

Jonathan Ellis é cofundador e CTO da DataStax. Ele atuou como presidente do projeto Apache Cassandra por seis anos.
Leia mais de Jonathan Ellis

Os índices vetoriais são o tópico mais quente nos bancos de dados porque a pesquisa vetorial do vizinho mais próximo aproximado (ANN) coloca o “R” em RAG (geração aumentada por recuperação). O “vizinho mais próximo” para modelos de incorporação de texto é quase sempre medido com a distância angular – por exemplo, o cosseno entre dois vetores. Obter a recuperação precisa e eficiente é um fator crítico para toda a aplicação; não conseguir encontrar o contexto relevante – ou demorar muito para encontrá-lo – deixará seu grande modelo de linguagem (LLM) sujeito a alucinações e seus usuários frustrados.
Todo índice RNA de uso geral é construído em uma estrutura gráfica. Isso ocorre porque os índices baseados em gráficos permitem atualizações incrementais, boa recuperação e consultas de baixa latência. (A única exceção foi o pgvector, que começou com um índice baseado em partição, mas seus criadores mudaram para uma abordagem gráfica o mais rápido que puderam porque a abordagem de particionamento era muito lenta.)
Visualização da busca pelos vizinhos mais próximos do vetor alvo vermelho em um índice gráfico, começando no ponto de entrada roxo.
A desvantagem bem conhecida dos índices gráficos é que eles consomem muita memória, porque todo o conjunto de vetores precisa residir na memória. Isso ocorre porque você precisa comparar seu vetor de consulta com os vizinhos de cada nó que encontrar à medida que expande sua pesquisa através do gráfico, e isso está muito próximo de uma distribuição uniformemente aleatória de vetores que estão sendo acessados. As suposições padrão do banco de dados de que 80% dos seus acessos serão a 20% dos seus dados não são válidas, portanto, o armazenamento em cache direto não ajudará a evitar um enorme consumo de memória.
Durante a maior parte de 2023, isso passou despercebido pela maioria das pessoas que usavam esses índices gráficos simplesmente porque a maioria dos usuários não estava lidando com conjuntos de dados grandes o suficiente para tornar isso um problema sério. Esse não é mais o caso; com conjuntos de dados vetorizados como todos os da Wikipédia sendo facilmente disponíveis, fica claro que a pesquisa vetorial na produção precisa de uma solução melhor do que lançar máquinas maiores para resolver o problema.
A Microsoft Research em 2019 propôs uma solução elegante para o problema de grandes índices vetoriais em “DiskANN: pesquisa rápida e precisa de bilhões de pontos do vizinho mais próximo em um único nó”. Em alto nível, a solução tem duas partes. Primeiro, comprima os vetores (com perdas) usando quantização de produto (PQ). Os vetores compactados são retidos na memória em vez dos originais de resolução total, reduzindo o consumo de memória e ao mesmo tempo acelerando a pesquisa.
JVector baseia-se nas ideias do DiskANN para fornecer pesquisa vetorial de última geração para aplicativos Java. Usei o driver JVector Bench para visualizar como o recall (precisão da pesquisa) se degrada ao pesquisar os 100 principais vizinhos em conjuntos de dados criados por diferentes modelos de incorporação em uma pequena amostra de artigos fragmentados da Wikipedia. (Os conjuntos de dados são construídos usando a ferramenta Neighborhood Watch de código aberto.) A precisão perfeita seria um recall de 1,0.
