciamento de usuários e acesso — imediatamente.
2. Armazém de dados baseado em OTF
O armazenamento de objetos também é a solução de armazenamento subjacente para um data warehouse baseado em OTF-B. Usar armazenamento de objetos para um data warehouse pode parecer estranho, mas um data warehouse construído dessa forma representa a próxima geração de data warehouses. Isso é possível graças às especificações OTF de autoria da Netflix, Uber e Databricks, que facilitam o emprego do armazenamento de objetos em um data warehouse.
Os OTFs — Apache Iceberg, Apache Hudi e Delta Lake — foram escritos porque não havia produtos no mercado que pudessem atender às necessidades de dados dos criadores. Essencialmente, o que todos eles fazem (de maneiras diferentes) é definir um data warehouse que pode ser construído sobre o armazenamento de objetos. O armazenamento de objetos fornece a combinação de capacidade escalável e alto desempenho que outras soluções de armazenamento não conseguem.
Por serem especificações modernas, elas possuem recursos avançados que os data warehouses antigos não possuem, como evolução de partição, evolução de esquema e ramificação de cópia zero.
Dois parceiros MinIO que podem executar seu data warehouse baseado em OTF sobre MinIO são Dremio e Starburst.
- Dremio Sonar (mecanismo de processamento de data warehouse)
- Dremio Arctic (catálogo de data warehouse)
- Lago de dados abertos | Starburst (catálogo e mecanismo de processamento)
3. Operações de aprendizado de máquina (MLOps)
MLOps está para o aprendizado de máquina assim como o DevOps está para o desenvolvimento de software tradicional. Ambos são um conjunto de práticas e princípios que visam melhorar a colaboração entre equipes de engenharia (Dev ou ML) e equipes de operações de TI (Ops). O objetivo é agilizar o ciclo de vida de desenvolvimento usando automação, desde o planejamento e desenvolvimento até a implantação e operações. Um dos principais benefícios dessas abordagens é a melhoria contínua.
As técnicas e recursos de MLOps estão em constante evolução. Você deseja uma ferramenta que seja apoiada por um player importante, garantindo que a ferramenta esteja em constante desenvolvimento e aprimoramento e que ofereça suporte de longo prazo. Cada uma dessas ferramentas usa MinIO nos bastidores para armazenar artefatos usados durante o ciclo de vida de um modelo.
- MLRun (Iguazio, adquirida pela McKinsey & Company)
- MLflow (databricks)
- Kubeflow (Google)
4. Estrutura de aprendizado de máquina
Sua estrutura de aprendizado de máquina é a biblioteca (geralmente para Python) que você usa para criar seus modelos e escrever o código que os treina. Essas bibliotecas são ricas em recursos, pois fornecem uma coleção de diferentes funções de perda, otimizadores, ferramentas de transformação de dados e camadas pré-construídas para redes neurais. O recurso mais importante que essas duas bibliotecas fornecem é um tensor. Tensores são arrays multidimensionais que podem ser movidos para a GPU. Eles também possuem diferenciação automática, que é usada durante o treinamento do modelo.
As duas estruturas de aprendizado de máquina mais populares atualmente são PyTorch (do Facebook) e Tensorflow (do Google).
- PyTorch
- TensorFlow
5. Treinamento Distribuído
O treinamento de modelo distribuído é o processo de treinamento simultâneo de modelos de aprendizado de máquina em vários dispositivos ou nós computacionais. Esta abordagem acelera o processo de treinamento, especialmente quando são necessários grandes conjuntos de dados para treinar modelos complexos.
No treinamento de modelo distribuído, o conjunto de dados é dividido em subconjuntos menores e cada subconjunto é processado por diferentes nós em paralelo. Esses nós podem ser máquinas individuais dentro de um cluster, processos individuais ou pods individuais dentro de um cluster Kubernetes. Eles podem ter acesso a GPUs. Cada nó processa independentemente seu subconjunto de dados e atualiza os parâmetros do modelo de acordo. As cinco bibliotecas abaixo isolam os desenvolvedores da maior parte da complexidade do treinamento distribuído. Você pode executá-los localmente se não tiver um cluster, mas precisará de um cluster para ver uma redução notável no tempo de treinamento.
