Nesta postagem, veremos um exemplo real de uso do ChatGPT para desenvolver iterativamente uma função Postgres que suprime a exibição de colunas primárias duplicadas. Ao longo do caminho, exploraremos conceitos úteis de SQL, como funções de janela e SETOF JSON (do Postgres), e veremos como um assistente de IA pode ajudá-lo a aprender em momentos de necessidade.
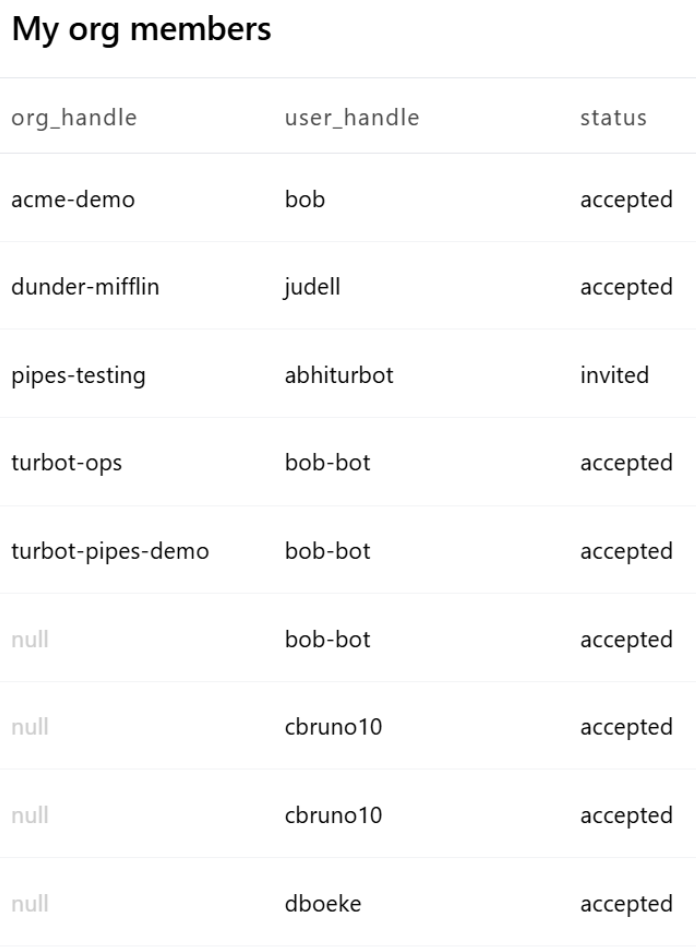
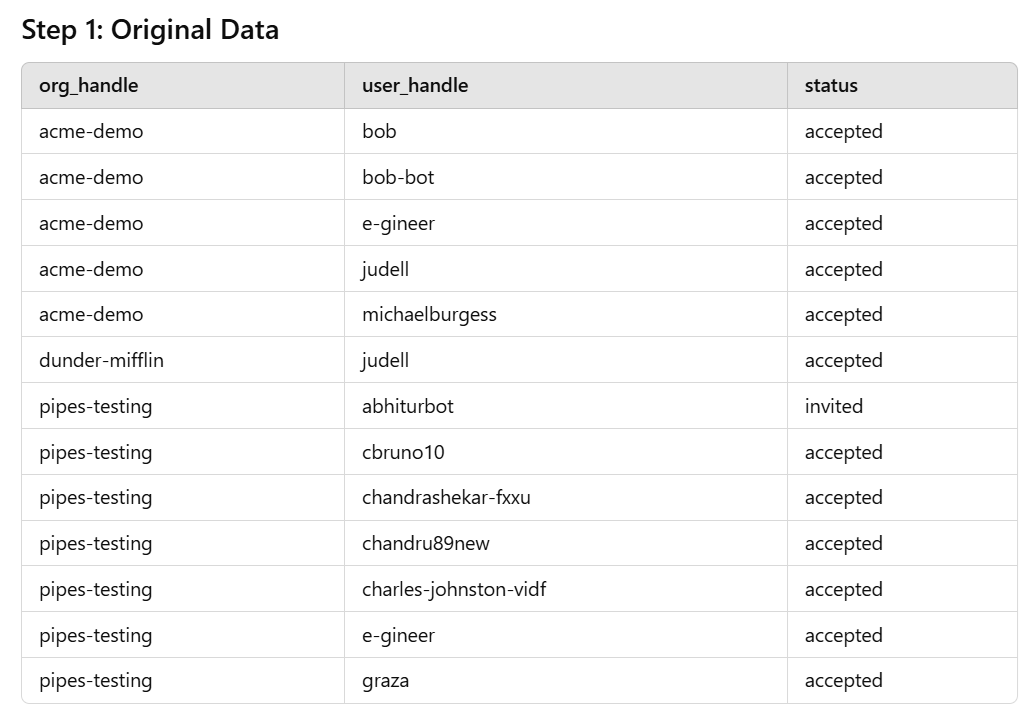
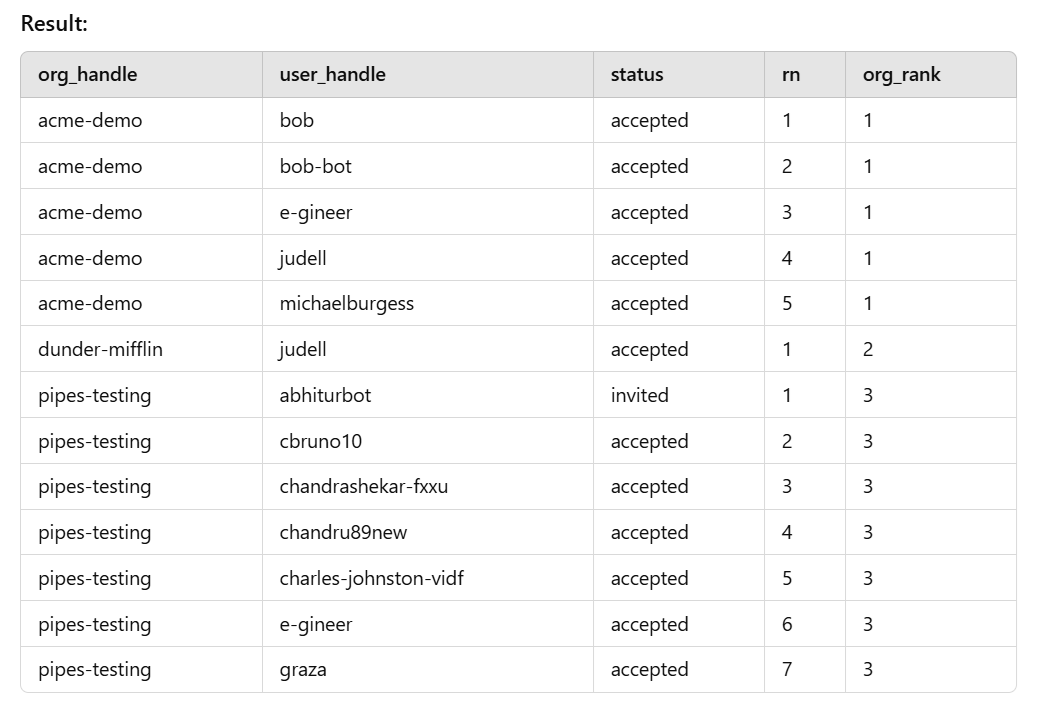
Logo depois que comecei a criar painéis para monitorar meus recursos do Pipes, me deparei com um desafio familiar. Uma consulta SQL produziu resultados como os mostrados no exemplo v1, mas prefiro vê-los da maneira v2.
O painel v2 reduz a confusão visual e exibe rapidamente o número de itens em cada partição primária. Eu sabia que tinha usado o atraso() função para fazer esse tipo de coisa antes, mas já fazia um tempo que eu não usava nenhuma função de janela do SQL, então, quando pedi uma solução ao ChatGPT, não mencionei atraso() para ver o que mais ele poderia propor.