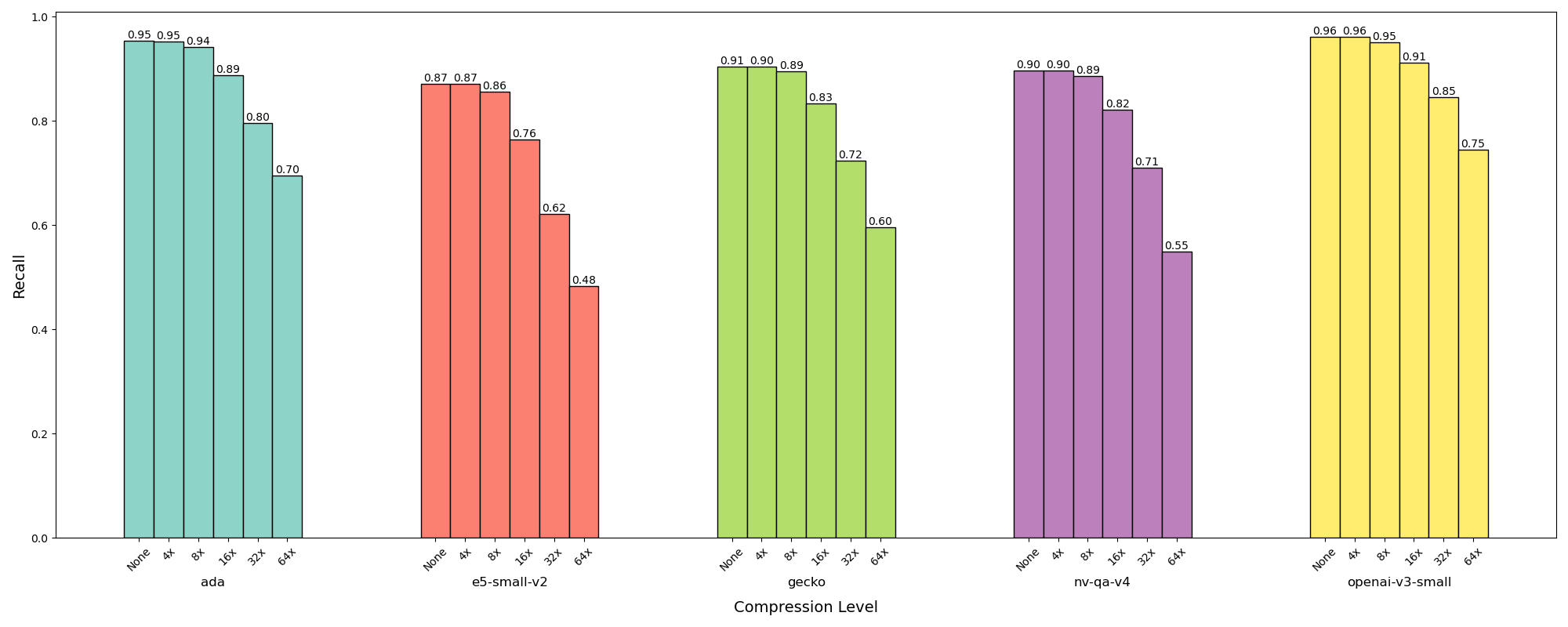
É claro que o recall sofre apenas um pouco na compressão 4x e 8x, mas cai rapidamente depois disso.
É aí que entra a segunda parte do DiskANN. Para obter uma compactação mais alta (que permite ajustar índices maiores na memória) enquanto compensa a precisão reduzida, o DiskANN consulta excessivamente (pesquisa mais profundamente no gráfico) e, em seguida, reclassifica os resultados usando os vetores de precisão total que são retidos no disco.
