
Britive: acesso just-in-time em múltiplas nuvens
24 de janeiro de 2024
Kubernetes evolui de apostas de ‘distro’ para escolha em escala
24 de janeiro de 2024
O Kubernetes tem uma reputação bastante assustadora de complexidade por si só (como já discutimos antes). Aprendendo pela primeira vez e configurando seu primeiro cluster, implantando sua primeira pilha de aplicativos… pode ser doloroso.
Mas, como qualquer operador experiente lhe dirá, é quando você expande a execução do Kubernetes em produção em escala que você se depara com o verdadeiro problema!

Vamos nos aprofundar em três das “dores de crescimento” mais comuns que vimos na área:
- Produtividade do desenvolvedor
- Dores de cabeça em múltiplas salvas
- A curva de aprendizado de ponta
Não apenas exploraremos a dor, mas também mostraremos maneiras de evitar essas armadilhas.
![]()
Spectro Cloud permite exclusivamente que as organizações gerenciem Kubernetes em produção, em escala. Nossa plataforma de gerenciamento Palette oferece controle fácil de todo o ciclo de vida do Kubernetes, em nuvens, data centers, ambientes bare metal e edge.
Saber mais
As últimas novidades do Spectro Cloud
$(document).ready(function() { $.ajax({ método: ‘POST’, url: ‘/no-cache/sponsors-rss-block/’, headers: { ‘Cache-Control’: ‘no- cache, no-store, must-revalidate’, ‘Pragma’: ‘no-cache’, ‘Expires’: ‘0’ }, dados: { patrocinadorSlug: ‘spectro-cloud’, numItems: 3 }, sucesso: function( dados) { if (data.startsWith(‘ERROR’)) { console.log(data); $(‘.sponsor-note-rss’).hide(); } else { $(‘.sponsor-note-rss -items-spectro-cloud’).html(dados); } } }); });
Dor 1: Produtividade do desenvolvedor
A infraestrutura não existe por si só. Como uma equipe de operações, os clusters que você cria existem para fornecer entrega de aplicativos para as equipes de desenvolvimento que você oferece suporte.
Apesar da popularidade do termo “DevOps”, a maioria dos desenvolvedores não possui as habilidades necessárias para serem especialistas em infraestrutura nativa de nuvem ou Kubernetes. Eles prefeririam ser recursos de codificação do que gerenciar infraestrutura (como exploramos nesta postagem do blog).
Os desenvolvedores desejam apenas consumir elementos de infraestrutura, como clusters Kubernetes, e têm pouca tolerância a atrasos e obstáculos em seu caminho. Infelizmente, nem sempre é fácil dar-lhes o que desejam.
Vejamos um exemplo simples: executar um conjunto de testes em uma nova versão do código do aplicativo.
O desenvolvedor deseja um cluster limpo e puro – possivelmente vários clusters, executando versões específicas do Kubernetes e outros softwares. Isso é vital para que eles obtenham testes precisos que prevejam o comportamento da produção. Todos sabemos que é impossível espelhar uma configuração de infraestrutura de produção em um laptop local, por mais tentador que seja.
Se um teste falhar por um motivo simples, o desenvolvedor pode querer repetir o pipeline de CI/CD quase imediatamente.
Mas você sabe que não é tão fácil.