Houve alguns falsos começos ao longo do caminho e foi complicado fazer com que a ordem acontecesse corretamente. Mas iteramos na velocidade da luz porque não precisei descrever tentativas fracassadas, eu poderia apenas mostrá-las enviando capturas de tela como esta.
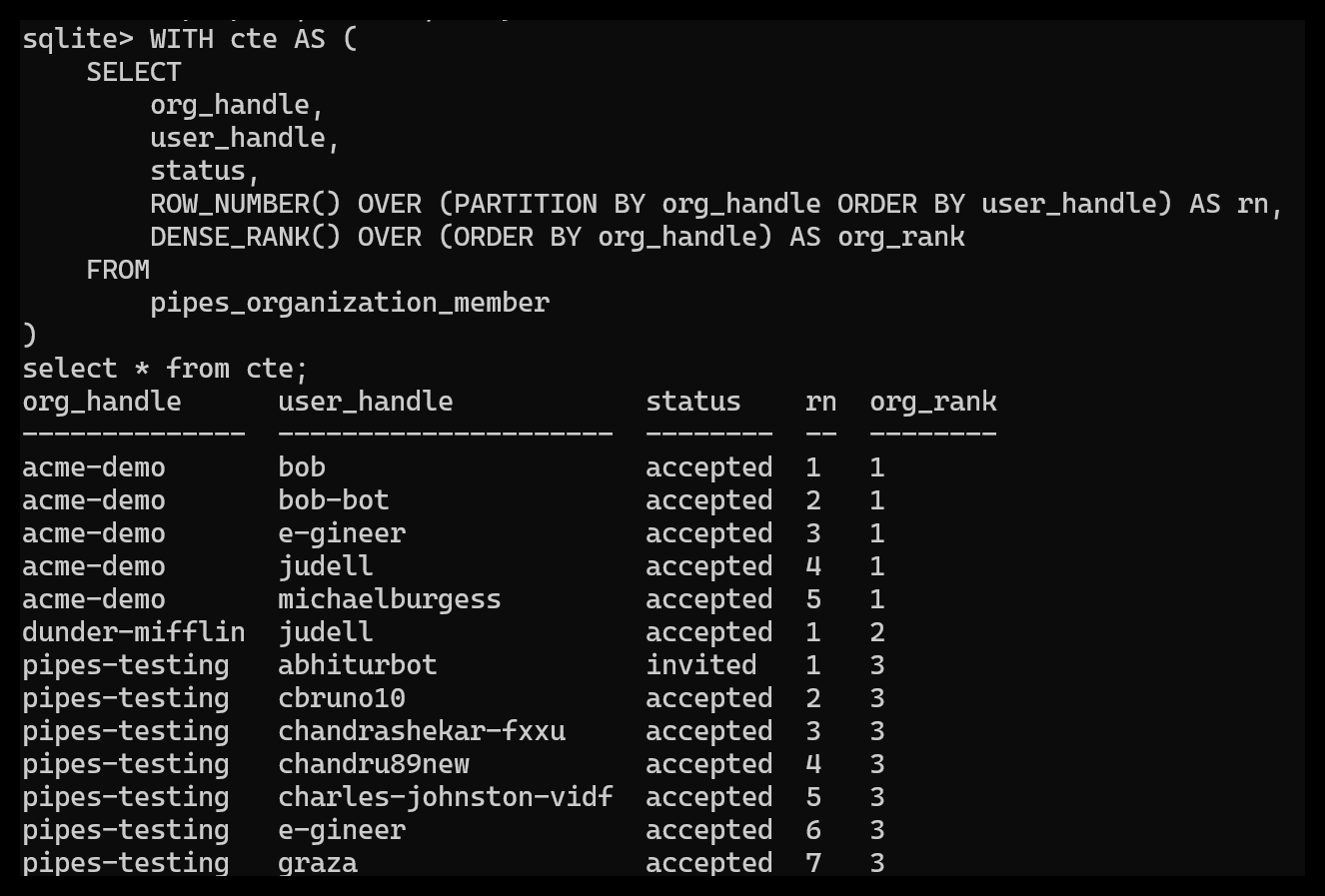
Aqui estava o resultado dessa iteração. E com certeza, em vez de atraso()ChatGPT optou pelo classificação_densa() função.
