
Como e por que você deve usar conversão de tipo em Python
17 de maio de 2024
PaaS da Rafay agora oferece suporte a cargas de trabalho de GPU para IA/ML na nuvem
17 de maio de 2024
Para equipes de DevOps e de plataforma que trabalham com contêineres e Kubernetes, reduzir o tempo de inatividade e melhorar a postura de segurança é crucial. Uma compreensão clara da topologia de rede, das interações de serviço e das dependências de carga de trabalho é necessária em aplicativos nativos da nuvem. Isso é essencial para proteger e otimizar a implantação do Kubernetes e minimizar o tempo de resposta em caso de falha.
A observabilidade da rede pode destacar lacunas nas políticas de rede para aplicações que exigem controles de políticas de rede, reduzindo assim o risco de ataque por acesso de saída não seguro ou movimento lateral de ameaças dentro do cluster Kubernetes. No entanto, visualizar a comunicação da carga de trabalho, as dependências de serviço e as políticas de segurança de rede ativas e inativas apresenta desafios significativos devido à natureza distribuída e dinâmica das cargas de trabalho do Kubernetes.
A observabilidade da rede é difícil com cargas de trabalho K8s
O Kubernetes aumenta e expande pods e cria e destrói serviços dependendo dos requisitos de negócios em tempo real, resultando em conexões de rede dinâmicas para cada instância de carga de trabalho. As políticas de acesso à rede definidas para cada carga de trabalho afetam ainda mais essas conexões.
Nesses cenários, é difícil capturar uma representação precisa e atualizada do tráfego de rede, das dependências de serviço e das políticas de rede. A implementação padrão do Kubernetes fornece visibilidade limitada do tráfego de rede e informações sobre políticas, tornando um desafio para as equipes solucionar problemas de conectividade, melhorar a segurança e demonstrar conformidade.
Limitações das ferramentas de observabilidade de uso geral
As equipes de DevOps e de plataforma geralmente contam com ferramentas de observabilidade de uso geral para obter visibilidade da comunicação da carga de trabalho e das políticas de rede.
Observabilidade de rede para comunicação segura
Em termos de segurança, as equipes de DevOps e de plataforma geralmente relatam que as soluções de observabilidade de uso geral não monitoram efetivamente as comunicações entre cargas de trabalho e dentro ou fora do cluster.
A rede e as políticas de segurança do Kubernetes determinam o acesso no cluster. O mapeamento em tempo real dessas políticas para o fluxo de tráfego no cluster Kubernetes é fundamental para compreender o comportamento de uma implantação.
Devido à natureza dinâmica e efêmera do Kubernetes, as ferramentas de monitoramento tradicionais são incapazes de mapear políticas e fluxos que possam ser dimensionados com a aplicação. Isto leva a desafios no desenvolvimento, implementação e validação de políticas de rede eficazes durante o tempo de execução.
Agregação e Correlação de Dados
O Kubernetes cria um grande número de objetos efêmeros que geram dados em um ambiente distribuído. Esses dados precisam ser agregados e correlacionados para visualizar as interações e atividades no ambiente. Além disso, o contexto do Kubernetes, como pods, serviços e namespaces, deve ser adicionado aos dados, o que requer tempo e recursos como computação, memória e armazenamento extras.
Contexto do Kubernetes
Kubernetes adiciona uma camada de abstração sobre hosts e VMs. Embora seja importante coletar e agregar dados de contêineres e hosts individuais, os dados devem ser correlacionados e agregados em diferentes níveis de abstrações do Kubernetes.