- DeepSpeed (da Microsoft)
- Horovod (da Uber)
- Ray (de qualquer escala)
- Distribuidor Spark PyTorch (da Databricks)
- Distribuidor Spark TensorFlow (de Databricks)
6. Centro Modelo
Um hub de modelo não faz realmente parte da arquitetura moderna de referência de data lake, mas estou incluindo-o de qualquer maneira porque é importante para começar rapidamente com IA generativa. Hugging Face se tornou o lugar certo para grandes modelos de linguagem. Hugging Face hospeda um hub de modelos onde os engenheiros podem baixar modelos pré-treinados e compartilhar modelos que eles próprios criam. Hugging Face também é autor das bibliotecas Transformers e Datasets, que trabalham com grandes modelos de linguagem (LLMs) e os dados usados para treiná-los e ajustá-los.
Existem outros hubs modelo. Todos os principais fornecedores de nuvem têm alguma forma de fazer upload e compartilhar modelos, mas a Hugging Face, com sua coleção de modelos e bibliotecas, tornou-se líder nesse espaço.
- Abraçando o rosto
7. Estrutura de aplicação
Uma estrutura de aplicativo ajuda a incorporar um LLM em um aplicativo. Usar um LLM é diferente de usar uma API padrão. Muito trabalho deve ser feito para transformar uma solicitação do usuário em algo que o LLM possa compreender e processar. Por exemplo, se você criar um aplicativo de bate-papo e quiser usar o Retrieval Augmented Generation (RAG), será necessário tokenizar a solicitação, transformar os tokens em um vetor, integrar com um banco de dados vetorial (descrito abaixo), criar um prompt e ligue para seu LLM. Uma estrutura de aplicação para IA generativa permitirá encadear essas ações. T
A estrutura de aplicativos mais usada atualmente é LangChain. Integra-se com outras tecnologias, como a biblioteca Hugging Face Transformer e a biblioteca Unstructured para processamento de documentos. É rico em recursos e pode ser um pouco complicado de usar, então listamos abaixo algumas alternativas para quem não possui requisitos complexos e deseja algo mais simples que o LangChain.
- LangChain
- AgenteGPT
- Auto-GPT
- BebêAGI
- Fluir
- GradienteJ
- LhamaIndex
- Langdock
- TensorFlow (API Keras)
8. Processamento de Documentos
A maioria das organizações não possui um único repositório com documentos limpos e precisos. Em vez disso, os documentos são espalhados pela organização em vários portais de equipe em vários formatos. A primeira etapa ao se preparar para IA generativa é construir um pipeline que pegue apenas documentos que foram aprovados para uso com IA generativa e os coloque em seu banco de dados de vetores. Esta poderia ser potencialmente a tarefa mais difícil de uma solução de IA generativa para grandes organizações globais.
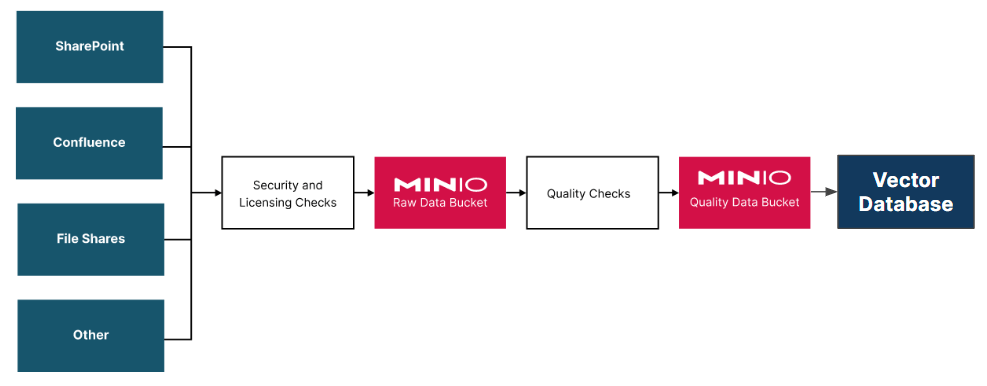
Um pipeline de documentos deve converter os documentos em texto, fragmentar o documento e executar o texto fragmentado por meio de um modelo de incorporação para que sua representação vetorial possa ser salva em um banco de dados vetorial. Felizmente, algumas bibliotecas de código aberto podem fazer isso para muitos dos formatos de documentos comuns. Algumas bibliotecas estão listadas abaixo. Essas bibliotecas poderiam ser usadas com LangChain para construir um pipeline completo de processamento de documentos.