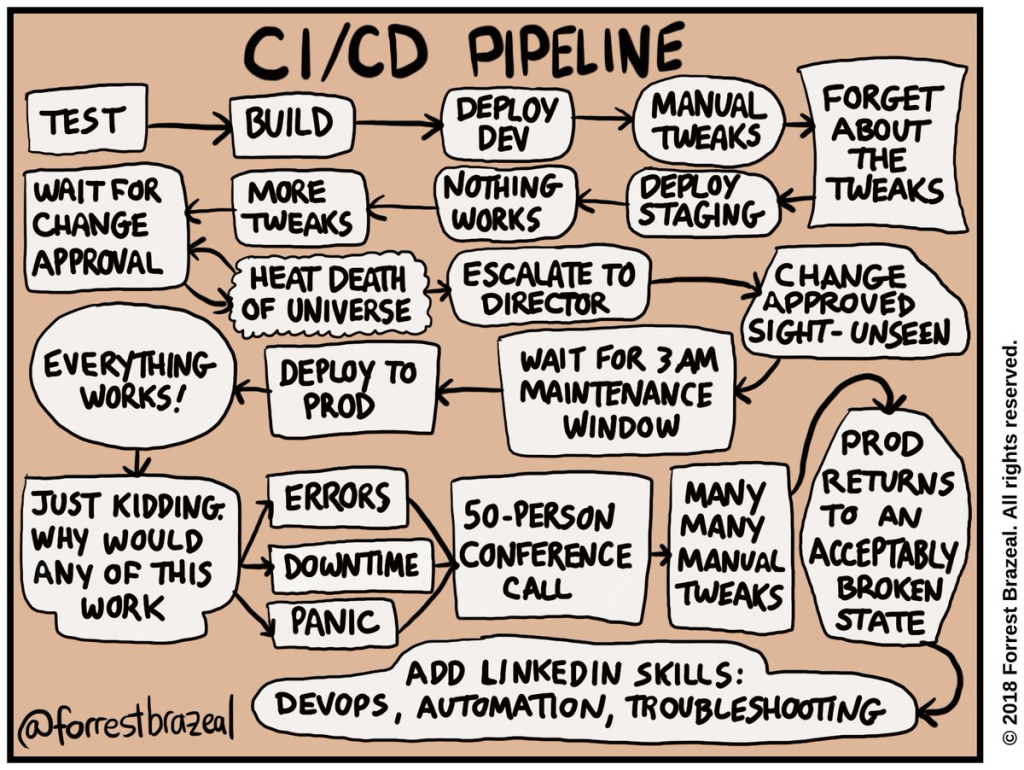
Iniciar um novo cluster dá trabalho, custa dinheiro e, mesmo que você tenha a capacidade de atender imediatamente à solicitação, também leva tempo. O que significa que seus desenvolvedores ficam esperando.
Este é um verdadeiro enigma. Agora imagine isso acontecendo em dezenas de equipes de desenvolvimento que enviam vários pipelines de código por dia.
Dando aos desenvolvedores o que eles precisam com clusters virtuais
Então, como você lida com isso? Uma resposta são clusters virtuais. Em uma configuração de cluster virtual, a equipe de infraestrutura mantém os clusters de host estáveis e sob controle total, ao mesmo tempo que fornece clusters virtuais aos desenvolvedores. Os clusters virtuais são isolados, apresentando risco zero para a infraestrutura subjacente, e quase não levam tempo ou recursos para serem ativados, o que significa que você pode dar a cada equipe seus próprios clusters para brincar.
Esta solução é baseada no projeto vcluster de código aberto, mas na Spectro Cloud tornamos essa tecnologia pronta para empresas e fácil de consumir. Ou seja, adicionamos uma UI elegante, implementamos uma abordagem totalmente declarativa com Cluster API nos bastidores, conectamos tudo isso a controles de acesso baseados em funções e apresentamos isso como uma solução SaaS fácil de consumir.
Usando o Palette, os desenvolvedores podem solicitar seus próprios clusters criados especificamente para eles com base em perfis de cluster, definidos pelo grupo de infraestrutura. Cada equipe pode ter seu próprio playground. É claro que todo o processo pode ser totalmente automatizado usando o provedor Terraform ou chamadas de API REST. Com essa abordagem, o controle granular permanece nas mãos da equipe de infraestrutura, mas os desenvolvedores agora têm a liberdade e a capacidade de testar seu código em condições semelhantes às de um produto.
Dor 2: dores de cabeça em múltiplos grupos
Todo mundo começa com um cluster Kubernetes. Mas poucas equipes hoje permanecem assim.
Esse número cresce rapidamente para três quando você divide clusters de ambiente de desenvolvimento, preparação e produção.
E a partir daí? Bem, nossa pesquisa descobriu que metade das pessoas que usam Kubernetes em produção já tem mais de 10 clusters. Oitenta por cento esperam aumentar o número ou tamanho dos seus clusters no próximo ano.
Provavelmente você pode gerenciar alguns clusters manualmente usando kubectl, k9s e outras ferramentas de código aberto. Mas quando você chega a algumas dúzias de clusters, o gerenciamento do Kubernetes se torna uma tarefa árdua.
Como podemos resolver este problema?
O princípio fundamental do gerenciamento de multiclusters: você não deve usar o kubectl manualmente e conectar-se aos seus clusters individualmente. Em vez disso, você descreve sua configuração em uma abordagem declarativa.
Essa descrição do “estado futuro” deve abranger todo o cluster, desde sua infraestrutura até as cargas de trabalho de aplicativos executadas no topo. Em outras palavras, você poderá recriar toda a pilha de cluster do zero usando apenas sua descrição, sem intervenção manual.
Multicluster, Multicloud, Multiambiente
À medida que você analisa o número crescente de clusters, vale a pena ser independente da nuvem desde o início.