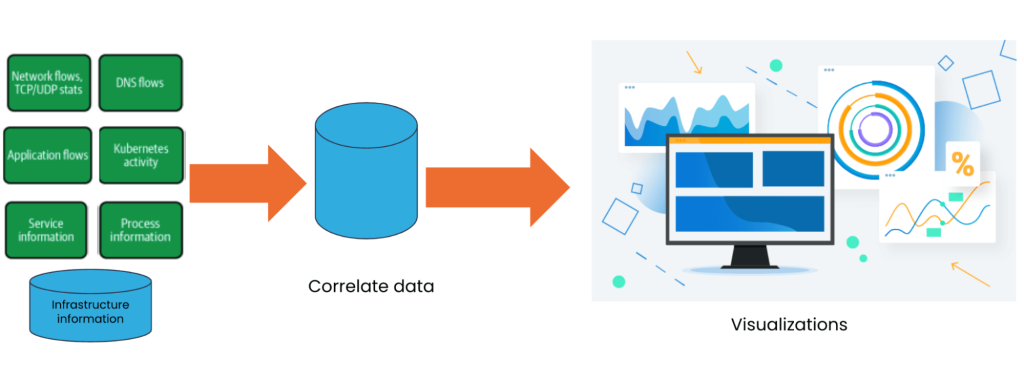
A maioria das ferramentas de observabilidade de uso geral exportam dados de clusters Kubernetes e usam extensos recursos de computação para agregar e correlacionar esses dados. Isso é caro e tem funcionalidade limitada. Para a observabilidade da rede Kubernetes, é fundamental que as ferramentas de observabilidade sejam nativas do Kubernetes e operem dentro do cluster.
Observabilidade da rede nativa do Kubernetes
A configuração padrão do Kubernetes fornece insights restritos sobre visibilidade e informações de política, muitas vezes exigindo que os usuários compilem dados de várias fontes para obter uma visão abrangente.
Normalmente, seriam executados vários comandos kubectl para coletar informações isoladas na pilha do Kubernetes. Por exemplo, executando kubectl get pods ajuda a recuperar uma lista de todos os pods em execução em um cluster, enquanto kubectl get networkpolicies exibe todos os recursos NetworkPolicy definidos. Obter visibilidade do tráfego e das políticas usando comandos kubectl é notavelmente complicado e ineficiente em um ambiente Kubernetes distribuído.
Além disso, a visibilidade das métricas de infraestrutura, como fluxos de rede e logs de DNS, pode ser alcançada por meio de ferramentas de monitoramento de código aberto, como Prometheus e Grafana, que ajudam a rastrear dados criptografados e não criptografados.
As soluções de monitoramento de uso geral normalmente coletam métricas nos níveis de nó, contêiner ou pod, o que leva a silos de dados isolados. Esses silos exigem agregação e correlação complexas nos níveis de aplicativos e microsserviços para monitorar e solucionar com eficácia problemas como comportamento de aplicativos, gargalos de desempenho e problemas de comunicação. As equipes que utilizam esse método lutam com a escalabilidade devido à grande quantidade de dados granulares gerados e à natureza transitória das interações dentro da infraestrutura dinâmica do Kubernetes.
Para análises mais detalhadas, ferramentas de monitoramento de terceiros como Datadog, Dynatrace e Splunk são frequentemente usadas para coletar logs e métricas e para construir painéis abrangentes. Além disso, o uso de painéis pré-construídos fornecidos por provedores de serviços gerenciados pode oferecer uma maneira simplificada de rastrear e analisar dados estatísticos, facilitando uma melhor supervisão operacional e planejamento estratégico no ambiente Kubernetes.
Rede Kubernetes Oobservabilidade com Calico
O Calico Cloud fornece observabilidade e solução de problemas nativas do Kubernetes e específicas para ambientes Kubernetes, aprimorando a capacidade de resolver rapidamente problemas de conectividade, fortalecer posturas de segurança e compreender topologias de rede em tempo real.
Métricas de rede
O Calico reúne automaticamente logs de várias atividades dentro do cluster Kubernetes em toda a pilha, como fluxos DNS, fluxos de aplicativos, informações de microsserviços, atividades do Kubernetes, logs de auditoria, fluxos de rede, status TCP/UDP, estatísticas de soquete e informações de processo. Ele também registra dados sobre diversas políticas de rede aplicadas nos clusters, como políticas de nível de aplicativo, de rede e de DNS. O Calico combina esses pontos de dados na origem e, portanto, é enriquecido com metadados específicos do Kubernetes sem necessidade de qualquer configuração adicional, economizando tempo e esforço, bem como recursos como memória, computação e largura de banda de rede.