- Não estruturado
- Análise aberta
9. Bancos de dados de vetores
Bancos de dados vetoriais facilitam a pesquisa semântica. Compreender como isso é feito requer muita base matemática e é complicado. No entanto, a pesquisa semântica é conceitualmente fácil de entender. Digamos que você queira encontrar todos os documentos que discutam qualquer coisa relacionada à “inteligência artificial”. Para fazer isso em um banco de dados convencional, você precisaria pesquisar todas as abreviações, sinônimos e termos relacionados possíveis de “inteligência artificial”. Sua consulta seria mais ou menos assim:
Essa busca manual por similaridade não é apenas árdua e propensa a erros, mas a busca em si é muito lenta. Um banco de dados vetorial pode receber uma solicitação como abaixo e executar a consulta com mais rapidez e precisão. A capacidade de executar consultas semânticas com rapidez e precisão é importante se você deseja usar a Geração Aumentada de Recuperação.
Quatro bancos de dados de vetores populares estão listados abaixo.
- Milvus
- Pgvector
- Pinha
- Tecer
10. Exploração e visualização de dados
É sempre uma boa ideia ter ferramentas que permitam organizar seus dados e visualizá-los de diferentes maneiras. As bibliotecas Python listadas abaixo fornecem recursos de manipulação e visualização de dados. Estas podem parecer ferramentas que você só precisa para IA tradicional, mas também são úteis para IA generativa. Por exemplo, se você estiver fazendo análise de sentimentos ou detecção de emoções, verifique seus conjuntos de treinamento, validação e teste para garantir uma distribuição adequada em todas as suas aulas.
- Pandas
- Matplotlib
- Nascido no mar
- Streamlit
Conclusão
Aí está: dez recursos que podem ser encontrados na moderna arquitetura de referência de data lake, junto com produtos e bibliotecas concretas de fornecedores para cada recurso. Abaixo está uma tabela que resume essas ferramentas.
Lago de dados |
MinIO, AWS, GCP, Azure |
Armazém de dados baseado em OTF |
DrêmioSonar DremioDremio ÁrticoExplosão estelarLago de dados abertos | Explosão estelar |
Estrutura de aprendizado de máquina |
PyTorchTensorFlow |
Operações de aprendizado de máquina |
MLRun (McKinsey & Company)MLflow (databricks)Kubeflow (Google) |
Treinamento distribuído |
DeepSpeed (da Microsoft)Horovod (da Uber)Ray (de qualquer escala)Distribuidor Spark PyTorch (da Databricks)Distribuidor Spark Tensoflow (da Databricks) |
Centro de modelo |
Abraçando o rosto |
Estrutura do aplicativo |
LangChainAgenteGPTAuto-GPTBebêAGIFluirGradienteJLhamaIndexLangdockTensorFlow (API Keras) |
Processamento de documentos |
Não estruturadoAnálise aberta |
Banco de dados de vetores |
MilvusPgvectorPinhaTecer |
Exploração e visualização de dados |
PandasMatplotlibNascido no marStreamlit |
A postagem Guia do arquiteto para o GenAI Tech Stack – 10 ferramentas apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}
{kind=link}