Veja como fica o recall quando adicionamos consultas excessivas de até 3x (como recuperar os 300 principais resultados usando a similaridade PQ na memória) e depois reclassificar para os 100 primeiros. conjunto de dados v3-pequeno:
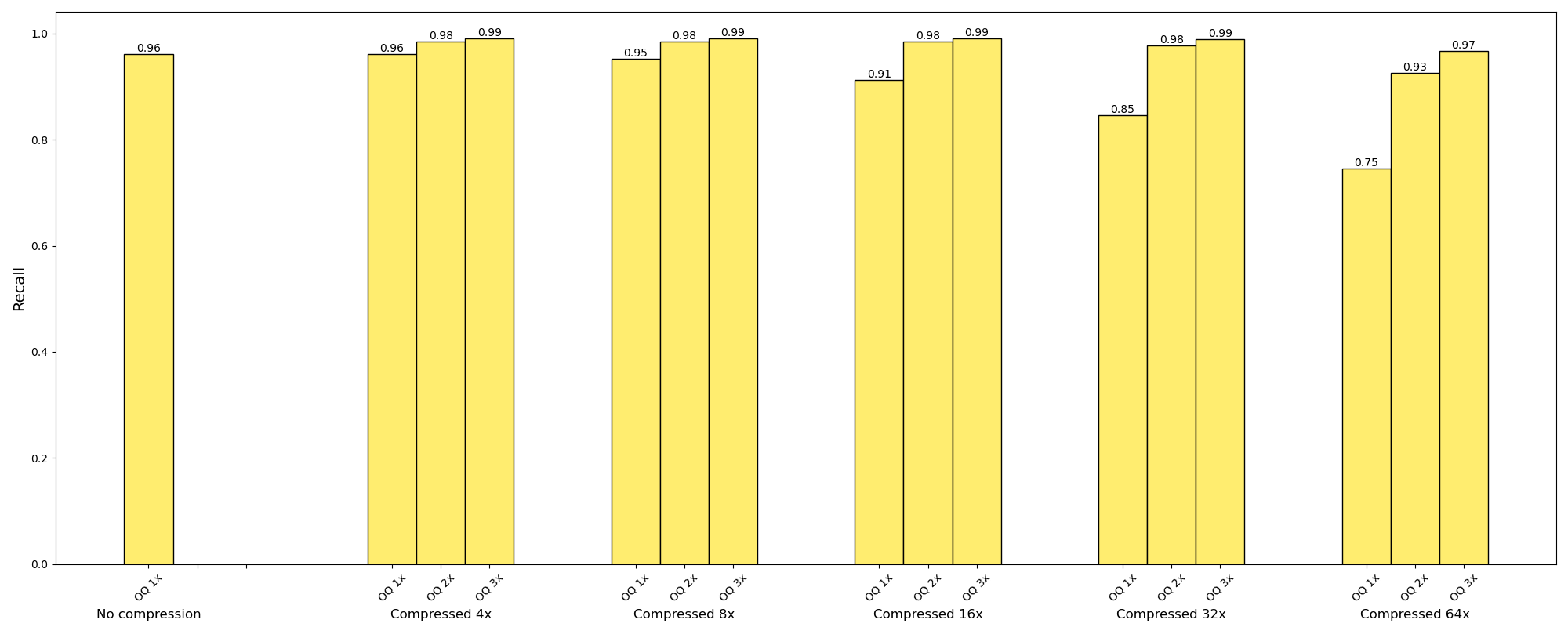
Com consulta excessiva de 3x (buscando os 300 principais resultados para uma consulta dos 100 principais usando os vetores compactados e, em seguida, reclassificando com resolução total), podemos compactar os vetores openai-v3-small em até 64x, mantendo ou excedendo a precisão original.
A reclassificação PQ + é como o JVector aproveita os pontos fortes da memória rápida e do disco barato para fornecer um índice híbrido que oferece o melhor dos dois mundos. Para tornar isso mais fácil de usar, o DataStax Astra DB simplifica isso para um único source_model configuração ao criar o índice – informe ao Astra DB de onde vêm seus embeddings e ele usará automaticamente as configurações ideais.
(Se você quiser se aprofundar em como funciona o PQ, Peggy Chang escreveu a melhor explicação do PQ que já vi – ou você pode sempre ir direto à fonte.)