Visualizações
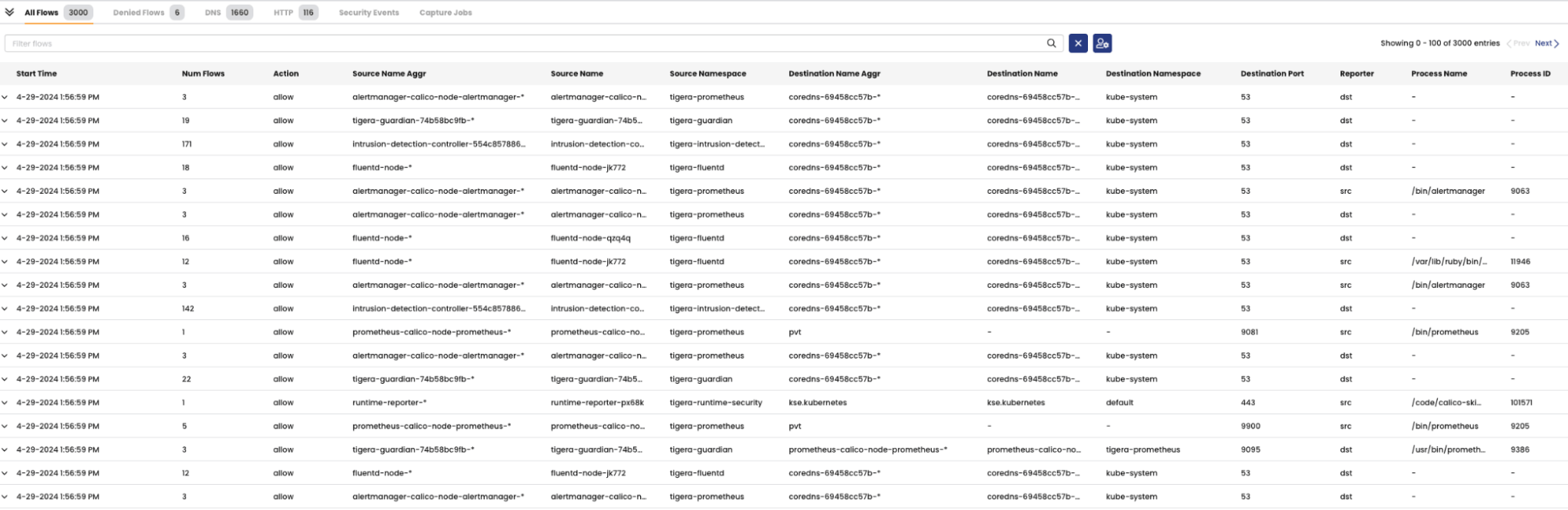
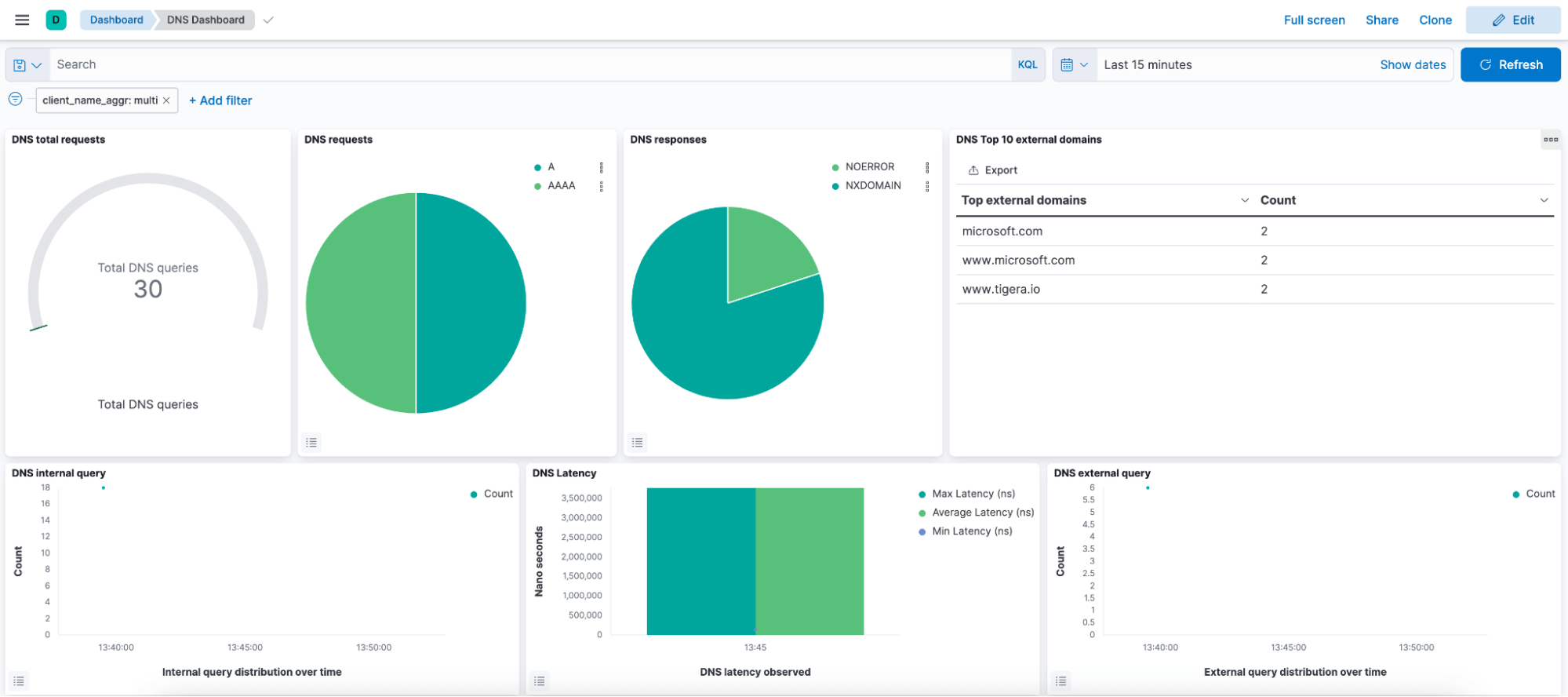
Calico Cloud oferece um painel detalhado para fácil monitoramento do fluxo de tráfego e políticas de rede e solução de problemas de rede e segurança de rede com Dynamic Service Threat Graph. Ele também fornece painéis personalizados, como o Painel DNS, para obter insights detalhados sobre rede e segurança de aplicativos. Além disso, o Calico oferece gerenciamento avançado de logs com filtragem automatizada e guias pré-construídas para agilizar a solução de problemas e realizar análises mais rápidas da causa raiz. O Calico fornece um processo direto para identificar cargas de trabalho problemáticas e acessar rapidamente logs relevantes, simplificando significativamente o processo de solução de problemas.
Para usuários que buscam análises mais profundas, como análise de DNS, a integração integrada do Calico com o Kibana permite a criação de consultas detalhadas e personalizadas, atendendo a necessidades mais avançadas.
