Um projeto para tornar o Kafka mais fácil de instalar em sistemas Kubernetes foi adotado pelo Cloud Native Computing Foundation Technical Oversight Committee (TOC) como um projeto de incubação.
Logotipo Strimzi
Strimzi fornece um conjunto de operadores para instalar e executar a plataforma de processamento de eventos Kafka em clusters Kubernetes, acumulando assim todos os benefícios dos pontos fortes do K8s na implantação dinâmica.
“Com Strimzi fazendo parte da Incubadora CNCF, estou realmente otimista de que podemos ampliar a base de usuários, a base de contribuidores e também os mantenedores como resultado do progresso que estamos anunciando hoje”, disse Tom Bentley, fundador e mantenedor do projeto Strimzi, em comunicado.
“Executar um cluster Apache Kafka no Kubernetes não é fácil, mas desde o seu início, Strimzi tem atuado como um divisor de águas nesta área”, elaborou ainda Paolo Patierno, fundador e mantenedor do projeto Strimzi, em comunicado. “A oportunidade de lidar com a carga de operações do dia 2, aproveitando uma abordagem baseada no operador, juntamente com a natureza declarativa do Kubernetes usando recursos personalizados, foi muito bem recebida.”
Como executar o Kafka no Kubernetes
Originalmente desenvolvido no LinkedIn, o Apache Kafka está rapidamente se tornando a plataforma de fato para sistemas orientados a eventos escalonáveis horizontalmente, muitas vezes executando operações de dados em tempo real.
Em teoria, faria sentido executar o Kafka no Kubernetes, mas isso provou ser muito complicado na prática até agora.
“Implantar cargas de trabalho Kafka no Kubernetes não é tão simples, em geral, porque você precisará configurar e executar os corretores Kafka. E quando você precisa mudar alguma coisa nas corretoras, como alguns parâmetros de configuração, você tem que começar a rolar todas as corretoras uma por uma”, disse Patierno, em entrevista ao TNS. Ele também observou que o software que gerencia metadados – originalmente Zookeeper, embora Kafka esteja migrando para o KRaft mais ágil – também deve ser gerenciado.
Strimzi não está sozinho no apoio a Kafka para Kubernetes. O Confluent possui um plug-in comercial para executar o Kafka no Kubernetes.
E do laboratório de incubação da Cisco, existe o KOperator, que se autodenomina “Mais um operador Apache Kafka para Kubernetes”. Este também evita conjuntos com estado, usando Pods, ConfigMaps e PersistentVolumeClaims.
Strimzi adota uma abordagem diferente, explicou Patierno, pois permite definir seu cluster em termos de uma definição de recurso personalizada (CRD) que “estende a API Kubernetes para fornecer uma maneira nativa de interagir com Kafka”, disse Patierno. . O CRD descreve a configuração, o armazenamento, o número de corretores necessários e outros aspectos. O CRD pode então implantar o cluster necessário. Altere um parâmetro e o CRD fará uma atualização.
De onde veio Strimzi?
A Red Hat lançou o Strimzi pela primeira vez em 2017, para a distribuição OpenShift Kubernetes da empresa, como a contraparte de código aberto do AMQ Streams. O padrão Operator, criado pelo CoreOS, forneceu a estrutura. CNCF assumiu isso como um projeto sandbox em 2019.