A quantização binária (BQ) é uma abordagem alternativa à compressão vetorial, onde cada componente float32 é quantizado em 0 (se negativo) ou 1 (se positivo). Isso é extremamente prejudicial! Mas ainda é suficiente para fornecer resultados úteis para algumas fontes de incorporação se você fizer uma consulta excessiva de forma adequada, o que o torna potencialmente atraente porque calcular a similaridade BQ é muito rápido – essencialmente apenas a distância de Hamming, que pode ser calculada extremamente rapidamente usando SWAR (aqui está a implementação do OpenJDK do método principal). Esta é a aparência do recall do BQ com consulta excessiva de 1x a 4x nos mesmos cinco conjuntos de dados:
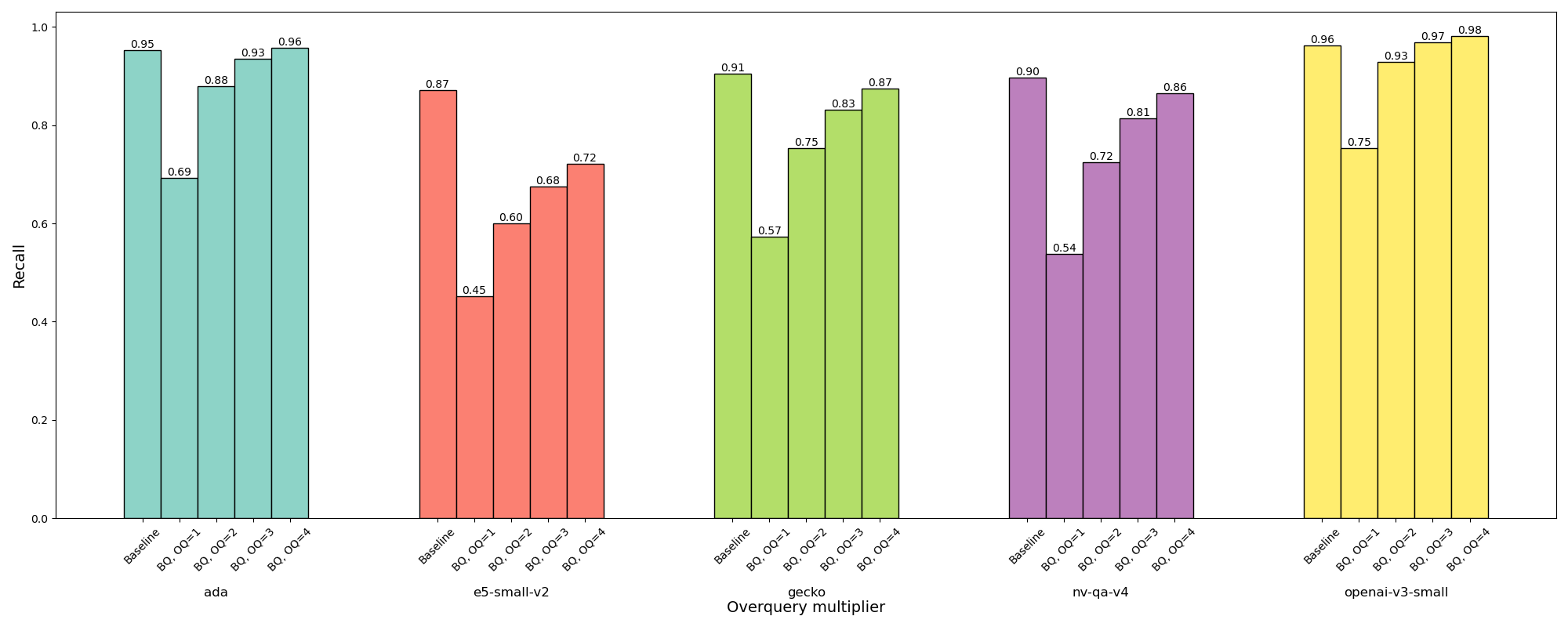
Isso mostra as limitações do BQ:
Assim, o único modelo que o Astra compacta com o BQ por padrão é o ada-002, e ele precisa de uma consulta excessiva de 4x para corresponder ao recall não compactado.