Ferramentas de solução de problemas
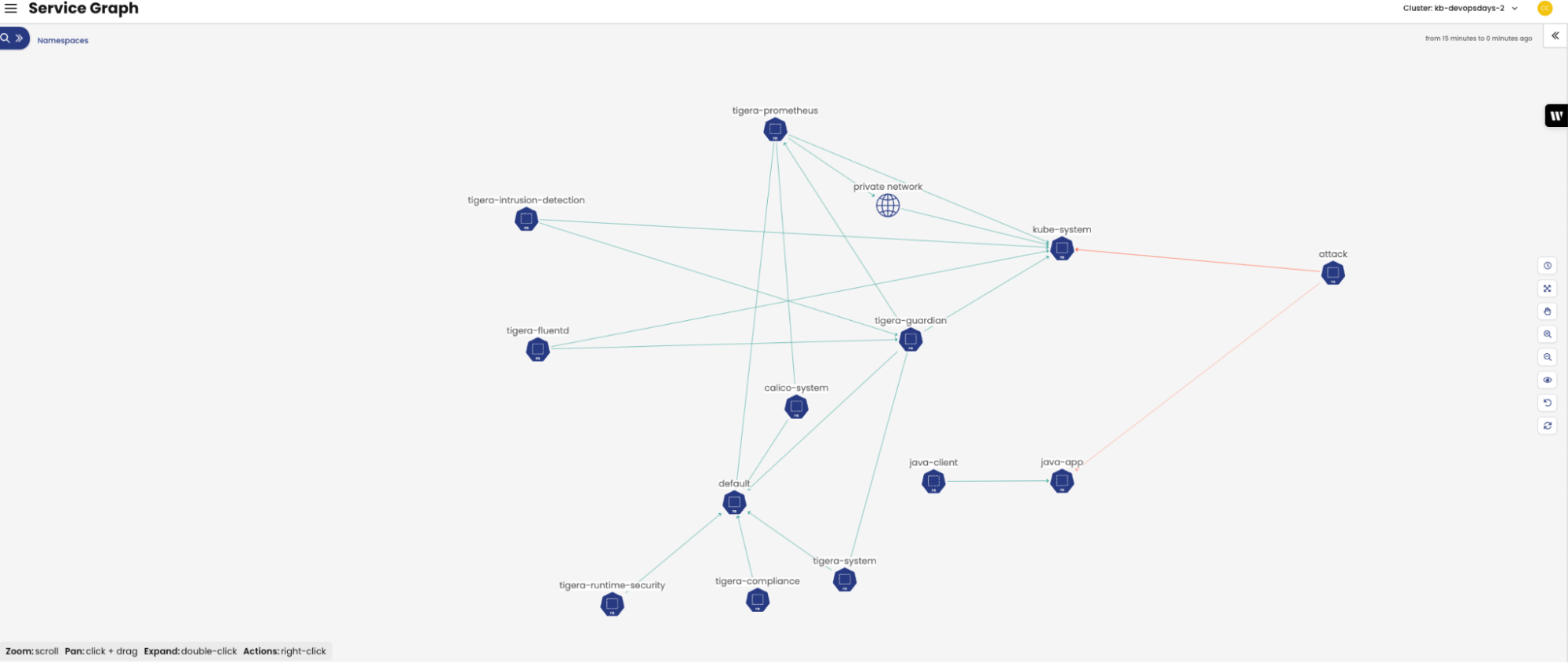
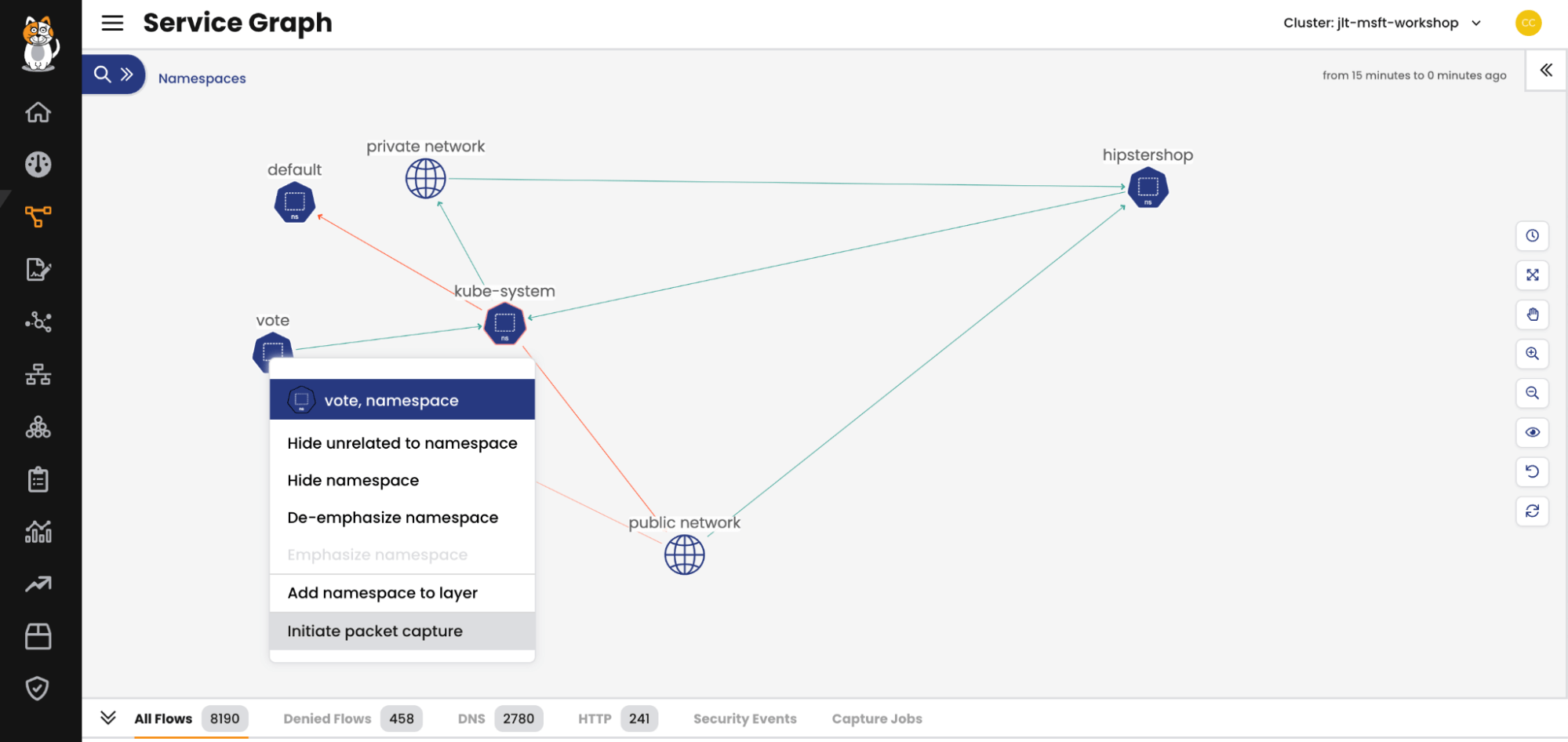
Calico fornece ferramentas para solucionar problemas de conectividade de rede. Considere um cenário em que os alertas do painel identificam uma falha de comunicação ou uma política que nega tráfego. Na figura abaixo, os engenheiros de DevOps e de plataforma podem solucionar o motivo pelo qual o pod “padrão” não está se comunicando com kube-system em apenas alguns cliques. Um usuário navega até o gráfico de serviço, clica com o botão direito no pod, permite a captura de pacotes com carimbos de data/hora e protocolos específicos e captura todo o tráfego para fazer a análise da causa raiz. Os dados capturados já estão agregados e correlacionados e apontam para configurações, dependências ou políticas específicas para análise. Ao selecionar as cargas