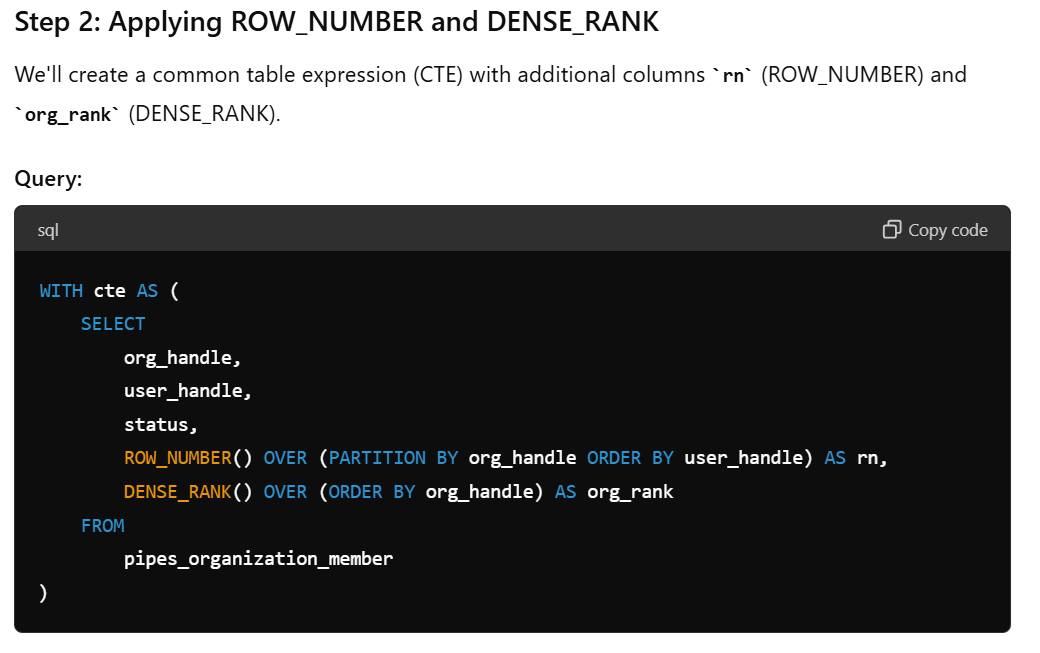
Explorando a função da janela Dense_rank()
Eu nunca tinha ouvido falar, muito menos usado, classificação_densa(). Então agora eu queria aprender sobre isso. Para mim, é sempre difícil visualizar coisas como funções de janela. Ajuda trabalhar com exemplos passo a passo e examinar as etapas intermediárias e seus valores. Aqui está a visualização que o ChatGPT produziu:
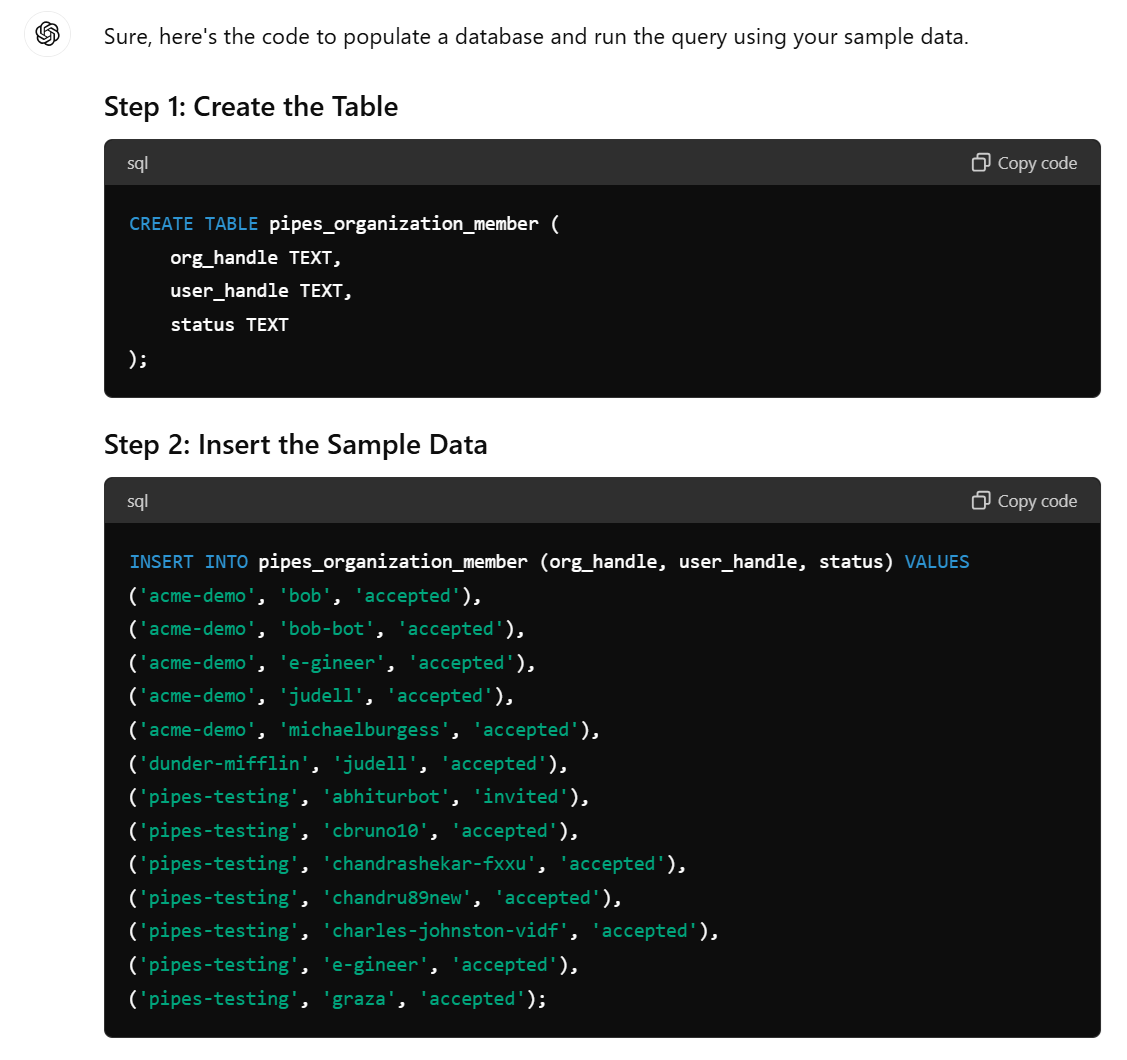
Para fazer isso, ele executa Python com SQLite em uma sandbox. Para replicar, você pode solicitar o código de configuração.
Em seguida, execute você mesmo no SQLite.
Observe que nunca carreguei esses dados de amostra em nenhum formato textual, apenas os carreguei capturas de tela De dados. Como vimos da última vez, a distinção entre formatos de dados textuais e imagens dos mesmos dados está rapidamente (e deliciosamente) desgastada.
Aqui está uma explicação típica de classificação_densa():
“A função DENSE_RANK() em SQL atribui uma classificação exclusiva a cada valor distinto em uma partição, sem lacunas entre os números de classificação, mesmo se houver empates.”