Mas as comparações do BQ são realmente rápidas, a ponto de serem quase insignificantes no custo de pesquisa. Portanto, não valeria a pena aumentar um pouco mais a consulta excessiva para modelos que retêm quase tanta precisão com o BQ, como o Gecko (o modelo de incorporação do Google Vertex)?
O problema é que quanto mais consultas excessivas você precisar fazer para compensar a precisão perdida com a compactação, mais trabalho será necessário na fase de reclassificação, e isso se torna o fator dominante. Aqui estão os números do Gecko com PQ comprimindo a mesma quantidade que BQ (32x) e alcançando quase o mesmo recall (o recall de BQ é um pouco pior: 0,90 vs 0,92):
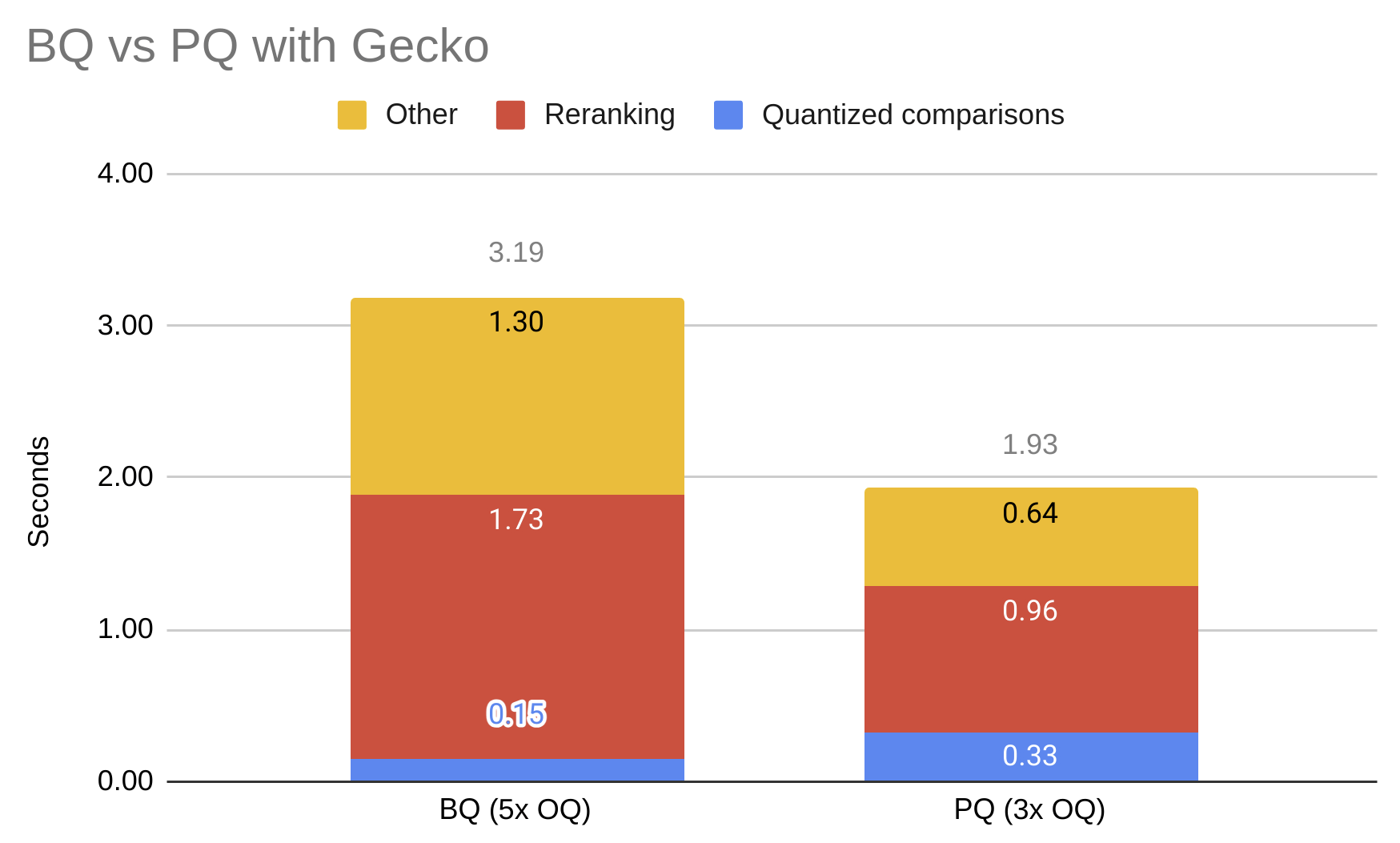
Para 20.000 pesquisas, o BQ avaliou 131 milhões de nós, enquanto o PQ atingiu 86 milhões. Isto é esperado, pois o número de nós avaliados em uma busca de RNA é quase linear em relação ao tamanho do conjunto de resultados solicitado.