É tentador ficar com apenas um provedor de nuvem pública. É o caminho mais fácil: apenas um conjunto de produtos e terminologia para aprender. E os provedores de nuvem normalmente fazem o possível para prendê-lo, muitas vezes incentivando financeiramente a lealdade.
Mas há muitos motivos pelos quais você pode se encontrar em um ambiente multicloud. Fusões e aquisições às vezes trazem inesperadamente outro fornecedor para dentro da empresa. Talvez você queira usar várias nuvens para acessar recursos específicos ou para distribuir riscos e melhorar a disponibilidade.
Várias empresas que vimos também estão usando uma abordagem de arquitetura híbrida para implantar o Kubernetes: alguns aplicativos legados de implantação baseados em data center, juntamente com outros baseados em nuvem.
Sempre que você estiver lidando com diferentes silos do Kubernetes, o que realmente ajuda é um único painel de vidro. Se você estiver usando vários provedores de nuvem ou estiver no local e usando um provedor de nuvem, precisará de ferramentas que permitam fazer implantações semelhantes em vários ambientes. Ajuda a alcançar a padronização e simplifica sua infraestrutura organizacional geral.
Dor 3: A Curva de Aprendizagem Limitada
Do data center e da nuvem, você pode começar a olhar ainda mais longe: até a borda.
As organizações estão cada vez mais adotando a edge computing para colocar as aplicações onde elas agregam valor: em restaurantes, fábricas e outros locais remotos.
Mas a borda apresenta desafios únicos. O hardware geralmente tem baixo consumo de energia: seus clusters podem ser dispositivos de nó único. A conectividade com o site pode ser de baixa largura de banda ou intermitente, dificultando o gerenciamento remoto. Há toda uma nova fronteira de segurança a ser considerada, protegendo contra adulteração de hardware.
E o assassino: quando falamos de cadeias de restaurantes ou edifícios industriais, a computação pode precisar ser implantada em centenas ou milhares de locais. Não haverá um especialista em Kubernetes em cada local — ou mesmo um profissional de TI comum — para ajudar a integrar novos dispositivos ou corrigir quaisquer problemas de configuração localmente.
São grandes desafios, mas existem soluções para ajudá-lo.
As tecnologias de integração com ou sem toque significam que alguém sem conhecimento de TI ou Kubernetes deve ser capaz de pegar um dispositivo, conectar energia e Ethernet e observar o provisionamento ser concluído automaticamente, sem qualquer intervenção humana. (Confira uma demonstração disso aqui.)
Um dos pré-requisitos para esta implantação é a capacidade de provisionar todo o cluster do zero de uma só vez, incluindo o provisionamento do sistema operacional no dispositivo subjacente. Quando você pode fazer esse provisionamento de forma declarativa, isso simplifica significativamente a implantação em grande escala. A ideia aqui é que o provisionamento comece automaticamente e construa o sistema até um ponto em que ele seja capaz de chegar à sede, de onde você gerenciaria a implantação centralmente.
Depois que seu cluster estiver pronto, você poderá mitigar ainda mais os riscos se seu sistema operacional for imutável. Ele tem menos elementos para quebrar, por isso fornece uma base mais confiável para seus clusters. Portanto, preste atenção em qual sistema operacional você está escolhendo. Há uma série de ofertas comerciais e de código aberto disponíveis no mercado. Confira esta comparação para começar.
Enfrentando desafios? Você não está sozinho.
Como equipe de plataforma, você quase certamente enfrentará esses desafios ao dimensionar o Kubernetes na produção. Eles são assustadores, com certeza. Mas existem abordagens que você pode adotar para ter sucesso.
O ecossistema Kubernetes de código aberto e nativo da nuvem é enorme e você sabe que não está sozinho. Existem muitos projetos diferentes que você pode aplicar. E há uma vasta experiência da comunidade que você também pode aproveitar em eventos como o KubeCon.
Mas talvez a maior dica que podemos oferecer seja esta: se você está construindo em escala, não faça você mesmo.
Certamente comece com DIY para aprender e provar o conceito. Mas você deve saber que o caminho do “faça você mesmo” só fica mais difícil com o tempo. Deixamos de precisar “fazer o Kubernetes da maneira mais difícil”.
Então o que vem depois? Se você estiver interessado em se aprofundar nos desafios que pode esperar ver à medida que o uso do Kubernetes cresce, junte-se a mim em nosso webinar em 27 de abril. Cadastre-se aqui!
A postagem Três desafios comuns do Kubernetes e como resolvê-los apareceu pela primeira vez em The New Stack.



{kind=link}
{kind=link}