Este é o segundo de dois artigos sobre incorporações esparsas aprendidas. Não deixe de conferir a edição anterior do BGE-M3, que inclui alguns antecedentes críticos para entender como funciona o modelo SPLADE.
DR
Os bancos de dados vetoriais dependem de vários embeddings para recuperar dados e gerar resultados precisos para os usuários. Os embeddings esparsos aprendidos combinam a capacidade dos embeddings esparsos de combinar palavras-chave com a capacidade dos embeddings densos de potencializar pesquisas semânticas.
Representações de codificador bidirecional de transformadores (ou BERT) é a arquitetura subjacente que alimenta o modelo SPLADE. Abordamos como o BERT cria embeddings a partir de uma string de texto de consulta na última parte.
O que é SPLADE?
O modelo Sparse Lexical and Dense Embeddings (SPLADE) foi projetado para tarefas de recuperação de informações, combinando os pontos fortes de representações lexicais esparsas com embeddings densos.
Antes de chegarmos ao SPLADE, precisamos retornar ao BERT. Existem duas tarefas de pré-treinamento que sustentam o BERT, uma das quais é Masked Language Modeling (MLM). Esse processo oculta aleatoriamente componentes do token e treina o modelo para prever o que melhor caberia ali.
Usamos a consulta a seguir para explicar o BERT e o BGE-M3 e a usaremos novamente aqui para fins de consistência.
Milvus é um banco de dados vetorial construído para pesquisa escalonável de similaridade.
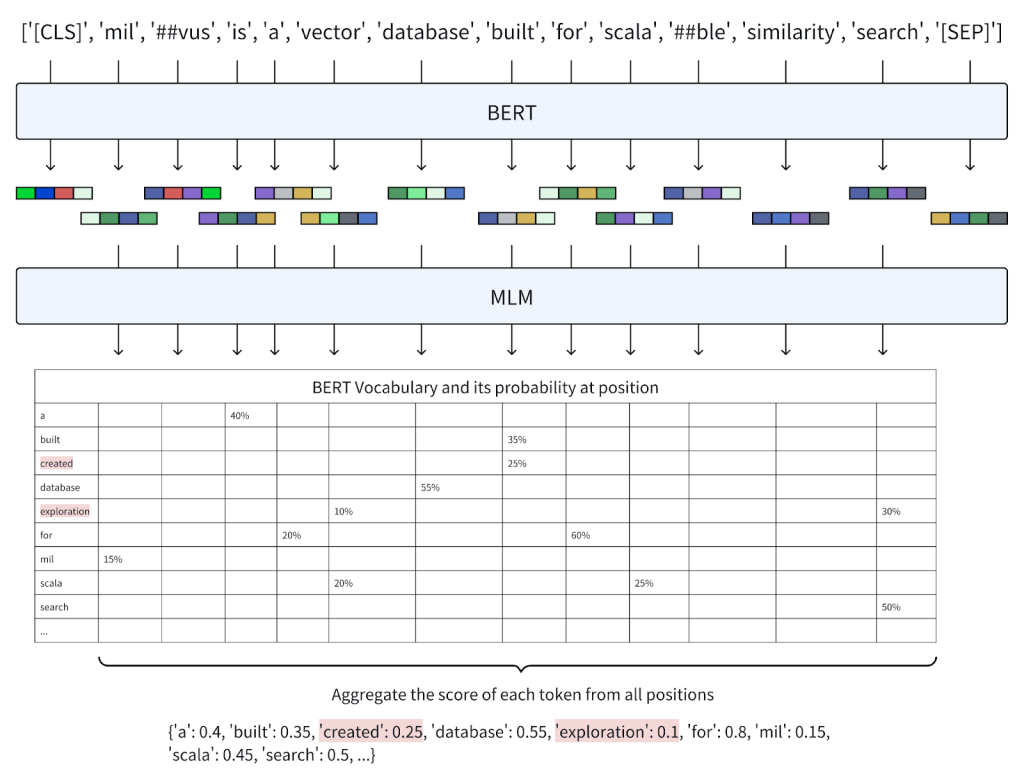
Você pode ver no token gerado abaixo que o MLM mascara dois componentes do token.
Essa técnica resulta em um modelo com compreensão linguística mais profunda e consciência estrutural da linguagem porque depende de tokens adjacentes para substituir os valores mascarados por previsões precisas.
Para cada slot mascarado durante o pré-treinamento, o modelo usa a incorporação contextualizada do BERT (chamamos isso de Q), aqui o representamos como Q(i) para gerar uma distribuição de probabilidade w_icom w_{ij} denotando a probabilidade de um token de vocabulário BERT específico ocupar a posição mascarada. O comprimento deste vetor de saída w_i corresponde ao tamanho do extenso vocabulário do BERT, normalmente 30.522 palavras, e serve como um sinal de aprendizagem chave para refinar as previsões do modelo.
(Nota: As probabilidades são calculadas para fins de demonstração.)
Embora a arquitetura BERT tenha algum MLM integrado, o SPLADE leva essa aplicação de MLM para o próximo nível. A principal diferença é que, uma vez que o BERT gera tokens e embeddings, o SPLADE aplica MLM em todos posições de token, calculando a probabilidade de cada token corresponder a cada palavra do vocabulário do BERT. Ele também usa processamento avançado para determinar uma relevância ponderada para cada palavra do vocabulário do token de entrada, criando um vetor esparso aprendido.