de trabalho afetadas, o usuário pode ver imediatamente o que está causando o colapso da rede, incluindo as políticas de rede que estão causando o problema.
Benefícios de usar chita
- Solução de problemas mais rápida: Ao oferecer uma visão em tempo real do tráfego de aplicativos e dados correlacionados, o Calico permite que as equipes de DevOps reduzam rapidamente os esforços de solução de problemas, desde políticas de rede mal configuradas até problemas de desempenho de rede. Essa abordagem simplificada permite que as equipes resolvam com eficiência as lacunas de segurança e os problemas de comunicação da carga de trabalho, reduzindo assim o tempo de inatividade e aumentando a eficiência operacional.
- Postura de segurança aprimorada: As equipes de DevOps agora podem identificar falhas de segurança e resolver a falta de controles granulares de acesso à carga de trabalho usando o Calico. Com visualizações baseadas em atividades e metadados de tráfego detalhados, o Calico permite que as equipes visualizem e recomendem políticas antes da aplicação. Isso melhora a postura de segurança de um aplicativo e reduz riscos de maneira eficaz.
Conclusão
Calico capacita equipes de DevOps e de plataforma a obter observabilidade e solução de problemas eficiente para seus ambientes de contêiner e Kubernetes. Ao fornecer uma solução desenvolvida especificamente para atender às limitações das abordagens atuais, a Calico permite que as equipes reduzam o tempo de inatividade, melhorem a postura de segurança e aumentem a eficiência operacional. Com o Calico, as equipes de DevOps e de plataforma podem navegar com confiança pelas complexidades dos ambientes de contêiner e Kubernetes e impulsionar a inovação com tranquilidade.
A postagem Observabilidade de rede em clusters K8s para melhor solução de problemas apareceu pela primeira vez em The New Stack.


{kind=link}
{kind=link}
{kind=link}