Como consequência, embora a similaridade aproximada BQ central seja quase 4x mais rápida que a similaridade aproximada PQ, o tempo total de pesquisa é 50% maior, porque perde mais tempo na reclassificação e no restante da sobrecarga de pesquisa (carregamento de listas de vizinhos, rastreamento do conjunto visitado, etc.).
Durante o último ano de trabalho nesta área, passei a acreditar que a quantização do produto é a solução rápida para a compressão vetorial. É um algoritmo simples e já existe há muito tempo, mas é quase impossível superá-lo de forma consistente em um amplo conjunto de casos de uso porque sua combinação de velocidade e precisão é quase excessivamente boa.
Concluirei explicando como a compactação vetorial se relaciona com o ColBERT, uma técnica de nível superior que os clientes do Astra DB estão começando a usar com sucesso.
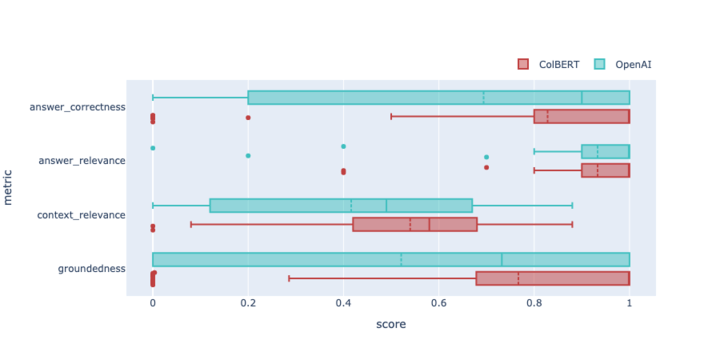
A recuperação usando um único vetor é chamada de recuperação de passagem densa (DPR), porque uma passagem inteira (dezenas a centenas de tokens) é codificada como um único vetor. Em vez disso, ColBERT codifica um vetor por token, onde cada vetor é influenciado pelo contexto circundante. Isto leva a resultados significativamente melhores; por exemplo, aqui está o ColBERT rodando no Astra DB em comparação com o DPR usando vetores openai-v3-small, em comparação com o TruLens para o conjunto de dados Braintrust Coda Help Desk. ColBERT supera facilmente o DPR em correção, relevância de contexto e fundamentação.
O desafio do ColBERT é que ele gera muito mais dados vetoriais do que o DPR. Embora o projeto ColBERT venha com sua própria compactação de índice especializada, ele sofre de fraquezas semelhantes a outros índices baseados em partição; em particular, ele não pode ser construído de forma incremental, portanto, é adequado apenas para conjuntos de dados estáticos conhecidos antecipadamente.