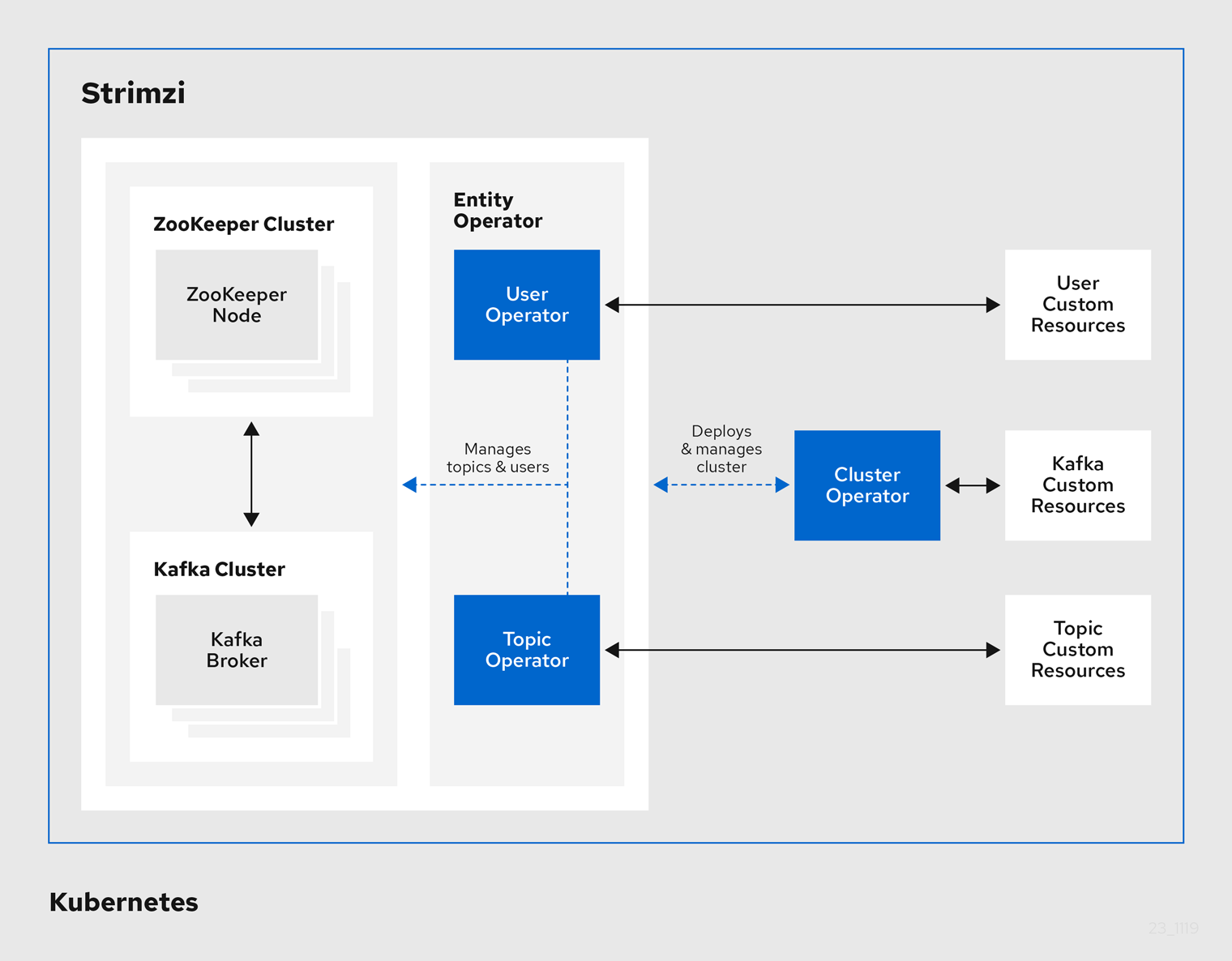
Strimzi é composto por três operadores:
O Operador de Cluster implanta o cluster Apache Kafka iniciando os brokers com a configuração desejada, entre outras funções.
O operador de tópico cria, atualiza e exclui tópicos, em nome dos usuários, usando um recurso personalizado KafkaTopic.
O operador do usuário fornece aos usuários do cluster a definição de permissões por meio de ACLs e recursos personalizados do KafkaUser.
O pacote Strimzi também inclui componentes para o protocolo OAuth 2.0 e um endpoint baseado em HTTP para interagir e configurar um cluster Kafka.
Quem usa Strimzi
Hoje, o projeto conta com mais de 1.600 colaboradores de mais de 180 organizações. Está sendo utilizado em pelo menos 15 ambientes de produção (divulgados publicamente), como Axual, Decathlon e SBB, entre outros.
Atruvia, o braço de serviços de TI do Grupo Financeiro Cooperativo Alemão, utiliza o Strimzi há quatro anos para administrar o Kafka em nome de 150 equipes, com uma equipe de suporte de apenas dois membros e meio. O design nativo da nuvem se adapta bem à arquitetura da empresa, e Strimzi permite que a equipe se mantenha atualizada com os últimos lançamentos do Kafka, de acordo com um comunicado da empresa.
O fornecedor de equipamentos esportivos Decathlon usa Strimzi para melhorar os prazos de entrega da empresa. “Ele atende à nossa necessidade de conectar um grande número de sistemas de dados com um alto nível de escalabilidade, segurança e confiabilidade”, disse um porta-voz em comunicado.
Colt McNealy, que é o líder da equipe técnica do provedor de microsserviços baseado em Kafka, LittleHorse, testemunhou que Strimzi o ajudou a começar com Kafka quando ele sabia pouco sobre como gerenciar um cluster.
“Ao executar o Kafka em produção, lidar com balanceamento, dimensionamento e monitoramento de cluster é uma tarefa difícil, mas a integração nativa do Cruise Control com o CRD KafkaRebalance e os exemplos de configurações de métricas fornecidas (Grafana + Prometheus) tornaram isso possível para mim como Kafka novato para preparar algo para produção”, disse McNealy, em comunicado.
O provedor de serviços em nuvem Portworx comentou quanto trabalho foi feito em Striumzi. “O projeto passou um tempo considerável lutando para ir além do estágio beta, então muitos desenvolvedores ainda estão receosos de usá-lo na produção”, escreveu o gerente de marketing técnico da Portworx, Ryan Wallner, em uma postagem no blog que elogiou o progresso que o projeto tem. feito desde aqueles primeiros dias.
Até agora, Strimzi acumulou mais de 4.200 estrelas no GitHub e foi integrado a outros projetos CNCF, incluindo Prometheus, OpenTelemetry, Helm e outros.
O projeto terá sua primeira conferência virtual de usuários, StrimziCon, em 22 de maio.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Joab Jackson é editor sênior do The New Stack, cobrindo computação nativa em nuvem e operações de sistema. Ele faz reportagens sobre infraestrutura e desenvolvimento de TI há mais de 25 anos, incluindo passagens pela IDG e pela Government Computer News. Antes disso, ele…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.







{kind=link}
{kind=link}
{kind=link}