Uma das principais vantagens do uso do SPLADE é que ele identifica termos relevantes que não estavam presentes no texto original. Isso fornece muita flexibilidade e dinamismo para a produção do resultado final, expandindo o vetor para incluir mais tokens. Isso amplia os recursos de correspondência de termos porque os resultados retornados podem conter dados relevantes além do escopo literal da string de consulta original.
SPLADE no mundo real
SPLADE pega embeddings BERT e lhes dá maior resolução e densidade, tornando-os mais úteis para tarefas de busca e recuperação, especialmente aquelas onde o escopo e a relevância do termo são importantes. A seguir estão algumas aplicações do mundo real para o modelo SPLADE.
Otimização e aprimoramento de mecanismos de pesquisa
Melhorando a relevância e a eficiência do mecanismo de pesquisa
Os embeddings esparsos aprendidos gerados pelo SPLADE ajudam os mecanismos de pesquisa a entender melhor as consultas dos usuários e a recuperar documentos que são léxico e semanticamente relevantes.
Benefícios:
Relevância aprimorada: Fornece resultados de pesquisa mais precisos e contextualmente relevantes.
Compreensão aprimorada: Compreende melhor a intenção do usuário, mesmo para consultas complexas ou vagas.
Escalabilidade: Lida com eficiência com conjuntos de dados em grande escala devido às suas representações esparsas.
Satisfação do usuário: Aumenta a satisfação do usuário por meio de resultados de pesquisa mais precisos.
Pesquisa e recomendação de produtos de comércio eletrônico
Pesquisa aprimorada de produtos e recomendações personalizadas
No comércio eletrônico, o SPLADE pode melhorar a funcionalidade de pesquisa em plataformas de varejo online, oferecendo resultados de pesquisa de produtos mais precisos. Ele também pode aprimorar os sistemas de recomendação, compreendendo as nuances das preferências dos usuários por meio de seu histórico de pesquisas e compras. Isso leva a uma melhor descoberta de produtos e experiências de compra personalizadas.
Benefícios:
Melhor correspondência de produtos: Corresponde com precisão as consultas de pesquisa a produtos relevantes.
Personalização: Fornece recomendações personalizadas com base no comportamento e nas preferências do usuário.
Taxas de conversão: Aumenta as taxas de conversão ajudando os clientes a encontrar o que procuram com mais eficiência.
Gestão de inventário: Ajuda no melhor gerenciamento de estoque, entendendo a demanda do produto.
Pesquisa Acadêmica e Científica
Pesquisa aprimorada de literatura e descoberta de conhecimento
Você pode usar o SPLADE para melhorar as pesquisas bibliográficas em pesquisas acadêmicas e científicas. Os pesquisadores muitas vezes precisam encontrar artigos, artigos e dados relevantes em extensas bases de dados acadêmicas. A capacidade do SPLADE de capturar conteúdo léxico e semântico pode fornecer aos pesquisadores resultados de pesquisa mais precisos e abrangentes, facilitando uma melhor descoberta de conhecimento.
Benefícios:
Pesquisa abrangente: Recupera uma gama mais ampla de documentos relevantes, compreendendo questões científicas complexas.
Eficiência de tempo: Economiza o tempo dos pesquisadores fornecendo resultados mais precisos rapidamente.
Pesquisa interdisciplinar: Auxilia na descoberta de conexões entre diferentes campos de estudo.
Qualidade da pesquisa: Melhora a qualidade da pesquisa, garantindo que a literatura crítica e relevante não seja esquecida.
Conclusão
A capacidade do modelo SPLADE de criar embeddings esparsos aprendidos combinando representações lexicais esparsas com embeddings densos o torna excepcionalmente poderoso para tarefas de recuperação de informações.
YOUTUBE.COM/THENEWSTACK
A tecnologia avança rápido, não perca um episódio. Inscreva-se em nosso canal no YouTube para transmitir todos os nossos podcasts, entrevistas, demonstrações e muito mais.
SE INSCREVER
Stephen Batifol é um defensor do desenvolvedor na Zilliz. Anteriormente, ele trabalhou como engenheiro de aprendizado de máquina na Wolt, onde criou e trabalhou na plataforma de ML, e anteriormente como cientista de dados na Brevo. Stephen estudou ciência da computação e…
Este site utiliza cookies para melhorar sua experiência de navegação. Ao continuar, você concorda com o uso de cookies. Para mais informações, consulte nossa Política de Privacidade.
Funcional
Sempre ativo
O armazenamento ou acesso técnico é estritamente necessário para a finalidade legítima de permitir a utilização de um serviço específico explicitamente solicitado pelo assinante ou utilizador, ou com a finalidade exclusiva de efetuar a transmissão de uma comunicação através de uma rede de comunicações eletrónicas.
Preferências
O armazenamento ou acesso técnico é necessário para o propósito legítimo de armazenar preferências que não são solicitadas pelo assinante ou usuário.
Estatísticas
O armazenamento ou acesso técnico que é usado exclusivamente para fins estatísticos.O armazenamento técnico ou acesso que é usado exclusivamente para fins estatísticos anônimos. Sem uma intimação, conformidade voluntária por parte de seu provedor de serviços de Internet ou registros adicionais de terceiros, as informações armazenadas ou recuperadas apenas para esse fim geralmente não podem ser usadas para identificá-lo.
Marketing
O armazenamento ou acesso técnico é necessário para criar perfis de usuário para enviar publicidade ou para rastrear o usuário em um site ou em vários sites para fins de marketing semelhantes.







{kind=link}
{kind=link}
{kind=link}