Felizmente, é simples implementar a recuperação e classificação ColBERT no Astra DB. Veja como compressão vs. recall parece com os vetores BERT gerados pelo ColBERT:
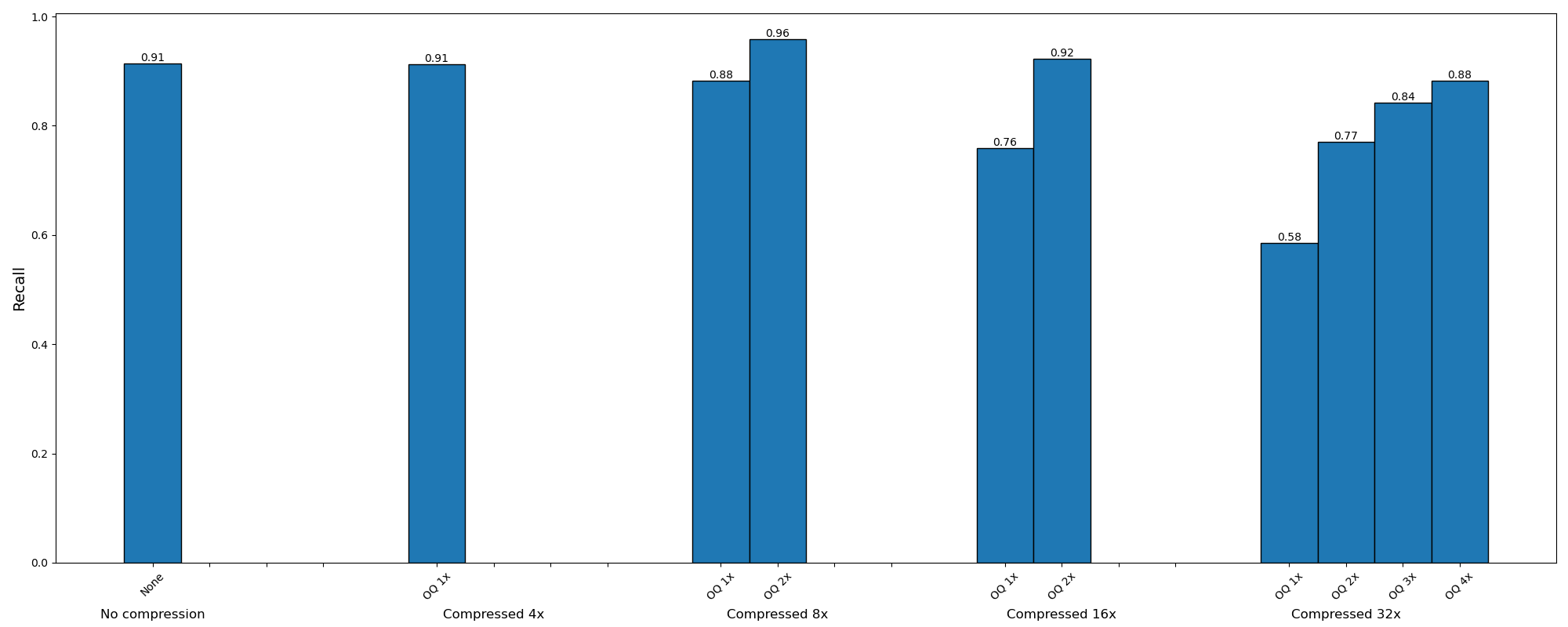
O ponto ideal para esses vetores é PQ com compactação de 16x e consulta excessiva de 2x; 32x PQ e BQ perdem muita precisão.
A quantização do produto permite que o Astra DB atenda grandes índices ColBERT com resultados precisos e rápidos.
O suporte a índices maiores que a memória para o banco de dados em nuvem multilocatário do Astra DB era uma oferta padrão do JVector. Mais recentemente, a equipe JVector tem trabalhado na validação e implementação de melhorias que vão além da compactação e reclassificação básica do estilo DiskANN. Alguns deles incluem:
Atualmente, o JVector capacita a pesquisa vetorial para o banco de dados vetorial Astra DB, Apache Cassandra e Upstash, com mais a caminho. O Astra DB incorpora de forma constante e invisível as mais recentes melhorias do JVector; experimente hoje.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER



{kind=link}
{kind=link}
{kind=link}