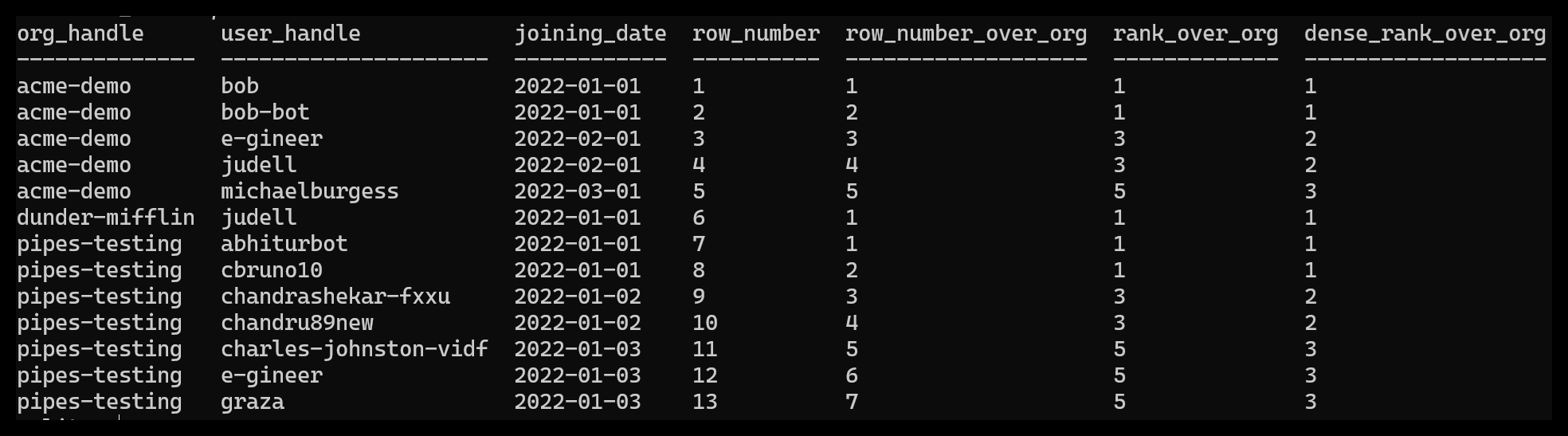
Queria ver um exemplo que ilustrasse os laços, e neste caso os dados não incluíam uma forma natural de fazer isso, então pedi ao ChatGPT que inventasse uma coluna para esse fim e aqui está a visualização que obtive.
Se isso é um exagero para você, ótimo, parabéns, você tem sorte. Alguns de nós, porém, precisam de mais andaimes, e quando podemos convocá-los à existência sem esforço – com base nos dados reais com os quais estamos trabalhando – é uma grande vitória.
E quanto à função da janela lag()?
Nesse ponto, levantei a alternativa que havia retido intencionalmente: “E quanto ao atraso() função?” Perguntei. “Acho que já usei isso no passado para fazer esse tipo de coisa de maneira mais simples.”
“Claro”, disse ChatGPT, sempre ansioso para agradar. “Aqui está uma versão que usa o atraso() função.” Como antes, suas primeiras tentativas atrapalharam a ordenação das colunas secundárias. Eu me esforcei um pouco para dizer ao ChatGPT exatamente o que eu queria dizer com “bagunçado”, mas não precisei explicar com palavras porque poderia capturar capturas de tela e explicar com imagens. Além disso, como o ChatGPT estava trabalhando com os mesmos dados de amostra de antes, eu poderia pedir que ele se referisse aos resultados anteriores. Eventualmente, convergiu para uma solução que correspondia aos resultados anteriores.
Em seguida, discutimos os méritos relativos das duas abordagens. Minha conclusão foi que enquanto classificação_densa() é mais versátil para particionamento e ordenação complexos, atraso() provavelmente foi suficiente para minhas necessidades.
O que é mais fácil de visualizar? Eu fui e voltei sobre isso e, depois de comparar as visualizações geradas pelo ChatGPT de ambos os métodos, decidi que era um fracasso.
Escrevendo uma função Postgres para abstrair o padrão
À medida que adicionei novos painéis, precisei aplicar o mesmo método a diferentes tabelas e diferentes conjuntos de colunas. Nessa situação, sempre fico tentado a escrever uma função Postgres para encapsular o comportamento comum. Mas também aprendi a pisar no freio e resistir a essa tentação porque a programação dinâmica no Postgres é complicada.
Historicamente, o custo de escrever a função poderia facilmente superar o benefício de escrevê-la. Mas isso foi antes de eu ter um assistente de LLM para me ajudar a escrever a função! Portanto, agora era um bom momento para rever essa equação custo/benefício.
Com ou sem ajuda, você precisa agir com cuidado. A versão que eu queria funcionaria com qualquer tabela, com qualquer coluna primária e com um número arbitrário de colunas secundárias. Mas tentar fazer tudo isso de uma vez é uma receita para o desastre. Então comecei solicitando uma função que simplesmente codificasse que tudo na consulta já estava funcionando.
Isso ainda requer alguma iteração. Você está escrevendo uma função Postgres que usa parâmetros de string, constrói uma consulta SQL que incorpora esses parâmetros – que podem ser identificadores Postgres ou strings simples – e então executa essa consulta. Na minha experiência, a função resultante provavelmente não funcionará na primeira vez; e de fato não aconteceu.
Minha estratégia usual tem sido escrever uma versão de depuração da função que apenas retorne a consulta gerada. Você pode então executar essa consulta manualmente ou, se ela não funcionar, identificar rapidamente onde a construção da consulta SQL a partir de suas diversas entradas deu errado.
Felizmente, nem precisei sugerir essa estratégia porque ChatGPT se ofereceu para depurar versões da função. Se você já conhece a estratégia, isso poupa o esforço de implementá-la. Mas pode não ter ocorrido a você! Nesse caso, você experimentará o tipo de aprendizagem ambiente que os LLMs podem permitir.
Procedendo desta forma, chegamos a uma função que foi devidamente parametrizada pelo nome da tabela, pela coluna primária e por um par de colunas secundárias; e validamos que funcionou para dois casos que compartilhavam esse padrão.
Generalizando a Função
Tenho certeza de que você pode adivinhar o que veio a seguir: um caso que exigia um número diferente de colunas. Agora a função precisaria receber e processar uma lista de nomes de colunas. Esse é o tipo de coisa que sei que é possível, mas seria difícil para mim resolver sozinho. Não foi rápido e fácil para nós dois, mas chegamos lá. A versão final da função incorpora todos os graus de liberdade que originalmente imaginei.
O resultado final proporcionou mais um pouco de aprendizado ambiental. eu sabia que um pl/pgsql A função pode retornar TABLE ou SETOF RECORD, ambos exigindo digitação forte, o que torna difícil lidar com listas de parâmetros arbitrários. Tropeçamos nessa limitação por um tempo, então o ChatGPT surgiu com o RETURNS SETOF JSON, que foi uma bela solução. Você pode ver exemplos de uso da função aqui.
Estou tentado a dizer que SETOF JSON, como classificação_densa, foi novidade para mim, e isso pode ser verdade, mas há uma possibilidade mais intrigante. Talvez eu tenha lido sobre um ou ambos esses idiomas em algum momento, mas não em um momento de aprendizado como este, então o conhecimento não pegou. Quando os LLMs revelam expressões idiomáticas de programação no momento de necessidade, é muito mais provável que você se lembre delas.
As gotas de um centavo
Foi só depois de implantar a função e usá-la em três painéis diferentes que a ficha finalmente caiu. Isso começou como um exercício para envolver um idioma SQL que fazia uso do atraso() função. Mas quando olhei para a versão final da função, percebi que ela não estava usando atraso(). Nem estava usando classificação_densa(). Apenas número_linha() com lógica de partição foi suficiente. Por que, perguntei ao ChatGPT, isso não era inicialmente óbvio?
Bate-papoGPT: A solução final usando ROW_NUMBER() e lógica de partição não foi imediatamente aparente devido a uma combinação de confiança em padrões familiares, à evolução da compreensão dos requisitos e à natureza iterativa da resolução de problemas. Este processo destaca a importância da flexibilidade e da abertura para reavaliar as abordagens iniciais para encontrar a solução mais simples e eficaz.
É uma boa resposta que sintetiza a sabedoria extraída das mentes humanas representadas no corpus de consultas SQL e conversas relacionadas das quais o ChatGPT se alimenta.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Jon Udell é autor, arquiteto de informação, desenvolvedor de software e inovador de novas mídias. Seu livro de 1999, Practical Internet Groupware, ajudou a estabelecer as bases para o que hoje chamamos de software social. Ele foi desenvolvedor de software na Lotus; Revista BYTE…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.






{kind=link}
{kind=link}
{kind=link}